深度相机识别物体——实现数据集准备与数据集分割
一、数据集准备——Labelimg进行标定
1.安装labelimg——pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
2.建立相应的数据集存放文件夹

3.打开labelimg,直接在命令行输入labelimg即可,并初始化

4.开始标注,设置标注好后自动保存view——Auto Save mode

详细可参考博文:目标检测---利用labelimg制作自己的深度学习目标检测数据集-CSDN博客
二、完成数据集分割,为实现模型训练做准备
1.数据分割:训练集占比70%,测试集占比30%
2.数据分割的详细步骤
1)确认是否已经建立测试集文件夹,如果没有,则通过python指令建立相应的测试集文件夹
# 训练集的路径
train_p = r"C:\Users\82370\.conda\envs\Ayolo8\Lib\site-packages\ultralytics\dataset\train"
# 验证集的路径
val_p = r"C:\Users\82370\.conda\envs\Ayolo8\Lib\site-packages\ultralytics\dataset\val"
# 图像数据的路径
imgs_p = "images"
# 标签数据的路径
labels_p = "labels"# 创建训练集
# 首先判断训练集的地址是否存在,不存在就创建路径
if not os.path.exists(train_p): # 指定要创建的目录os.mkdir(train_p)
# 在训练集的地址下添加两个文件夹:images和labels
tp1 = os.path.join(train_p, imgs_p)
tp2 = os.path.join(train_p, labels_p)
# 打印images和labels的存放地址tp1和tp2
print(tp1, tp2)
# 如果没有这两个文件夹,就创建相应文件夹
if not os.path.exists(tp1): # 指定要创建的目录os.mkdir(tp1)
if not os.path.exists(tp2): # 指定要创建的目录os.mkdir(tp2)# 创建测试集文件夹与上述训练集文件夹创建方法已知
if not os.path.exists(val_p):os.mkdir(val_p)
vp1 = os.path.join(val_p, imgs_p)
vp2 = os.path.join(val_p, labels_p)
print(vp1, vp2)
if not os.path.exists(vp1):os.mkdir(vp1)
if not os.path.exists(vp2):os.mkdir(vp2)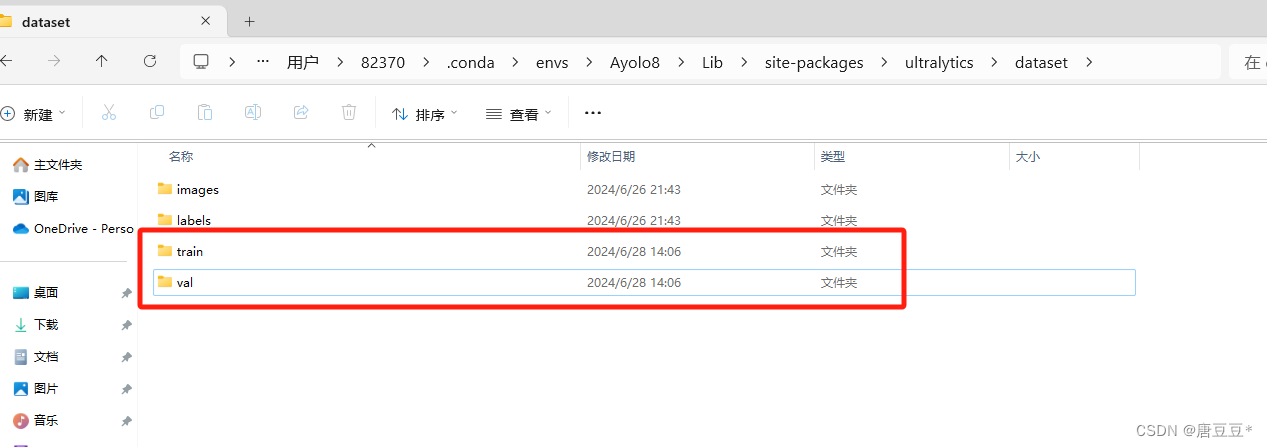
2)划分数据集:
确认训练集占比——将list列表随机排序,并按照比例及逆行分割——判断i是在哪个list里面,并对其图片和标签进行分类复制存储。
将list列表随机排序并分割的代码
# 此函数用于将full_list按照ratio比例进行切割
def data_split(full_list, ratio):n_total = len(full_list) # list的长度offset = int(n_total * ratio) # 总长度乘以相应的比例# 如果按照比例得到的offest小于1,则表明没有训练集,返回空if n_total == 0 or offset < 1:return [], full_list# 对列表进行随机排序random.shuffle(full_list)# 对列表按照offset进行分割,得到两个子列表sublist_1 = full_list[:offset] # 这里不包括offsetsublist_2 = full_list[offset:]# 返回分割后的两个列表return sublist_1, sublist_2判断i在哪个list里面,并实现复制存储
# 数据集源文件放置的路径
images_dir = "C:/Users/82370/.conda/envs/Ayolo8/Lib/site-packages/ultralytics/dataset/images"
labels_dir = "C:/Users/82370/.conda/envs/Ayolo8/Lib/site-packages/ultralytics/dataset/labels"# 划分数据集,设置数据集数量占比
proportion_ = 0.7 # 训练集占比
# 使用python的os模块来获取指定目录下的所有文件名,并赋值给total_file
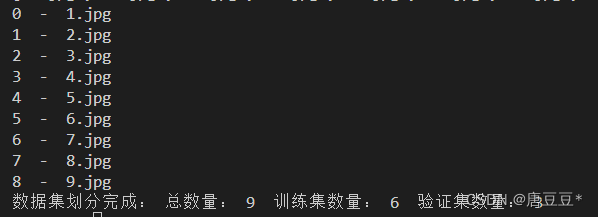
total_file = os.listdir(images_dir)
print(total_file)
# 统计所有的已标注文件数量
num = len(total_file)
# 初始化一个空列表
list_ = []
# 将0,num-1的整数添加到list_列表中
for i in range(0, num):list_.append(i)
# 将list随机排序后再分割成两个列表
list1, list2 = data_split(list_, proportion_)for i in range(0, num):# 遍历total_file列表的每一个文件file = total_file[i]# 打印出文件的索引和文件名,即每一个编号对应的图片文件名称print(i, ' - ', total_file[i])# 将文件名进行分割“1.txt”则name的值=1name = file.split('.')[0]# 如果i再列表1中表明该对应的图片需要放到训练集中if i in list1:# 以下两个语句用于获取相应的第i个图片的地址# 将images_dir,file合并成一个路径,并存储到jpg_1这个变量中# 将train_p,images_p,file合并成一个路径,并存储到jpg_2这个变量中jpg_1 = os.path.join(images_dir, file)jpg_2 = os.path.join(train_p, imgs_p, file)# 得到相应的label文件的两个地址txt_1 = os.path.join(labels_dir, name + '.txt')txt_2 = os.path.join(train_p, labels_p, name + '.txt')# 如果有待复制的文件和标签,则进行相应的复制工作if os.path.exists(txt_1) and os.path.exists(jpg_1):shutil.copyfile(jpg_1, jpg_2) # 将1复制到2中shutil.copyfile(txt_1, txt_2) # 将1复制到2中# elif==>表示else if的意思# 如果只有txt_1存在,则打印相应的标签地址,否则打印图片的地址elif os.path.exists(txt_1):print(txt_1) # txt_1存在else:print(jpg_1) # txt_1不存在# 如果i在列表2中执行以下程序段elif i in list2:jpg_1 = os.path.join(images_dir, file)jpg_2 = os.path.join(val_p, imgs_p, file)txt_1 = os.path.join(labels_dir, name + '.txt')txt_2 = os.path.join(val_p, labels_p, name + '.txt')shutil.copyfile(jpg_1, jpg_2)shutil.copyfile(txt_1, txt_2)相应的运行结果