LLM中表格处理与多模态表格理解
文档处理中不可避免的遇到表格,关于表格的处理问题,整理如下,供各位参考。
问题描述
RAG中,对上传文档完成版式处理后进行切片,切片前如果识别文档元素是表格,那么则需要对表格进行处理。一般而言,表格处理分成三个部分:
- TD任务,Table Detection,表格识别
- TSR任务,Table Structure Recognition,表格结构识别
- TCD任务,Table Content Recognition,表格内容识别
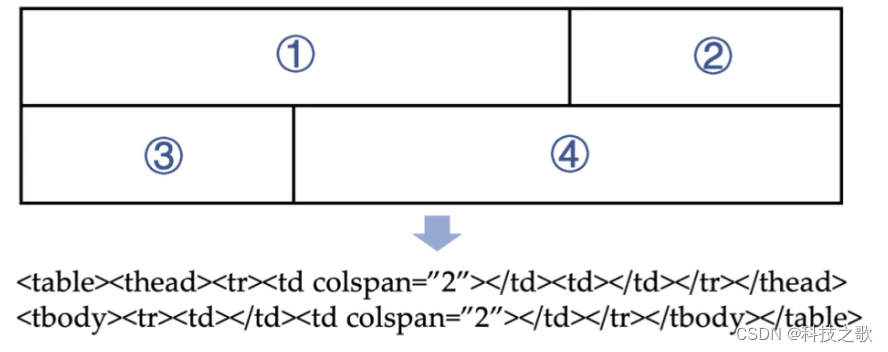
表格检测任务是识别文档中的表格元素;表格结构识别则是理解表格的布局和结构;而表格内容识别则是提取表格中的具体数据。这些任务共同构成了表格处理的完整流程。目前主要的思路是通过识别到表格,将表格转化为结构化文本信息,比如HTML或者Markdown,再利用LLM对结构化文本的泛化能力进行分析和处理。
然而,在现实世界的一些场景中,获取高质量的文本表格表示可能比较困难,而表格图像则更容易获取。因此,如何直接使用直观的视觉信息来理解表格是一个关键且迫切的挑战。

多模态表格理解的思路
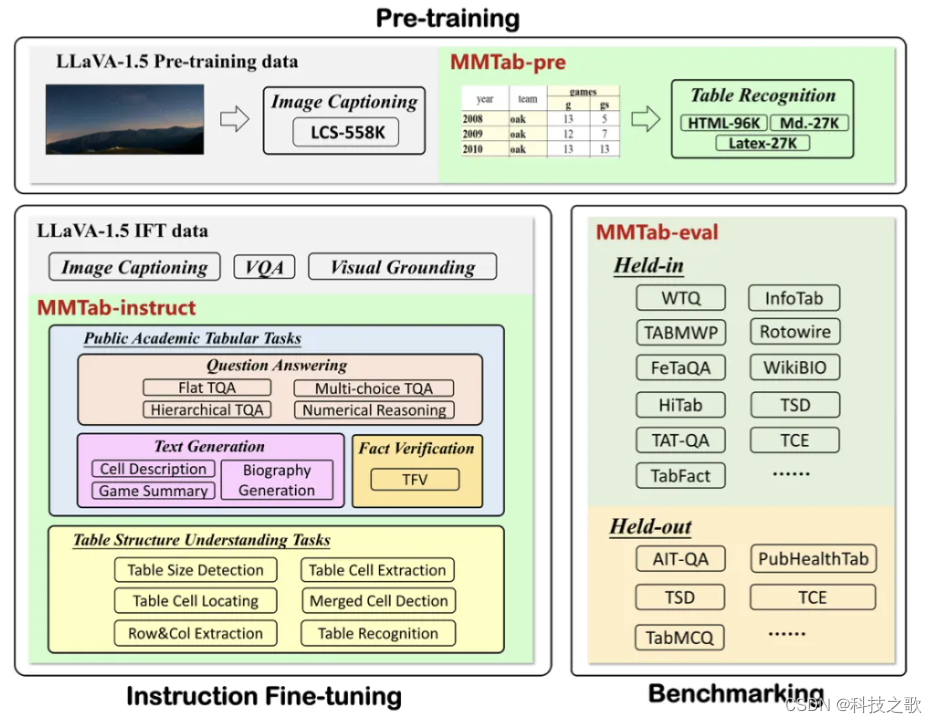
多模态表格理解指的是结合文本、图像等多种模态信息来理解表格内容。在文本表格表示难以获取的情况下,如何利用直观的视觉信息来理解表格是一个很好的研究方向。为了解决多模态表格理解问题,构建了一个名为MMTab的大规模数据集,涵盖了广泛的表格图像、指令和任任务,为多模态表格理解提供了丰富的实验场景。MMTab数据集的设计思路和数据构造方式,为研究者提供了新的视角和工具,以应对多模态表格理解中的各种挑战。
《Multimodal Table Understanding》,代码放在:https://github.com/SpursGoZmy/Table-LLaVA
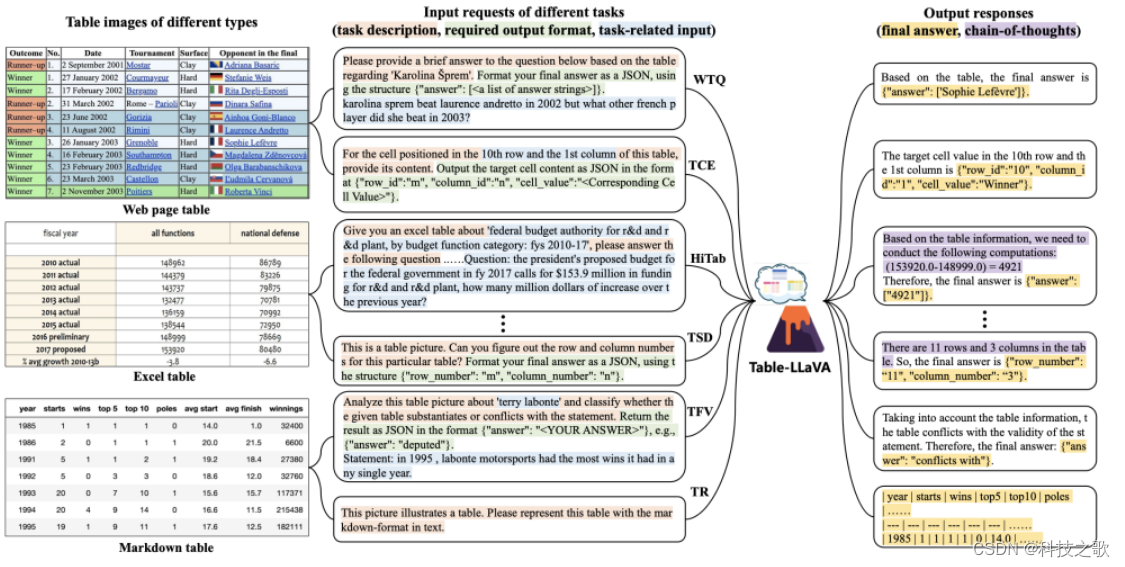
1、其数据构造的方式:
比较有趣的是做的数据增强方案:
其一,表格级别增强(Table-level augmentations):现实世界的表格具有不同的结构和样式。为了使模型能够处理各种样式的表格,设计了脚本来渲染具有三种不同样式的表格图像:网页风格(Web-page,占比70.8%)、Excel风格(占比19.4%)和Markdown风格(占比9.8%)。还考虑细粒度的调整,如字体类型和单元格颜色。
其二,指令级别增强(Instruction-level augmentations):用户对于同一任务的指令可能会有所不同。为了提高模型对这种变化的鲁棒性,作者使用GPT-4生成新的指令模板和关于JSON输出格式的描述,基于几个手动注释的示例进行少量样本(few-shot)学习。生成的指令模板如果包含语法错误或与原始任务偏离,将被过滤掉。
其三,任务级别增强(Task-level augmentations):尽管收集的14个公共数据集突出了9个学术表格任务,这些任务需要基于表格的推理能力,但现有的多模态大型语言模型(MLLMs)是否真的理解基本的表格结构仍然是一个问题。 为了进一步加强MLLMs对基本表格结构的理解能力,设计了6个表格结构理解任务,例如表格大小检测(TSD)任务。
除了上述策略,作者还将同一表格的单轮样本结合起来,构成了37K多轮对话样本。

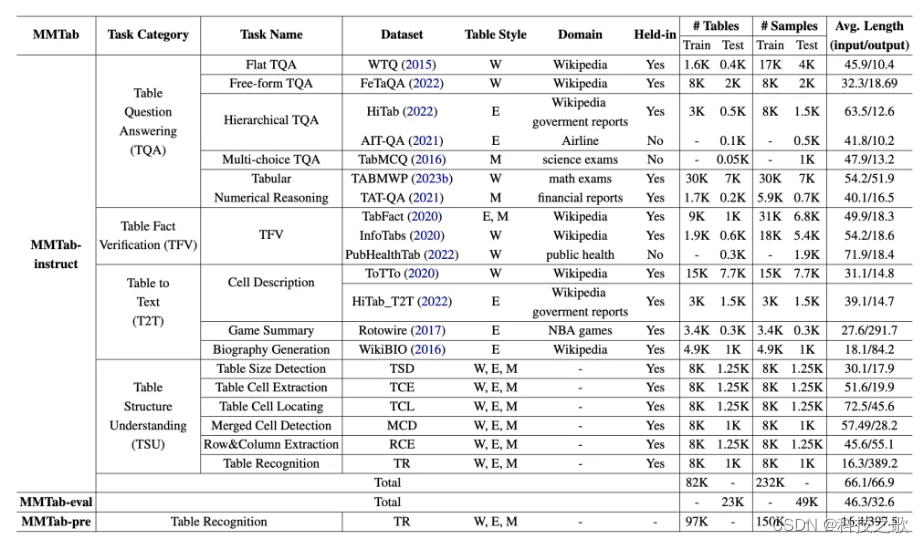
2、数据的具体统计,包括用于微调的数据集以及测试
MMTab数据集包括150K样本用于预训练,232K样本用于指令微调,以及45K和4K样本分别用于内部和外部评估。
数据集中包含了105K张表格图像,这些图像覆盖了广泛结构(例如,具有平坦结构的简单表格以及具有合并单元格和分层标题的复杂表格)。数据集中的表格图像不仅结构多样,还具有不同的风格(网页、Excel、Markdown表格)和来自不同领域的数据(如维基百科和财务报告)。
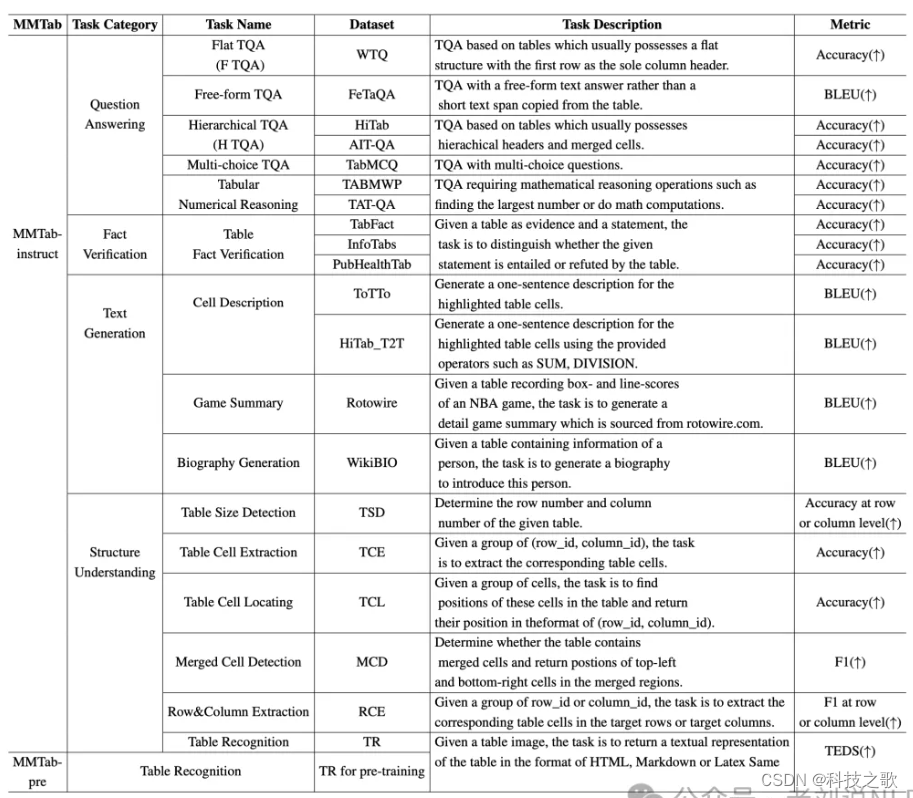
3、benchmark的计算方式
4、进行对应的微调路线
论文中开发了一个通用的表格MLLM Table-LLaVA,使用MMTab-instruct数据集,该数据集包含了多种与表格相关的任务,例如问题回答(TQA)、事实验证(TFV)、文本生成(T2T)等,模型基于之前提出的LLaVA-1.5模型。
总结
多模态表格处理是一种集成了视觉、文本和结构化数据等多种信息源的技术,旨在更全面地理解和解析表格内容。随着深度学习、大型语言模型等技术的不断进步,多模态表格理解的性能将得到显著提升。
1、多模态表格处理需要强大的视觉识别能力,以识别和解析表格的视觉布局,包括行列、单元格合并等。涉及到图像处理和模式识别技术,如使用深度学习模型来检测表格边界和单元格结构。
2、文本理解是多模态处理的另一关键方面。表格中的文本信息需要通过自然语言处理技术来提取和理解,包括实体识别、关系抽取和语义分析等,以捕捉表格中的数据和它们之间的联系。
3、结构化数据的整合对于多模态表格处理同样重要。将视觉识别的表格结构与文本内容相结合,转化为结构化的数据库格式,可以进一步促进数据的分析和应用。
4、多模态表格处理还应考虑到数据的多样性和复杂性。不同的表格可能来自不同的来源,具有不同的格式和风格。因此,处理系统需要具备高度的灵活性和适应性,以应对各种不同的输入。
此外,随着数据集的不断丰富和完善,模型的泛化能力和适应性也将得到加强。多模态表格处理的未来发展方向可能包括更深层次的语义理解、更智能的数据融合策略,以及更广泛的应用场景,如自动化报告生成、智能数据分析等。
参考资料:
文档表格结构识别技术与数据总结:兼看多模态表格理解基准设计及数据构建思路
《A Study on Reproducibility and Replicability of Table Structure Recognition Methods》
《Deep Learning for Table Detection and Structure Recognition: A Survey》
《TableVLM: Multi-modal Pre-training for Table Structure Recognition》
《Improving Table Structure Recognition with Visual-Alignment Sequential Coordinate Modeling》