20230210组会论文总结
目录
【Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method】
【ShuffleMixer: An Efficient ConvNet for Image Super-Resolution】
【A Close Look at Spatial Modeling: From Attention to Convolution 】
【DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention 】
【DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation】
【Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method】
代码链接:https://github.com/TaoWangzj/LLFormer
主要创新点:设计了Axis Multi-Head Self-Atention,常规计算Attention的方式是逐像素去计算,时间复杂度为O(HW*HW),有一些论文会转换为计算通道维度的注意力计算,比如Restormer,时间复杂度可以降低到O(C*C),这种方式可以,但是本人觉得更多偏向于了通道维度,对于一些应用场景下, 还是避不开需要去计算空间维度的注意力,本文感觉最大的idea就是设计了将H和W两者分开计算,串联实现的想法。
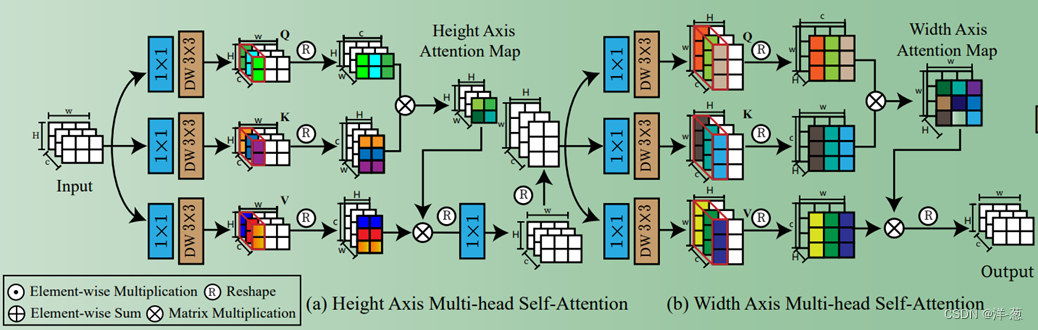
通过上图可以看到,以2*3的空间输入为例,Heights Axis方面计算得到的QKV矩阵均是2*2的,而Width Axis计算的QKV则是3*3的,整体上的时间复杂度就变成了O(H*H+W*W),确实是可以实现时间复杂度降维,目前不太确定这种方式的实现效果是否会比常规O(HW*HW)的效果好一些,但是感觉在计算Height和Width维度上的时候不可避免的会造成信息损失,但由于使用的结构是级联式Transformer结构,可以将这些损失降到最低通过不断堆积Transformer Block。
还有双门控FFN和Layer Attention,其实都是较为常见的已有工作。
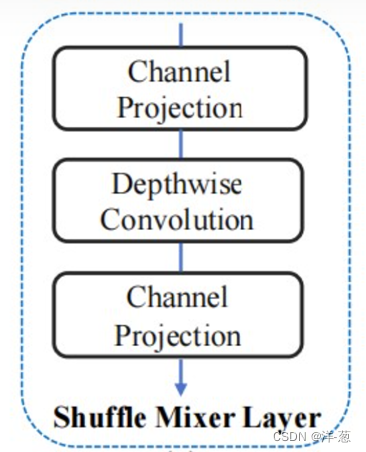
【ShuffleMixer: An Efficient ConvNet for Image Super-Resolution】
主要创新点:这个比较有意思的点在我看来就是Shuffle Mixer Layer中的Channel Projection,其实关于Shuffle的操作有很多,这个将特征进行通道维度的打散,然后随机去计算权重,通过两次Channel Projection将通道恢复,从而可以实现更强的特征融合和表征能力,提高模型的鲁棒性。

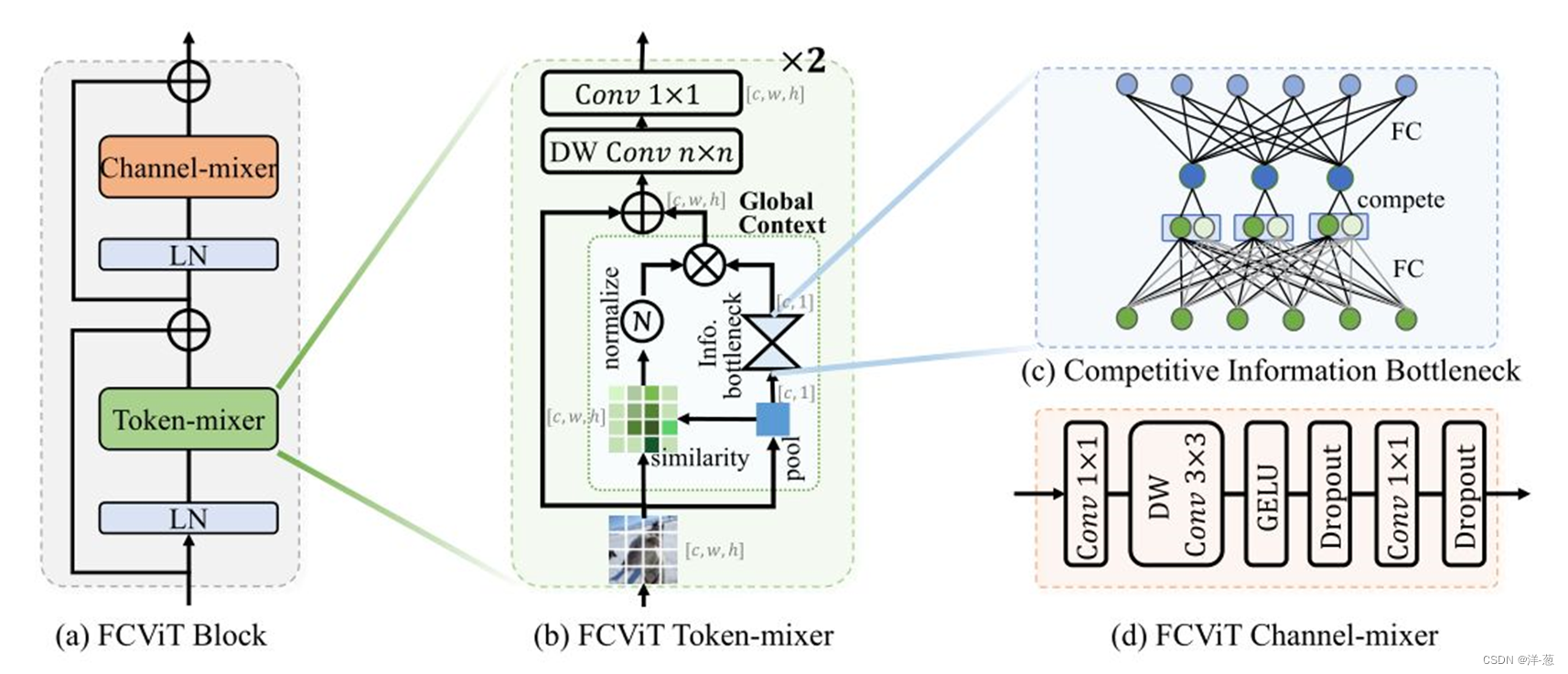
【A Close Look at Spatial Modeling: From Attention to Convolution 】
主要创新点:Transformer通常需要计算QKV从而计算出Self-Attention,这个步骤需要很大的算力,本文提出了一种新的想法去避开QKV去计算出相似性矩阵,CHW特征矩阵和经过pool操作后的矩阵相乘得到,有意思的是设计的Competitive Information Bottleeneck模块,设计了竞争机制。
【DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention 】
主要创新点:设计了一种Unet形式的网络架构,主要创新点的DEAB模块里边使用了CGA(Content-Guided Attention),看起来很强具有全局的注意力,实现方式其实就是使用了CBAM和Shuffle Channel。
其实可以发现很多论文都使用了Shuffle Channel的操作,目前想法是能不能将Shuffle Channel的操作加入到多模态中进行融合增强呢?

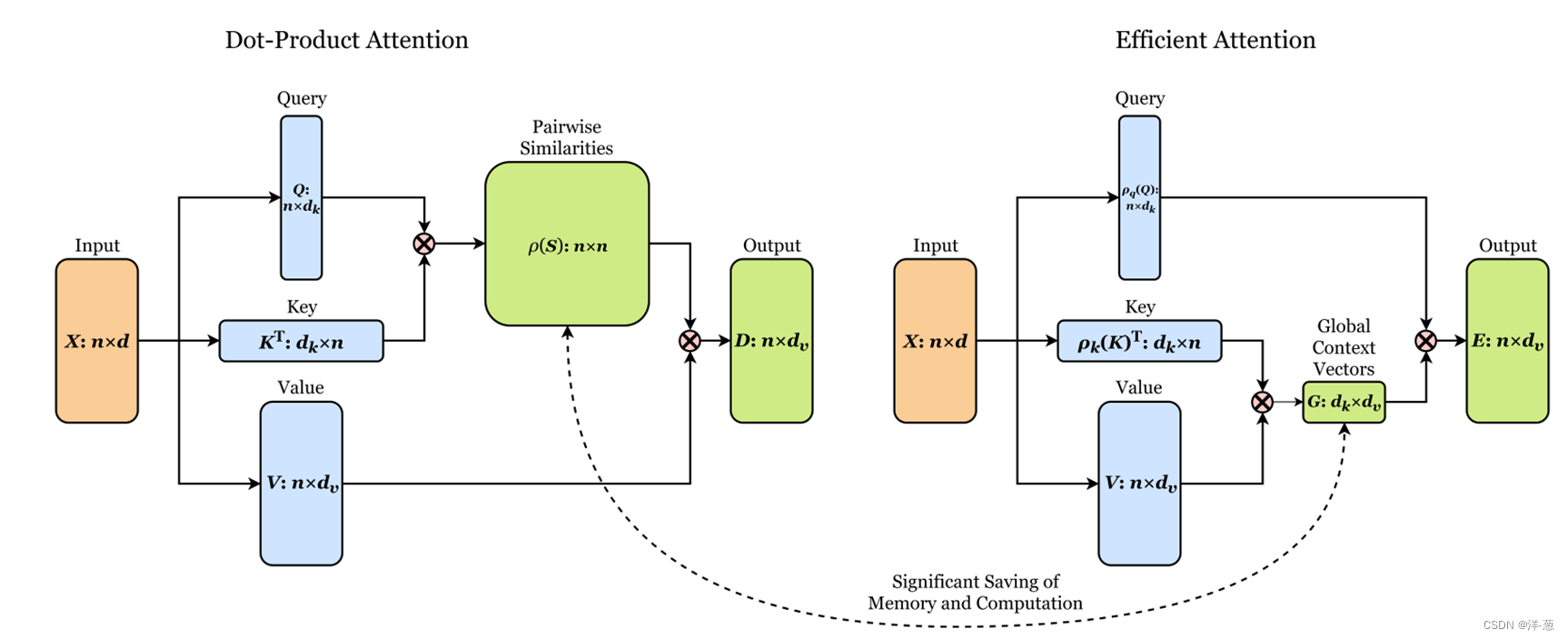
【DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation】
主要创新点:主要是在计算注意力(QKV)的时候进行了归一化K和V,使得时间复杂度降低,并且与传统的Dot-Product Attention相比,不是通过Q和K计算相似性矩阵(时间复杂度为O(N*N)),再与V进行乘法(时间复杂度为O(N*dv)),而是通过转置,先计算经过归一化后的K和V,计算Global Context Vector(时间复杂度为O(dk*dv))。
注:以上仅个人观后的想法,若有不足,请及时指出,欢迎大家讨论学习!