图数据库 vs 向量数据库
最近大模型出来之后,向量数据库重新翻红,业界和市场上有不少声音认为向量数据库会极大的影响图数据库,图数据库市场会萎缩甚至消失,今天就从技术原理角度来讨论下图数据库和向量数据库到底差别在哪里,适合什么场景,图数据库会不会消失。
当前,百度智能云云数据库特惠专场开始!热销规格新用户免费使用,欢迎参与!
人工智能思路之争
讨论图、向量,大模型之前先简单说下人工智能发展过程中出现的主义之争。人工智能在过去几十年的发展中,出现了好几种思路,也就分为几大学派,或者主义。分别是:
-
符号主义(symbolicism),又称为逻辑主义、心理学派或计算机学派,主要就是基于逻辑推理的智能模拟方法,对应到人类智能就是认知能力(学习能力、推理能力、专家能力),知识图谱就是源于符号主义。
-
连接主义(connectionism),又称为仿生学派或生理学派,其主要原理为神经网络及神经网络间的连接机制与学习算法,深度神经网络解决的就是感知智能(人类的眼、耳、鼻、舌、身对环境的感知能力),现在的大模型就是连接主义的产物,但同时因为模型参数足够大,从感知智能又突破到了认知智能,甚至未来会走向 AGI(通用人工智能)。
-
行为主义(actionism),又称为进化主义或控制论学派,其原理为控制论及感知-动作型控制系统,这一派主要搞机器人。比如机器人的操控,要求机器人不光要认知和感知,还要操作和行动。nvidia的黄教主最近就各种场合讲未来是机器人的时代。
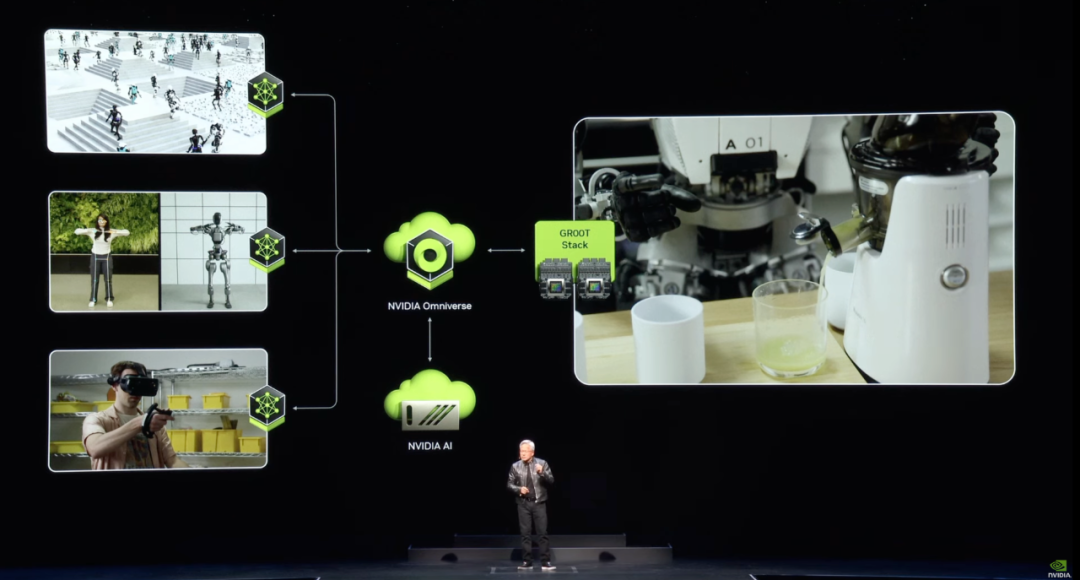
这三种主义是思路之争,其实也代表了对人工智能模拟的三个路径。未来可能会走向大一统和融合。
图数据库适合什么场景
图数据库比起传统的信息存储和组织模式,图数据库能够很清晰揭示复杂的模式,尤其在错综复杂的社交,物流,金融风控行业效果更为明显。典型场景有:
-
社交网络:数十亿关系查询,传统关系型数据库无法胜任低时延,以及超过 3 层好友关系的查询。
-
推荐引擎:通过用户的兴趣、好友和阅读历史记录等信息之间的关系,向用户提供推荐。典型用在电商、短视频、新零售场景。
-
网络&IT 运维:基础设备规模庞大,结构复杂,帮助深入了解设备状态,设备之间的关系,实现网络设备智能监控和管理。
-
金融风控:提供实时的用户行为检测,识别敏感用户,及时识别欺诈风险,错综复杂的人物关系分析,进行用户分群,识别异常群体等。
向量数据库适合什么场景
向量数据库最早解决非结构化数据相似度检索问题。通过把非结构化数据 embedding 成向量,通过向量的相似度检索来实现非结构化数据的相似度搜索。电销场景有:
-
相似度检索:可以做多模态检索(文本、图片、音频、视频),推荐系统,分类系统等。典型用在
-
互联网,如电商的推荐。
-
政企,如公安的图谱搜索
-
自动驾驶,质检图谱的搜索等
-
-
语义检索:利用文本,向量的混合搜索,实现多路召回,再加上reRanker模型实现语义排序。常用于企业的搜索,实现高质量的搜索
-
RAG:大模型活了,搭配大模型使用,把检索结果给到大模型,实现高质量的总结。最常用的是知识库,客服,大模型记忆问答等场景。这块各行各业都在实验和创新的 copilot 就是用到了 RAG 技术。
用一张表格总结如下:
| 分类 | 说明 | 能做什么业务 | 典型场景和行业 |
| 相似度检索 | 向量传统应用场景,向量检索为主 |
|
|
| 语义搜索 | 文本和向量混合索引 替代 ES 的一些搜索场景 |
|
|
| RAG | 搭配大模型使用,检索结果给大模型总结 |
|
|
两者对比
图数据库擅长推理能力,但是图实体模型建立本身门槛高,需要大量专业人员。向量数据库人工介入较少,但是结果准确度就差一些,各有各合适空间。下面是两者的对比:
| 向量数据库+大模型 | 图数据库+知识图谱 | |
| 性能 | 数据量大,性能更好 | 数据量大,性能受挑战 |
| 复杂问题 | 复杂问题,查询结果不一定完整 | 复杂问题,可以取得更可靠的内容 |
| 建模难度 | 适合处理非结构化数据,文本转换成高维向量 | 实体关系建模,构建知识图谱 建模工作难度和工作量很大 |
| 适合场景 | 智能推荐系统:找出相似的,不需要精确 | 决策支持系统,需要梳理特定关系,保证逻辑关系正确性 |
因此我们可以看出,向量和知识图谱还是有各自适合的范围。
选型考虑条件
如果一个业务到底要选型向量还是知识图谱,就要从多个维度去考虑,下面是建议参考和选型的维度:
| 向量数据库 | 知识图谱 | |
| 问题复杂度 | 非结构化,无复杂关系的选向量 | 大量相互关联知识实体 |
| 使用场景 | 简单相似度搜索,用向量数据库 | 基于实体关系的,复杂推理 |
| 数据量考量 | 扩展性高,数据量大 | 数据增长,关系复杂,维护难度会变高 |
| 团队能力 | 人力缺乏,选向量 | 事件建模,开发,算法技能 |
未来趋势
目前市面上看到各个厂家都在纷纷探索向量+图的融合演进,可见的未来,大概率两者会取各自长处,进行融合解决更复杂的问题。
当前,百度智能云云数据库特惠专场开始!热销规格新用户免费使用,欢迎参与!