SparkSQL的分布式执行引擎-Thrift服务:学习总结(第七天)
系列文章目录
SparkSQL的分布式执行引擎
1、启动Thrift服务
2、beeline连接Thrift服务
3、开发工具连接Thrift服务
4、控制台编写SQL代码
文章目录
- 系列文章目录
- 前言
- 一、SparkSQL的分布式执行引擎(了解)
- 1、启动Thrift服务
- 2、beeline连接Thrift服务
- 3、开发工具连接Thrift服务
- 4、控制台编写SQL代码
前言
本文主要讲述SparkSQL的分布式执行引擎-Thrift服务
一、SparkSQL的分布式执行引擎(了解)
分布式执行引擎 == Thrift服务 == ThriftServer == SparkSQL中的Hiveserver2
1、启动Thrift服务
前提:已经完成Spark集成Hive的配置。但是目前集成后,如果需要连接Hive,此时需要启动一个Spark的客户端(spark-sql、代码)才可以。这个客户端底层相当于启动服务项,用于连接Hive的metastore的服务,进行处理操作。一旦退出客户端,相当于这个服务也就没有了,无法再使用
目前的情况非常类似于在Hive部署的时候,有一个本地模式部署(在启动Hive客户端的时候,内部自动启动一个Hive的hiveserver2服务项)
大白话: 目前在Spark后台,并没有一个长期挂载的Spark的服务(Spark HiveServer2服务)。导致每次启动Spark客户端,都需要在内部启动一个服务项。这种方式,不适合测试使用,不合适后续的快速开发
如何启动Spark 提供的分布式的执行引擎呢? 这个引擎大家完全可以将其理解为Spark的HiveServer2服务,实际上就是Spark的Thrift服务项
# 注意: 要启动sparkThriftServer2服务,必须要保证先启动好Hadoop以及Hive的metastore,不能启动Hive的hiveserver2服务!
# 启动 hadoop集群
start-all.sh# 启动hive的metastore
nohup /export/server/hive/bin/hive --service metastore &# 最后执行以下命令启动sparkThriftServer2:
/export/server/spark/sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10000 \
--hiveconf hive.server2.thrift.bind.host=node1 \
--hiveconf spark.sql.warehouse.dir=hdfs://node1:8020/user/hive/warehouse \
--master local[2]
校验是否成功:

访问界面:默认4040

2、beeline连接Thrift服务
启动后,可以通过spark提供beeline的方式连接这个服务。连接后,直接编写SQL即可
相当于模拟了一个Hive的客户端,但是底层执行的是Spark SQL,最终将其转换为Spark RDD的程序
启动命令:/export/server/spark/bin/beeline然后输入:!connect jdbc:hive2://node1:10000继续输入用户名: root
注意密码: 不需要写,直接回车

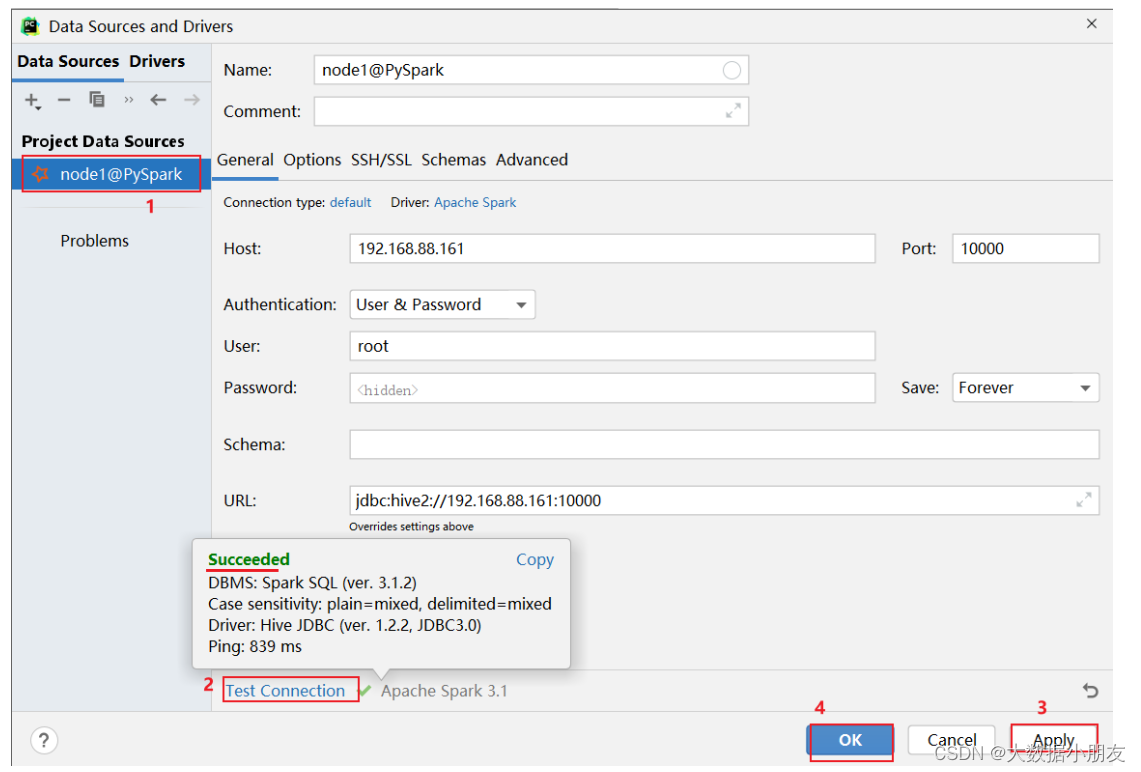
3、开发工具连接Thrift服务
如何通过DataGrip或者PyCharm连接Spark进行操作
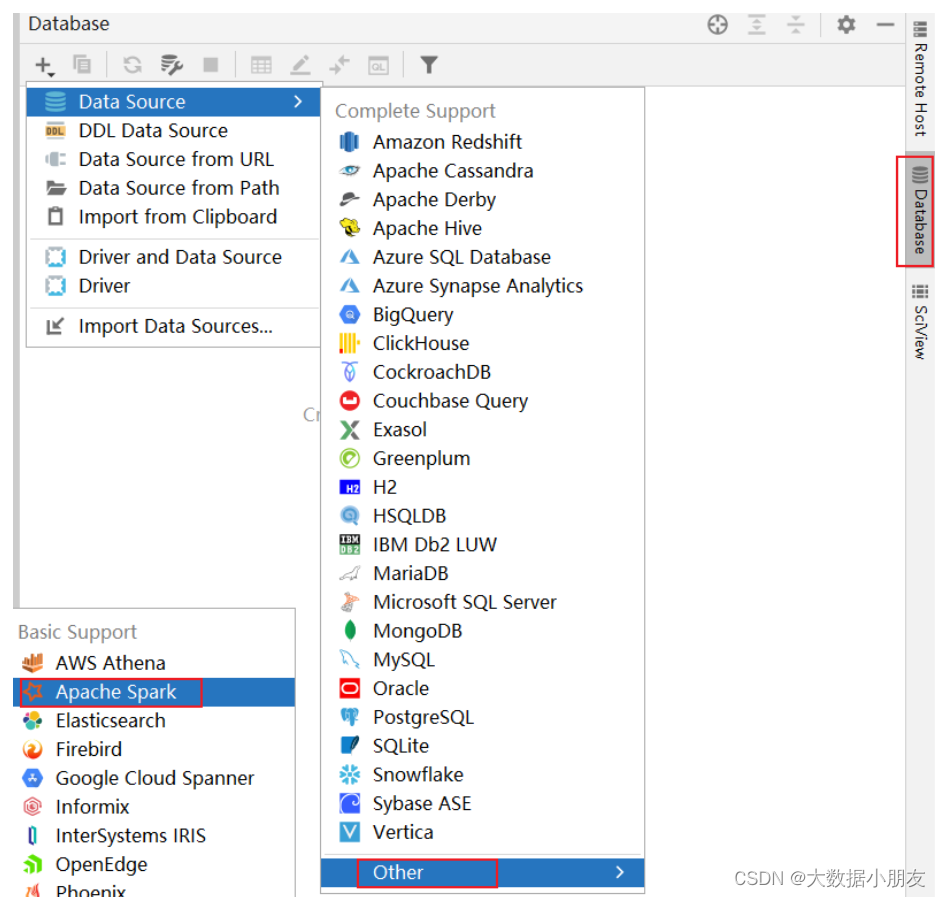
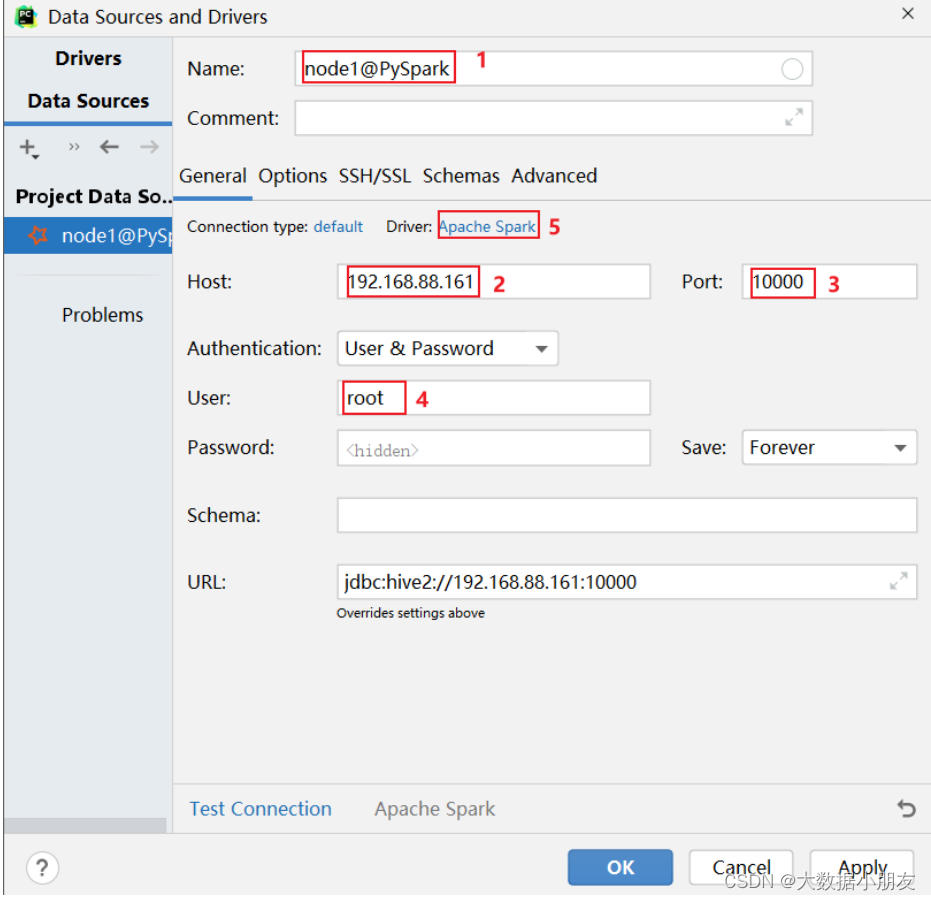
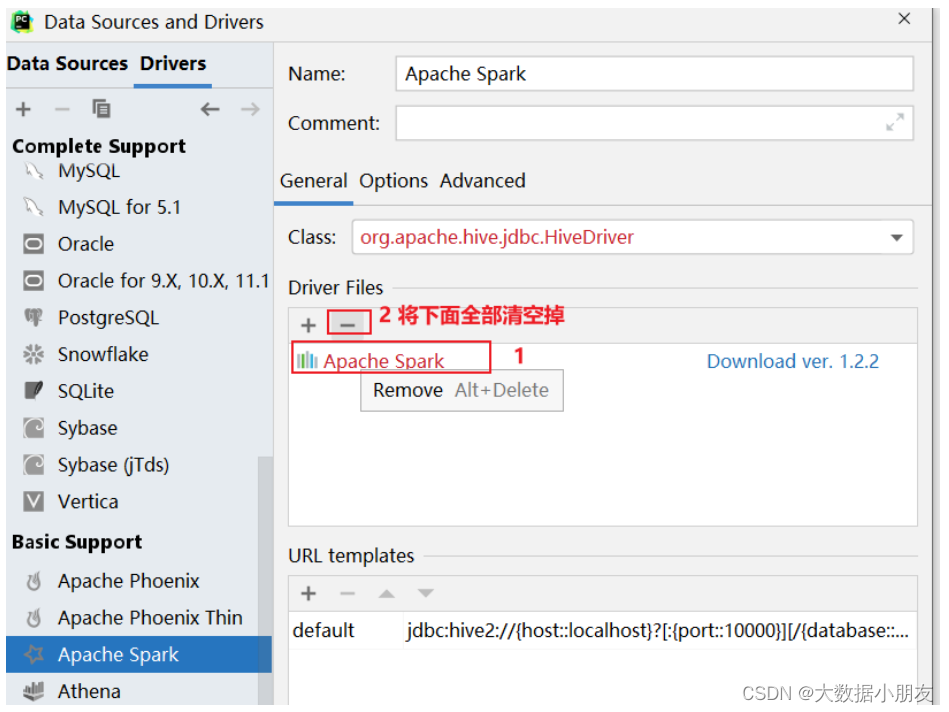
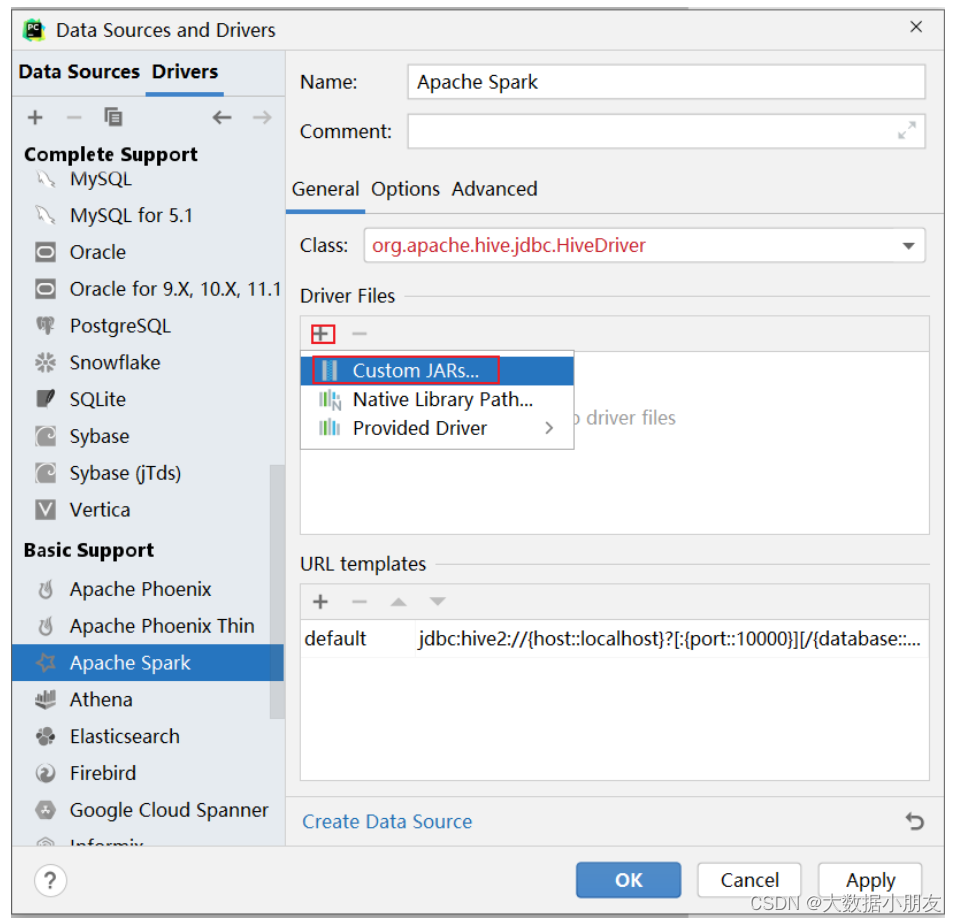
博主已经上传资源:

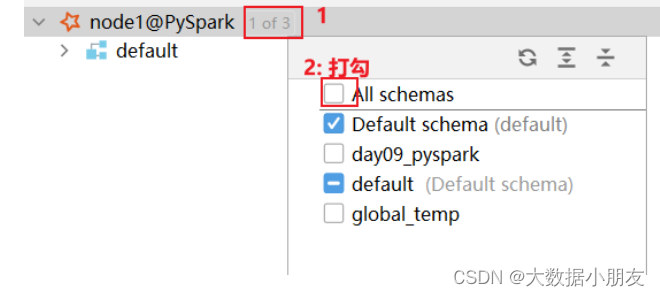
4、控制台编写SQL代码
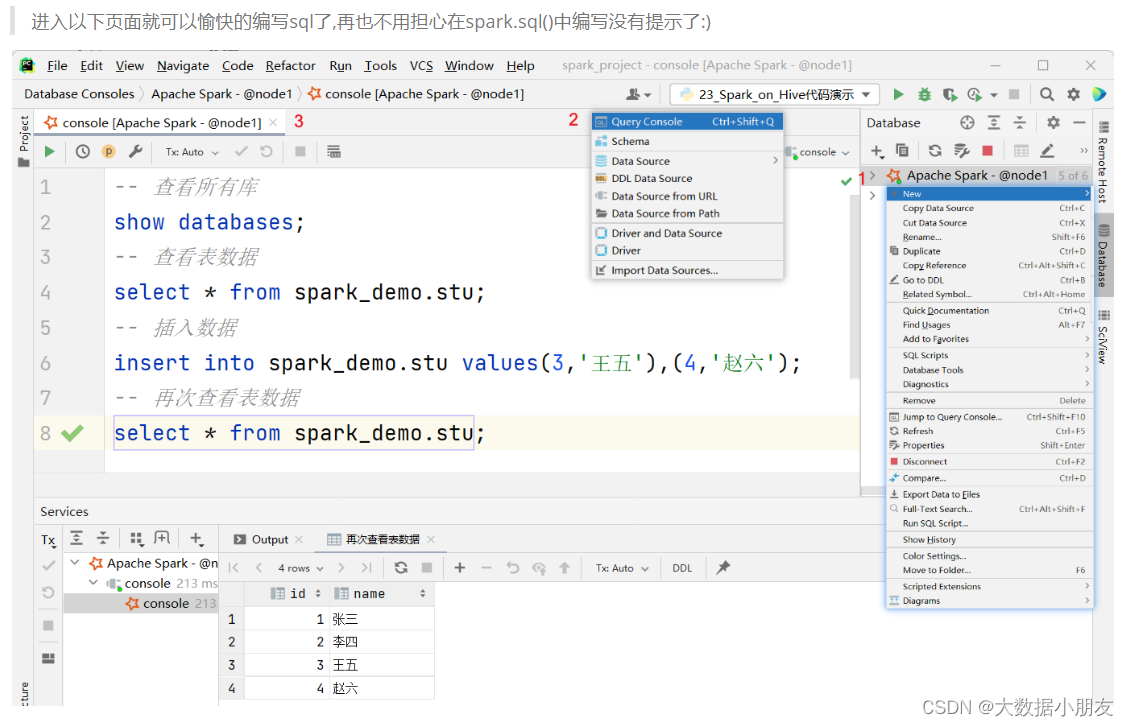
进入以下页面就可以愉快的编写sql了,再也不用担心在spark.sql()中编写没有提示了:)