技术点梳理0618
ann建库,分布式建库,性能优化,precision recall参数优化
hnsw,图索引
1. build
a)确定层:类似跳表思路建立多层,对每一个插入的节点,random层号l,从图的起始点search_layer(ef=1)到l+1层(自顶向下)的最近邻近点
b)确定边:遍历l到0层(继续向底部搜索),search_layer(ef)找到最邻近ef个点,选择最邻近的M个点,建立双向边
c)裁剪-防止稠密:遍历M个点如果节点的邻节点超过Mmax仅保留最近的边
2. search(q)
a) 快速游走到比较近的节点:自顶向下搜索到最底层search_layer(ef=1)
b) 贪心ann:建立两个集合,候选集队列C、最近邻队列W(队列长度为ef),从C里拿出距离q最近的节点c,如果可以更新W(距离小于W的对尾)就遍历c的邻节点来更新W
分布式建库(全增量):流批一体化,全量、批次增量、实时增量
- dump系统,产出全量、增量
- 离线构建系统有两个任务
-
- processor负责读取全量/增量数据源并对每条doc处理,用加库的模型embedding成向量,归一化,写入swift(类似kafka)
- builder,以及在线服务会订阅swift,builder服务本地根据partition构建HNSW索引,产出全量和批次增量,分片检索
- 实时索引
-
- query dnn服务与searcher服务统一管控,item dnn加载到processor中量化
- hnsw支持插入,但不支持删除,改用软删除
性能优化
- 联合检索,带条件的向量检索
- query cache
- 在gpu中计算向量相似度
precision recall参数优化
- 建立ann与knn的准召率,比如直接在线抽样回放
- 最近邻超参tradeoff,参数越大准召率越高性能越差
- 距离公式,不能使用内积(不满足三角不等式,开根号),要用欧式距离,检索时转成内积
实时索引建库,结合item生命周期(新建实时生效,低pv item,失效item处理)的索引管理
分布式索引构建通常包括全量、批次增量、实时增量。数据join平台通过流批一体化生产全量和增量,其中增量通过swift消息分发到召回服务,所有的update操作会转成软delete后再add操作,会导致实时增量的索引增长非常迅速。
低pv item处理:item有2亿,分为了excellent、normal库,先seek excellent库,再用normal库补足,其中今天新发商品进excellent库
失效item处理:软delete,增量索引中bitmap标记doc是否存在,到多段索引合并时再真正delete
model serving优化,包括feature store设计(考虑特征版本号管理、实时特征读写更新、过期特征处理)、深度学习模型推理优化、模型运维管理
model serving优化
- op fusion、op placement
feature store:
- 用户特征中特征穿越问题
模型运维:
- 模型更新:模型增量训练后(ODL一样),model check auc(可能会训飞),发布到rtp灰度集群做打分平均判断,验证通过再部署到rtp online集群
- 模型发布:fg离在线一致性,模型打分离在线一致性
搜索引擎架构整体优化
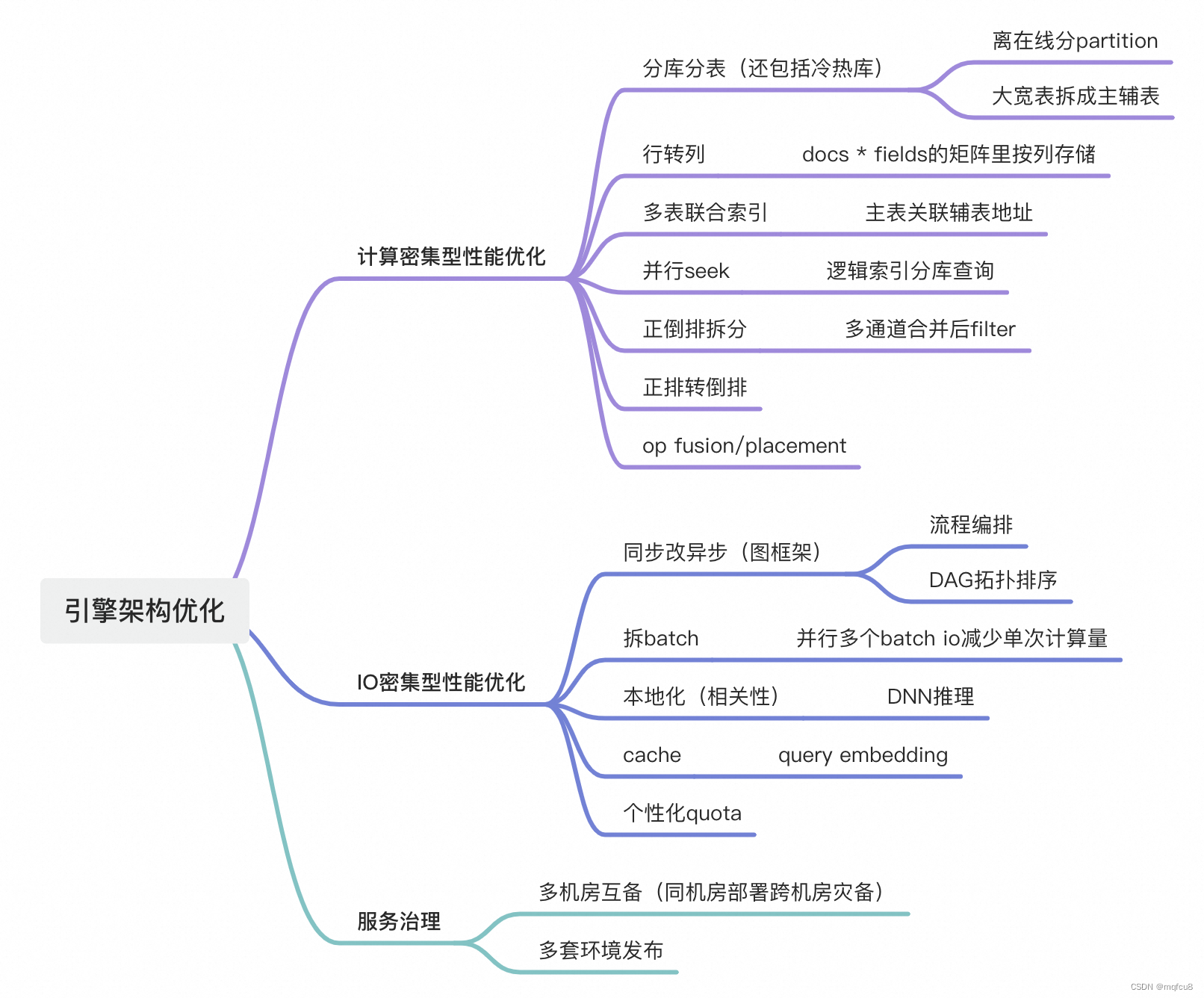
失量检索引擎,设计细节
vector search,ann索引(ivf、hnsw)、index,几个特点:
- 分库和伸缩:离在线两部分,在线为两层分布式架构(qrs、searcher),离线对主键分片构建索引,分发到searcher集群,qrs将请求拆为多个,quota被均分后*1.2系数下发searcher召回过滤
- 多表join联合索引形成大宽表:在索引构建时主表添加辅表索引,seek主表不需查询辅表正排而是通过辅表地址获取正排值执行filter,既实现了大宽表又将拆表建索引。并且在seek阶段,多条索引链交并集seek(其中并集采用小根堆),边seek边filter,filter对象提前映射到对应正排索引,从多次寻址优化到1次寻址,这样的seek模式能保障有效召回量
- DAG图执行与模型推理统一:基于tensorflow框架,基于op schema自定义算子,组图实现流程编排。执行时DAG拓扑排序并行执行op,基于docid有序,可以分段并行seek&filter,减少rt。searcher load相关性dnn模型,本地完成推理,避免相关性服务IO
- ann检索:支持实时增量
- 分布式索引构建:在processor任务中加item塔,对doc量化,写入swift消息中间件,builder任务会读取,同时在线服务也会读取
- 在线实时增量构建:update操作会转成delete再add,但delete只是软删除,ivf/hnsw的add跟离线没差异,所以实时索引增长很快,需要用批次索引覆盖
- 在线查询:最近邻超参tradeoff,参数越大准召率越高性能越差,对比ann与knn的准召率调节超参