详解Elastic Search高速搜索背后的秘密:倒排索引

引入
全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选,相信大家多多少少的都听说过它。它可以快速地储存、搜索和分析海量数据。就连维基百科、Stack Overflow、Github 都采用它选择作为自己的搜索引擎今天就让我们来了解了解 Elasticsearch 为什么这么快它的架构介绍及原理解析。
文章目录
- 引入
- 一 、Elastic Search的简介
- 二、什么是倒排索引
- 2.1 倒排索引讲解
- 三、倒排索引的工作原理
- 3.1 分词与索引构建
- 3.2 索引存储与优化
- 3.3 查询处理
- 四、构建倒排索引的源码解析
- 五、实战教学
- 5.1 创建索引和映射
- 5.2 添加文档
- 5.3 搜索文档
- 总结
一 、Elastic Search的简介
Elastic Search(简称ES)是一个基于Apache Lucene构建的开源、分布式、RESTful搜索和分析引擎。它允许你快速地存储、搜索和分析大量数据。ES通常用于日志分析、全文搜索等复杂的数据分析场景。
二、什么是倒排索引
倒排索引是一种用于快速检索的数据结构,常用于搜索引擎和数据库中。与传统的正排索引不同,倒排索引是根据关键词来建立索引,而不是根据文档ID。
2.1 倒排索引讲解
下面我们用一个简单的例子描述一下倒排索引的作用过程:
假如现在有三份数据文档,内容分别是:
代码语言:javascript
Doc 1:Java is the best programming languageDoc 2:PHP is the best programming languageDoc 3:Javascript is the best programming language
为了创建索引,ES引擎通过分词器将每个文档的内容拆成单独的词(称之为词条,或term),再将这些词条创建成不含重复词条的排序列表,然后列出每个词条出现在哪个文档,结果如下:
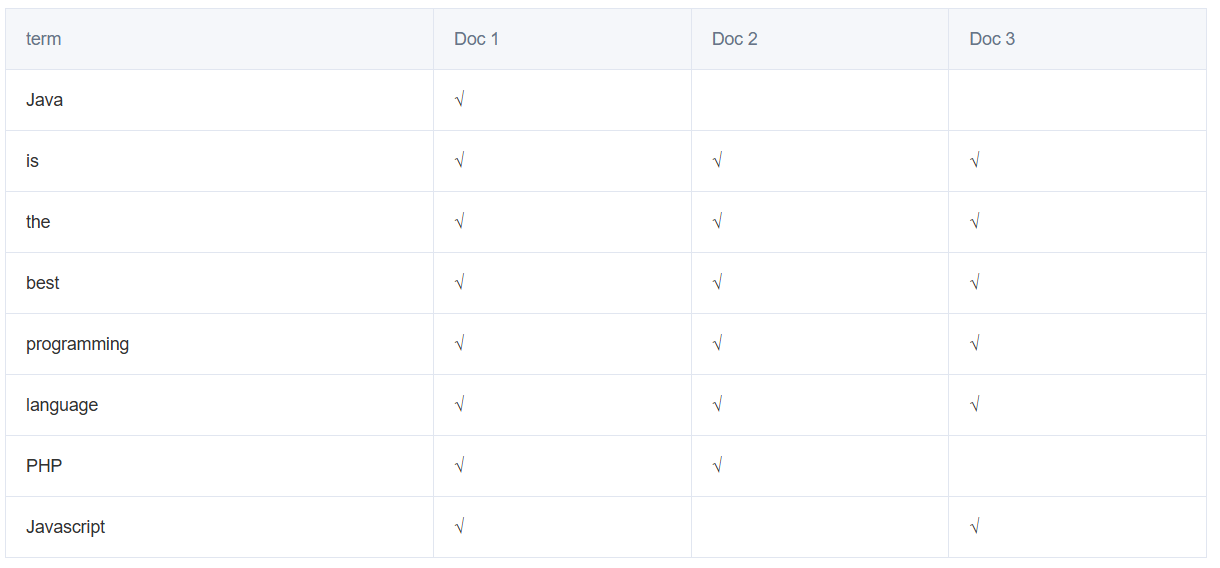
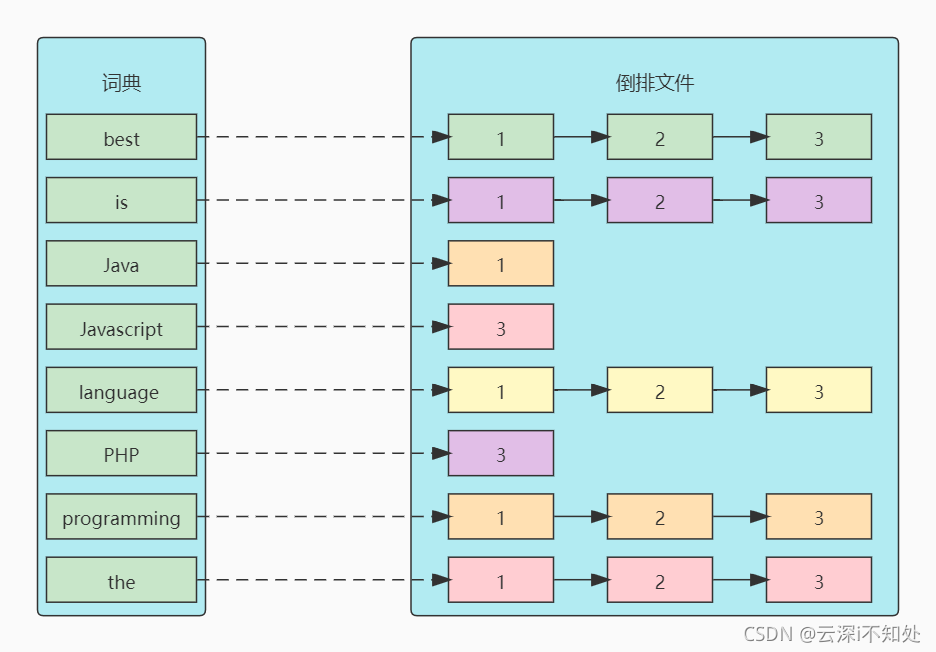
这种结构由文档中所有不重复的词的列表构成,对于其中每个词都有至少一个文档与与之关联。这种由属性值来确定记录的位置的结构就是倒排索引,带有倒排索引的文件被称为倒排文件。
将上表转为更直观的图片来展示倒排索引:
三、倒排索引的工作原理
3.1 分词与索引构建
首先,搜索引擎会对文档内容进行分词处理,将文本拆分成独立的单词或词组。然后,为每个单词或词组创建一个倒排列表,该列表记录了包含该单词或词组的所有文档的ID和该单词在文档中的位置信息(如偏移量、词频等)。
3.2 索引存储与优化
接下来,搜索引擎会将这些倒排列表存储在磁盘上,并进行一系列的优化操作,如压缩、合并等,以减少存储空间和提高查询效率。这些优化操作使得倒排索引在保持高效查询性能的同时,也具有良好的可扩展性和稳定性。
3.3 查询处理
当用户发起搜索请求时,搜索引擎会对查询语句进行分词处理,并生成一个查询词列表。然后,根据这个查询词列表在倒排索引中查找对应的倒排列表,并将这些倒排列表进行交集运算,以找到同时包含所有查询词的文档。最后,根据一定的排序算法对结果进行排序,并返回给用户。
四、构建倒排索引的源码解析
public class IndexWriter {// ... 其他属性和方法public void addDocument(Document doc) throws IOException {// Document 是一个容器,存储了待索引的字段和值// ... 初始化和准备阶段的代码// 遍历文档的每个字段for (IndexableField field : doc) {// 获取字段的名称和值String name = field.name();String value = field.stringValue();// 使用分析器对文本进行分词Analyzer analyzer = getAnalyzer();TokenStream tokenStream = analyzer.tokenStream(name, value);tokenStream.reset();// 遍历分词结果,构建倒排索引while (tokenStream.incrementToken()) {CharTermAttribute termAtt = tokenStream.getAttribute(CharTermAttribute.class);String termText = termAtt.toString();// 此处的 termText 即为分词后的词项// 将词项加入到倒排索引中,此处为简化示例,具体实现会涉及到词项的存储、文档的标识、词项在文档中的位置等信息addTermToInvertedIndex(name, termText, docId);}tokenStream.end();tokenStream.close();}// ... 后续的索引更新和维护代码}private void addTermToInvertedIndex(String fieldName, String termText, int docId) {// 此方法用于将词项加入到倒排索引中// 在实际的 Lucene 源码中,这里会涉及到更复杂的数据结构和算法来存储和管理倒排索引// ... 具体的实现代码}// ... 其他属性和方法
}五、实战教学
5.1 创建索引和映射
首先,我们需要创建一个索引,并为该索引定义一个映射(mapping),以确定文档的结构。
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;public class CreateIndexExample {public static void createBlogIndex(RestHighLevelClient client) {CreateIndexRequest request = new CreateIndexRequest("blog");request.source("{\"properties\": {\"title\": {\"type\": \"text\"},\"content\": {\"type\": \"text\"}}");try {CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);System.out.println(createIndexResponse.isAcknowledged());} catch (IOException e) {e.printStackTrace();}}
}5.2 添加文档
接下来,我们可以向我们的索引中添加一些文档。
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;public class AddDocumentExample {public static void addBlogPost(RestHighLevelClient client, String id, String title, String content) {IndexRequest request = new IndexRequest("blog").id(id);request.source("{\"title\": \"" + title + "\", \"content\": \"" + content + "\"}");try {IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);System.out.println(indexResponse.getId());} catch (IOException e) {e.printStackTrace();}}
}5.3 搜索文档
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;public class SearchDocumentExample {public static void searchPost(RestHighLevelClient client, String query) {SearchRequest searchRequest = new SearchRequest("blog");SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.matchQuery("title", query));searchRequest.source(searchSourceBuilder);try {SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);for (SearchHit hit : searchResponse.getHits().getHits()) {System.out.println(hit.getSourceAsString());}} catch (IOException e) {e.printStackTrace();}}
}总结
过这个简单的实战示例,我们可以看到Elasticsearch的倒排索引如何使得文本搜索变得高效。倒排索引的核心思想是将单词或词组映射到包含它们的文档上,这样我们就可以直接查询倒排索引来找到包含特定单词的文档,而不需要逐个检查每个文档的内容。这使得Elasticsearch成为一个非常强大的搜索引擎,适用于各种需要高效文本搜索的场景。