Oracle、MySQL、PostGreSQL、SQL Server-空值
Oracle、MySQL、PostGreSQL、SQL Server-null value
最近几年数据库市场百花齐放,在做跨数据库迁移的数据库选型时,除了性能、稳定、安全、运维、功能、可扩展外,像开发中对于值的处理往往容易被人忽视, 之前写过一篇关于PG区别Oracle在SQL解析缓存的笔记《PostgreSQL 12 : Prepare statement和plan_cache_mode 参数》,这里记录一下null 值在这几个数据库中的区别。
软件版本:Oracle 21c 、SQL Server 2019 、MySQL 8.0 、Mariadb 10.6 、PostGreSQL 13、OpenGauss 2.0
创建测试用例表
CREATE TABLE tab_null(id int, name char(10));INSERT INTO tab_null VALUES(1,'anbob');
INSERT INTO tab_null VALUES(2,NULL);
测试数据过滤
# oracle
SQL> select * from tab_null where name is null;ID NAME
---------- ----------2SQL> select * from tab_null where name is not null;ID NAME
---------- ----------1 anbobSQL> select * from tab_null where name=null;
no rows selectedSQL> select * from tab_null where null=null;
no rows selected# postgresql
postgres=# select * from tab_null where name is null;id | name
----+------2 |
(1 row)postgres=# select * from tab_null where name is not null;id | name
----+------------1 | anbob
(1 row)postgres=# select * from tab_null where name=null;id | name
----+------
(0 rows)postgres=# select * from tab_null where null=null;id | name
----+------
(0 rows)# MySQL/MariaDB
mysql> select * from tab_null where name is null;
+------+------+
| id | name |
+------+------+
| 2 | NULL |
+------+------+
1 row in set (0.00 sec)mysql> select * from tab_null where name is not null;
+------+-------+
| id | name |
+------+-------+
| 1 | anbob |
+------+-------+
1 row in set (0.00 sec)mysql> select * from tab_null where name=null;
Empty set (0.00 sec)mysql> select * from tab_null where null=null;
Empty set (0.00 sec)# SQL Serverselect * from tab_null where name is null;ID NAME
---------- ----------2select * from tab_null where name is not null;ID NAME
---------- ----------1 anbobselect * from tab_null where name=null;
no rows selectedselect * from tab_null where null=null;
no rows selected
Note:
可见所有数据库的结果是一样的。
# Mysql
mysql> select 1 from tab_null where 1 not in (null);
Empty set (0.00 sec)mysql> select 1 from tab_null where null not in (null);
Empty set (0.00 sec)mysql> select 1 from tab_null where null in (null);
Empty set (0.00 sec)mysql> select 1 from tab_null where exists(select null from dual);
+---+
| 1 |
+---+
| 1 |
| 1 |
| 1 |
+---+
3 rows in set (0.05 sec)
Note:
这类在4个库返回也是一样的,上面只附了MySQL,不再展示其它库。
唯一约束
# oracle
SQL> alter table tab_null add constraint c_tab_null_name_uni unique(name);
Table altered.SQL> INSERT INTO tab_null VALUES(3,NULL);
1 row created.SQL> select * from tab_null;ID NAME
---------- ----------1 anbob23
# postgresql
postgres=# alter table tab_null add constraint c_tab_null_name_uni unique(name);
ALTER TABLE
postgres=# INSERT INTO tab_null VALUES(3,NULL);
INSERT 0 1
postgres=# select * from tab_null;id | name
----+------------1 | anbob2 |3 |
(3 rows)# MySQL/MariaDB
mysql> alter table tab_null add constraint c_tab_null_name_uni unique(name);
Query OK, 0 rows affected (0.14 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> INSERT INTO tab_null VALUES(3,NULL);
Query OK, 1 row affected (0.01 sec)mysql> select * from tab_null;
+------+-------+
| id | name |
+------+-------+
| 1 | anbob |
| 2 | NULL |
| 3 | NULL |
+------+-------+
3 rows in set (0.00 sec)# SQL SERVER
alter table tab_null add constraint c_tab_null_name_uni unique(name);INSERT INTO tab_null VALUES(3,NULL);
Msg 2627 Level 14 State 1 Line 12
Violation of UNIQUE KEY constraint 'c_tab_null_name_uni'.
Cannot insert duplicate key in object 'dbo.tab_null'. The duplicate key value is (<NULL>).
Note:
这里只有SQL SERVER提示一个表中的null和null是重复记录, 其它库可以正常insert 多个 null 到有唯一约束的表。
NULL使用索引
# MySQL/MariaDB
mysql> alter table tab_null drop constraint c_tab_null_name_uni;
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> create index idx_tab_null_name on tab_null(name);
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> explain select * from tab_null where name is null;
+----+-------------+----------+------------+------+-------------------+-------------------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+-------------------+-------------------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | tab_null | NULL | ref | idx_tab_null_name | idx_tab_null_name | 41 | const | 2 | 100.00 | Using index condition |
+----+-------------+----------+------------+------+-------------------+-------------------+---------+-------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)# PostgreSQL
postgres=# alter table tab_null drop constraint c_tab_null_name_uni;
ALTER TABLE
postgres=# create index idx_tab_null_name on tab_null(name);
CREATE INDEX
postgres=# explain analyze select * from tab_null where name is null;QUERY PLAN
---------------------------------------------------------------------------------------------------Seq Scan on tab_null (cost=0.00..1.03 rows=1 width=18) (actual time=0.008..0.009 rows=2 loops=1)Filter: (name IS NULL)Rows Removed by Filter: 1Planning Time: 0.130 msExecution Time: 0.019 ms
-- 因为小表代价,这是使用了seq scan 全表扫,下面往表里insert一些数据postgres=# insert into tab_null select generate_series,generate_series||'anbob' from generate_series(101,10000);
INSERT 0 9900
postgres=# analyze tab_null;
ANALYZE
postgres=# explain analyze select * from tab_null where name is null;QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------Index Scan using idx_tab_null_name on tab_null (cost=0.29..9.64 rows=2 width=15) (actual time=0.010..0.011 rows=2 loops=1)Index Cond: (name IS NULL)Planning Time: 0.199 msExecution Time: 0.031 ms
(4 rows)# Oracle
SQL>alter table tab_null drop constraint c_tab_null_name_uni;
Table altered.SQL> create index idx_tab_null_name on tab_null(name);
Index created.SQL> explain plan for select /*+index(t)*/ * from tab_null t where name is null;Explained.SQL> @x2PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------
Plan hash value: 2647411751------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 50 | 2 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| TAB_NULL | 2 | 50 | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------Predicate Information (identified by operation id):
---------------------------------------------------1 - filter("NAME" IS NULL)Hint Report (identified by operation id / Query Block Name / Object Alias):
Total hints for statement: 1 (U - Unused (1))
---------------------------------------------------------------------------1 - SEL$1 / "T"@"SEL$1"U - index(t)-- 解决这个问题可以增加常数的复合索引SQL> create index idx_tab_null_name_0 on tab_null(name,0);
Index created.SQL> explain plan for select /*+index(t)*/ * from tab_null t where name is null;
Explained.SQL> @x2
PLAN_TABLE_OUTPUT
-----------------------------------------------------------------------------------------------------------
Plan hash value: 2247804559-----------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 50 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| TAB_NULL | 2 | 50 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_TAB_NULL_NAME_0 | 1 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------2 - access("NAME" IS NULL)# SQL SERVER
SET statistics profile on;
SELECT * FROM tab_null with (index(idx_tab_null_name)) Where name IS NULL;
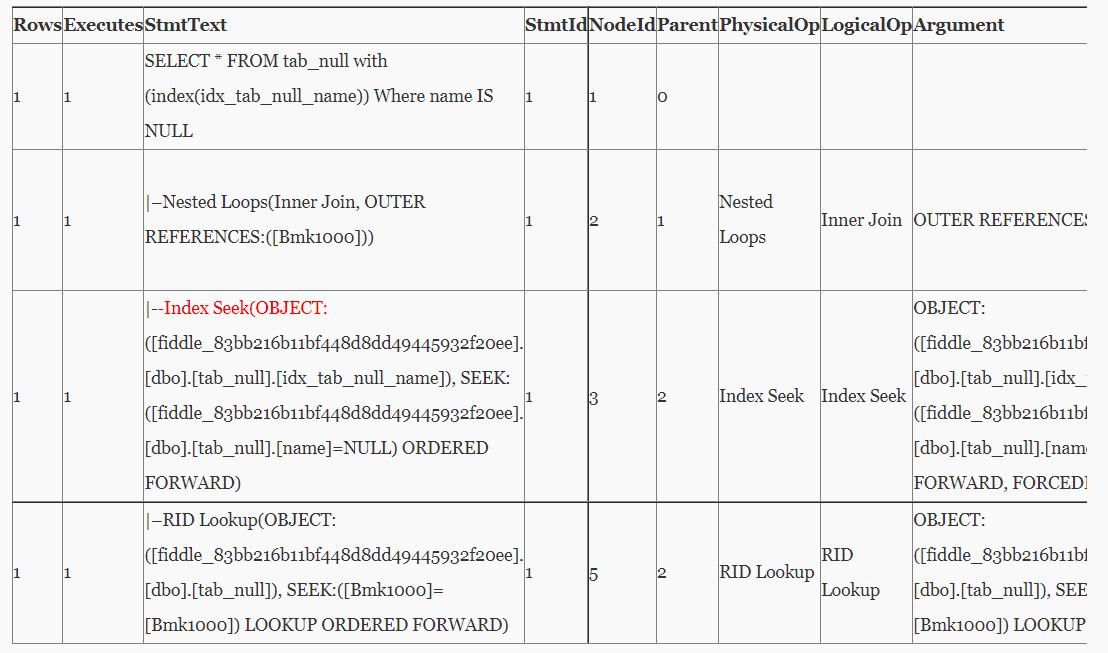
Note:
对于is null的谓词条件注意MySQL、MariaDB即使很少的记录也使用的index感觉更像是RULE CBO;
PostgreSQL开始使用了全表扫,也可能是基于代价的估算,全表扫要优于使用索引,因为pg默认没有像oracle,sql server, mysql 自带的hint可以强制使用索引,后来我们填充了更多的数据,PostgreSQL也使用上了索引,当然PG 也有扩展pg_hint_plan可以实现,不过PG认为用户中使用hint干扰优化器是不好的习惯,不应该那么做;
Oracle数据库因为单列索引不会储存null值,所以is null 即使使用hint 也无法使用索引,需要优化小技巧,增加常量的复合索引使用索引;
SQL Server同样我们在加hint with (index(idx_tab_null_name))后,执行计划中的Index Seek 也可以确认用上了索引。
字符串拼接
# sql server 2019
select null+'anbob'-------------
null# mariadb 10.6
select null+'anbob'-------------
null# mysql 8.0
select null+'anbob'-------------
null# postgres 13
postgres=# select 'anbob'||null;?column?
----------(1 row)# oracle 21c
SQL> select null||'anbob' from dual;NULL|
-----
anbob# OpenGauss
[og@oel7db1 data]$ gsql -d anbob -p 15432
gsql ((openGauss 2.0.0 build 78689da9) compiled at 2021-03-31 21:04:03 commit 0 last mr )
NOTICE : The password has been expired, please change the password.
Non-SSL connection (SSL connection is recommended when requiring high-security)
Type "help" for help.^
anbob=# select null||'anbob' ;?column?
----------anbob
(1 row)
Note:
注意也是只有Oracle不同于其它库,在null值和其它字符串拼接后可以正常返回部分有效值,而其它所有库全部返回空。
总结:
对于null值的谓词过滤条件时(IS NULL、IS NOT NULL, >,< ,=),4个数据库返回数据记录是一样的;
对于null 值的唯一约束,只有SQL Server不允许null 记录重复,而其它数据库不限制;
对于is null使用Btree索引, 只有Oracle是默认无法索引的(需要创建常量的复合索引),其它数据库优化器在认为合适时可以正常使用索引;
对于null与字符串拼接就更有意思,sql server\postgresql\mysql在与null拼接后返回null, Oracle返回是字符串的值,而且基于Postgresql的OpenGauss返回和Oracle相同也是字符串,看来是与oracle做过兼容性修改。