MDPs —— 马尔可夫决策定义与算法
文章目录
- MDPs 定义——由实例开始
- 时序决策问题
- 给游戏增点乐子
- *为什么要有折扣
- 游戏的解——原则
- 所以,什么是 MDPs?
- MDPs 的基本原理、表示
- 光环原理
- 效用的求解是反向传播的
- 原则不变条件
- MDPs 的表示
- MDPs 求解
- 效用迭代法
- 缺点
- 原则迭代法
MDPs 定义——由实例开始
时序决策问题
假设有一个 agent,从下图的 start 开始,移动到图中的 +1、-1 两个状态时,游戏结束。其中阴影部分是 agent 的无法移动区域,图如下:
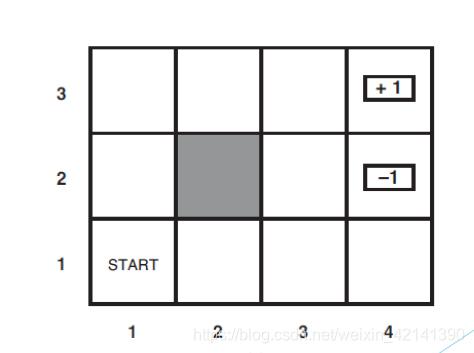
在这个游戏中,很明显可以用几个状态表示,首先是 agent 目前所在的状态(位置)集合,S = {s1,s2,…,sn},以及可以采取的动作集 A(s)。在此游戏中,很明显 A(s) = { 上下左右 }。
对于马尔可夫过程而言, A(s) 是不可靠的。具体地说,假设当前的 agent 采用了 “上”,那么在现实的实现中,有 80% 的概率走上,10% 的概率走右,10% 走左。因此,假如 agent 目前处于状态(位置) s,那么下一个动作后,agent 来到 s’ 需要用一个新的变量——状态转移模型 来表示,记为 P(s’|s,a);
可以看到,这个游戏的下一个状态,取决于上一个状态。而且这几个格子里面是什么情况,这几个格子的布局是什么,终点在哪里,都是已知的。这个游戏,其实也是一个时序决策过程。也就是说,环境已知,状态是通过上一个状态,转移到下一个状态。
给游戏增点乐子
当然,如果这个游戏只是单纯地走到 +1、-1,然后游戏结束,未免太过无聊。为了给游戏增加乐趣,我们给每一个格子都加入一个附加回报。所以 agent 在进行状态转移时(从一个格子,到另一个格子),都会积累一个回报,记为 R(s’,a,s)。当然,这个 R(s’,a,s) 可正可负,并且具有上下界。
然后,我们修改一下游戏获胜规则。为此定义一个效用函数,其定义为:agent 从当前状态(不是初始状态)到目标状态所经历的轨迹中,所有 回报之和。
当然,效用有两种计算方式,如下:
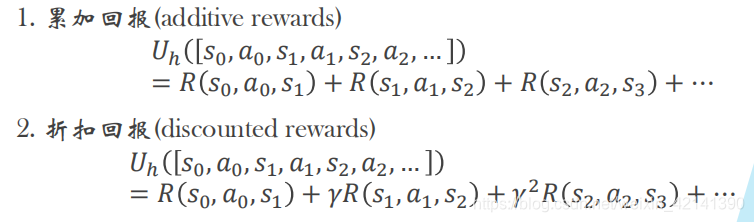
*为什么要有折扣
如果 agent 可以走无限多步,且 R 有正数,那么可以无限地来回走动,来实现效用无穷大,这样就没有意思了。采用折扣累加,就不会出现无穷大的情况,证明如下:

举个例子,加入上图除了+1/-1 格子外,所有格子的回报都是 -0.04。如果 agent 走了 10 步到了 +1,那么 start 的效用就是:-0.04x9 +1 = 0.64。
那么,如果是你玩这个游戏,你会采用哪种动作(从 start 开始),从而使得:从初始状态开始,到目标状态所经历的轨迹中,所有回报之和最高。
这个游戏显然由于状态转移的概率性,所以具有一定的随机性。也就是说,没有一种万金油的动作套路,使得积累回报最高。
游戏的解——原则
那么,加入给一个机器人来解决上面的游戏,我们需要给出所有格子,可以采用的最优动作。何谓最优?由于有了概率的参与,最优很显然变成期望最大。什么期望最大呢?当然是所有行动轨迹的效用的期望。
由于状态转移是随机的,因此,我们可以列出的解,就是每一个当 agent 由任意的 s 拉倒 任意的 s’ 时,应该采取的动作组成的集合,我们称这个集合为原则。很显然,原则是一个大小为 |S|^2 的集合,我们记为 π。当 agent 采取某个原则 π 时,显然状态 s 有的期望效用为:

因此,如果要解这个游戏,我们就要找到最优原则:

如果步长无限的情况下,很显然最优原则与初始状态是独立的。
所以,什么是 MDPs?
MDPs 是由以下部分组成的:
- agent 的状态集合 S
- 动作集合 A(s)
- 状态转移概率 P(s’|s,a)
- 效用函数 U(s)
要求的是一个动作原则,使得轨迹中回报的折扣累计的期望最大(效用期望最大)
MDPs 的基本原理、表示
光环原理
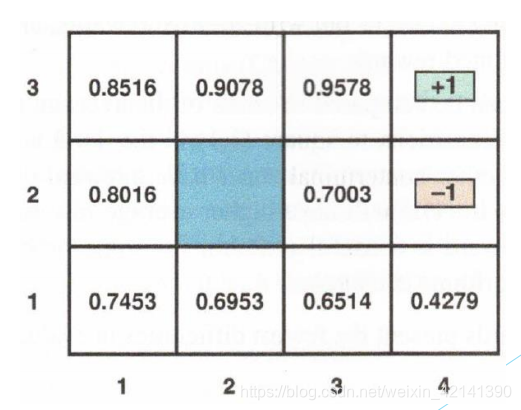
下图给出了每个格子的效用(效用将从后面的算法中求出),很明显,离 +1 越近,则效用越大。因为他走到 +1 所需要的步数最小。注意,MDPs 不会直接给出效用。
效用的求解是反向传播的
假如 agent 的目前状态是 s ,那么最佳原则应该采取的动作 a 应满足:

其中 s’ 为采用 a 后转移的状态,U(s’) 可由下述公式求出,即后续状态序列的折扣累计效用的期望:

此时, 状态 s 的效用是:

这个公式也叫 bellman 公式。
举个例子:
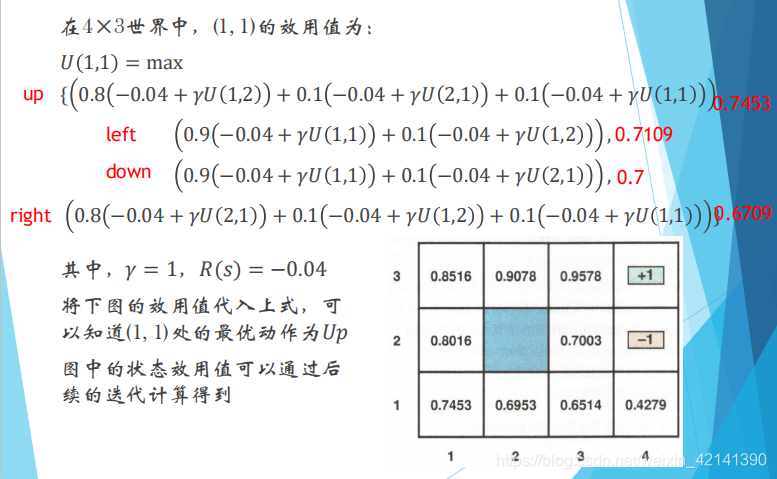
由此也可以看出,一个状态的效用,要从下一个状态的效用求出。而效用的求解,是回报沿着轨迹的累加。因此,效用的求解是反向传播的。
原则不变条件
假如回报 R(s) 进行了线性变化,如 R(s) = aR(s)+b (a>0),那么原则不变。
更进一步的,如果 R’(s’,a,s) = R(s’,a,s) + γ f(s’) - f(s) ,f(s) 是 s 的函数,那么原则也不变。
MDPs 的表示
- 用一个三维表列举所有状态,以及采取动作后来到的下一个状态的效用来表示。显然这个三维表的大小是 S by S by A。
- 用一个动态贝叶斯网络,创建一个动态决策网络,来表示 MDP;这里不详细解释。
MDPs 求解
效用迭代法
从上面的所有内容中,我们大致可以看出,要求解一个最好的 原则 π,必须先求出所有格子、在最优动作下的效用。我们可以用 bellman 公式来求取动作 + 效用:

假如 s 的取值有 n 个,U(s’) 、U(s) 为未知数,那么上式就可以得出 n 个方程组,这个方程组里有 n 个未知数。很显然,联立以上方程,就可以求出方程的解,即所有的 U(s)。
由于这个方程是一个非线性方程(带有 max),所以不能够直接求取。一个求解的方法是数值迭代法,具体如下:

R(s) 也就是 R(s’,a,s),通常是已知的。
用这个算法可以求解出 U(s):
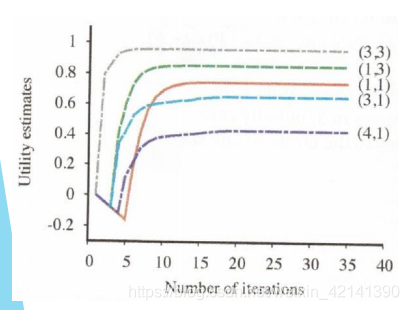
缺点
经过测试,当 δ 还很大的时候,求出来的 原则 π 就已经是最优原则了。由此推出另一个算法,原则迭代算法。
原则迭代法
首先取一个初始原则 π0,求出每一个状态的效用 U(s):

之后:

如是迭代,直到原则不变即可。具体算法如下:
