Mindspore框架循环神经网络RNN模型实现情感分类|(三)RNN模型构建
Mindspore框架循环神经网络RNN模型实现情感分类
Mindspore框架循环神经网络RNN模型实现情感分类|(一)IMDB影评数据集准备
Mindspore框架循环神经网络RNN模型实现情感分类|(二)预训练词向量
Mindspore框架循环神经网络RNN模型实现情感分类|(三)RNN模型构建
Mindspore框架循环神经网络RNN模型实现情感分类|(四)损失函数与优化器
Mindspore框架循环神经网络RNN模型实现情感分类|(五)模型训练
Mindspore框架循环神经网络RNN模型实现情感分类|(六)模型加载和推理(情感分类模型资源下载)
Mindspore框架循环神经网络RNN模型实现情感分类|(七)模型导出ONNX与应用部署
tips:安装依赖库
pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
pip install tqdm requests
一、RNN模型构建
数据集准备完成了输入文本通过查字典(序列化)的向量化。并使用nn.Embedding层加载了Glove词向量。下一步将使用RNN循环神经网络做特征提取,最后将RNN连接至全连接网络nn.Dednse,将特征转化为分类。
nn.Embedding -> nn.RNN -> nn.Dense
本项目,采用规避RNN梯度消的变种LSTM(Long short-term memory)代替RNN做特征提取层。
1.1 关于RNN
循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的神经网络。下图为RNN的一般结构:
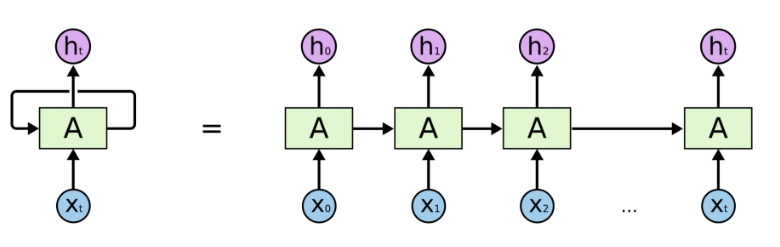
图示左侧为一个RNN Cell循环,右侧为RNN的链式连接平铺。实际上不管是单个RNN Cell还是一个RNN网络,都只有一个Cell的参数,在不断进行循环计算中更新。
由于RNN的循环特性,和自然语言文本的序列特性(句子是由单词组成的序列)十分匹配,因此被大量应用于自然语言处理研究中。下图为RNN的结构拆解:
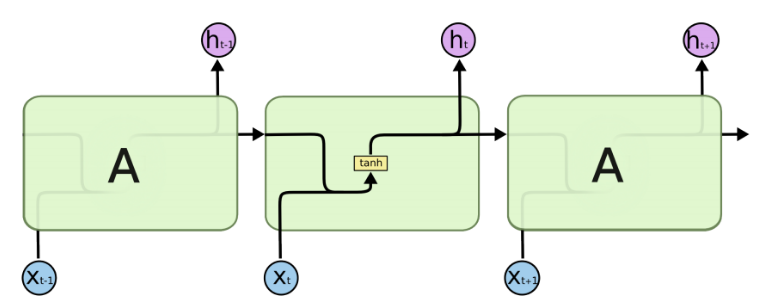
1.2 关于LSTM(Long short-term memory)
RNN单个Cell的结构简单,因此也造成了梯度消失(Gradient Vanishing)问题,具体表现为RNN网络在序列较长时,在序列尾部已经基本丢失了序列首部的信息。为了克服这一问题,LSTM(Long short-term memory)被提出,通过门控机制(Gating Mechanism)来控制信息流在每个循环步中的留存和丢弃。下图为LSTM的结构拆解:
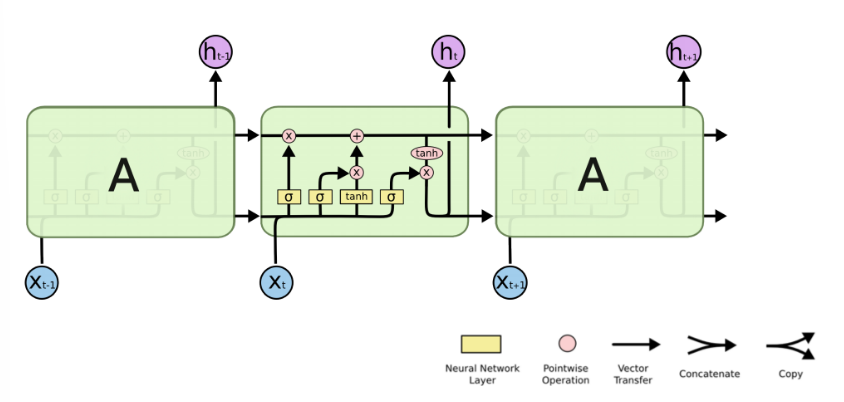
本项目选择LSTM变种而不是经典的RNN做特征提取,可规避梯度消失问题,并获得更好的模型效果。
在MindSpore中nn.LSTM对应的公式:
h 0 : t , ( h t , c t ) = LSTM ( x 0 : t , ( h 0 , c 0 ) ) h_{0:t}, (h_t, c_t) = \text{LSTM}(x_{0:t}, (h_0, c_0)) h0:t,(ht,ct)=LSTM(x0:t,(h0,c0))
这里nn.LSTM隐藏了整个循环神经网络在序列时间步(Time step)上的循环,送入输入序列、初始状态,即可获得每个时间步的隐状态(hidden state`)拼接而成的矩阵,以及最后一个时间步对应的隐状态。我们使用最后的一个时间步的隐状态作为输入句子的编码特征,送入下一层。
Time step:在循环神经网络计算的每一次循环,成为一个
Time step。在送入文本序列时,一个Time step对应一个单词。因此在本例中,LSTM的输出 h 0 : t h_{0:t} h0:t对应每个单词的隐状态集合, h t h_t ht和 c t c_t ct对应最后一个单词对应的隐状态。
下一层:全连接层,即nn.Dense,将特征维度变换为二分类所需的维度1,经过Dense层后的输出即为模型预测结果。
1.3 特征提取网络构建
RNN循环神经网络: nn.LSTM()
初始化参数:
embeddings:输入向量,hidden_dim:隐藏层特征的维度, output_dim:输出维数, n_layers:RNN 层的数量,bidirectional:是否为双向 RNN, pad_idx:padding_idx参数用于标记输入中的填充值(padding value)。在自然语言处理任务中,文本序列的长度不一致是非常常见的。为了能够对不同长度的文本序列进行批处理,我们通常会使用填充值对较短的序列进行填补。
tips:使用nn.embeddings()创建嵌入层时,可以通过padding_idx参数指定一个特定的索引,用于表示填充值。
embedding_layer = nn.Embedding(num_embeddings, embedding_dim, padding_idx=0),将padding_idx设置为0,表示使用索引为0的词汇作为填充值。在文本序列中,我们将使用0来填充较短的序列。
import math
import mindspore as ms
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore.common.initializer import Uniform, HeUniformclass RNN(nn.Cell):def __init__(self, embeddings, hidden_dim, output_dim, n_layers,bidirectional, pad_idx):super().__init__()vocab_size, embedding_dim = embeddings.shapeself.embedding = nn.Embedding(vocab_size, embedding_dim, embedding_table=ms.Tensor(embeddings), padding_idx=pad_idx)self.rnn = nn.LSTM(embedding_dim,hidden_dim,num_layers=n_layers,bidirectional=bidirectional,batch_first=True)weight_init = HeUniform(math.sqrt(5))bias_init = Uniform(1 / math.sqrt(hidden_dim * 2))self.fc = nn.Dense(hidden_dim * 2, output_dim, weight_init=weight_init, bias_init=bias_init)def construct(self, inputs):embedded = self.embedding(inputs)_, (hidden, _) = self.rnn(embedded)hidden = ops.concat((hidden[-2, :, :], hidden[-1, :, :]), axis=1)output = self.fc(hidden)return output
实例化模型,打印输出
hidden_size = 256
output_size = 1
num_layers = 2
bidirectional = True
lr = 0.001
pad_idx = vocab.tokens_to_ids('<pad>')model = RNN(embeddings, hidden_size, output_size, num_layers, bidirectional, pad_idx)
print(model)
