计算机视觉之Vision Transformer图像分类
Vision Transformer(ViT)简介
自注意结构模型的发展,特别是Transformer模型的出现,极大推动了自然语言处理模型的发展。Transformers的计算效率和可扩展性使其能够训练具有超过100B参数的规模空前的模型。ViT是自然语言处理和计算机视觉的结合,能够在图像分类任务上取得良好效果,而不依赖卷积操作。
Vision Transformer(ViT)简介
近些年,随着基于自注意(Self-Attention)结构的模型的发展,特别是Transformer模型的提出,极大地促进了自然语言处理模型的发展。由于Transformers的计算效率和可扩展性,它已经能够训练具有超过100B参数的空前规模的模型。
ViT则是自然语言处理和计算机视觉两个领域的融合结晶。在不依赖卷积操作的情况下,依然可以在图像分类任务上达到很好的效果。
模型结构
ViT模型的主体结构是基于Transformer模型的Encoder部分(部分结构顺序有调整,如:Normalization的位置与标准Transformer不同),其结构图[1]如下:
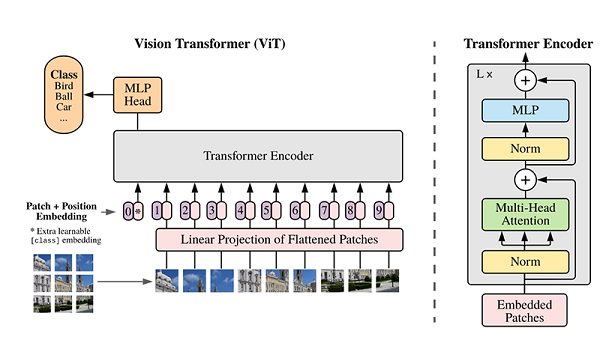
模型特点
ViT模型是一种用于图像分类的模型,将原图像划分为多个图像块,然后将这些图像块转换为一维向量,加上类别向量和位置向量作为模型输入。模型主体采用基于Transformer的Encoder结构,但调整了Normalization的位置,其中最主要的结构是Multi-head Attention。模型在Blocks堆叠后接全连接层,使用类别向量的输出进行分类,通常将全连接层称为Head,Transformer Encoder部分称为backbone。
Transformer基本原理
Transformer模型源于2017年的一篇文章[2]。在这篇文章中提出的基于Attention机制的编码器-解码器型结构在自然语言处理领域获得了巨大的成功。模型结构如下图所示:
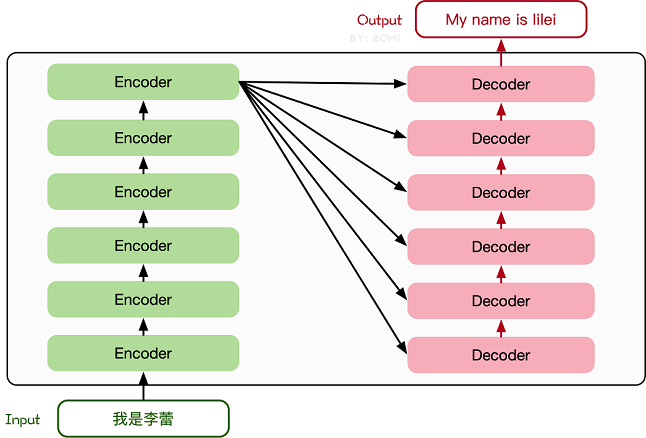
模型训练
模型训练前需要设定损失函数、优化器、回调函数等,以及建议根据项目需要调整epoch_size。训练ViT模型需要很长时间,可以通过输出的信息查看训练的进度和指标。
from mindspore.nn import LossBase
from mindspore.train import LossMonitor, TimeMonitor, CheckpointConfig, ModelCheckpoint
from mindspore import train# define super parameter
epoch_size = 10
momentum = 0.9
num_classes = 1000
resize = 224
step_size = dataset_train.get_dataset_size()# construct model
network = ViT()# load ckpt
vit_url = "https://download.mindspore.cn/vision/classification/vit_b_16_224.ckpt"
path = "./ckpt/vit_b_16_224.ckpt"vit_path = download(vit_url, path, replace=True)
param_dict = ms.load_checkpoint(vit_path)
ms.load_param_into_net(network, param_dict)# define learning rate
lr = nn.cosine_decay_lr(min_lr=float(0),max_lr=0.00005,total_step=epoch_size * step_size,step_per_epoch=step_size,decay_epoch=10)# define optimizer
network_opt = nn.Adam(network.trainable_params(), lr, momentum)# define loss function
class CrossEntropySmooth(LossBase):"""CrossEntropy."""def __init__(self, sparse=True, reduction='mean', smooth_factor=0., num_classes=1000):super(CrossEntropySmooth, self).__init__()self.onehot = ops.OneHot()self.sparse = sparseself.on_value = ms.Tensor(1.0 - smooth_factor, ms.float32)self.off_value = ms.Tensor(1.0 * smooth_factor / (num_classes - 1), ms.float32)self.ce = nn.SoftmaxCrossEntropyWithLogits(reduction=reduction)def construct(self, logit, label):if self.sparse:label = self.onehot(label, ops.shape(logit)[1], self.on_value, self.off_value)loss = self.ce(logit, label)return lossnetwork_loss = CrossEntropySmooth(sparse=True,reduction="mean",smooth_factor=0.1,num_classes=num_classes)# set checkpoint
ckpt_config = CheckpointConfig(save_checkpoint_steps=step_size, keep_checkpoint_max=100)
ckpt_callback = ModelCheckpoint(prefix='vit_b_16', directory='./ViT', config=ckpt_config)# initialize model
# "Ascend + mixed precision" can improve performance
ascend_target = (ms.get_context("device_target") == "Ascend")
if ascend_target:model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics={"acc"}, amp_level="O2")
else:model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics={"acc"}, amp_level="O0")# train model
model.train(epoch_size,dataset_train,callbacks=[ckpt_callback, LossMonitor(125), TimeMonitor(125)],dataset_sink_mode=False,)总结
本案例演示了如何在ImageNet数据集上训练、验证和推断ViT模型。通过讲解ViT模型的关键结构和原理,帮助用户理解Multi-Head Attention、TransformerEncoder和pos_embedding等关键概念。建议用户基于源码深入学习,以更详细地理解ViT模型的原理。