14.基于人类反馈的强化学习(RLHF)技术详解
基于人类反馈的强化学习(RLHF)技术详解
RLHF 技术拆解
RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,我们按三个步骤分解:
- 预训练一个语言模型 (LM) ;
- 训练一个奖励模型 (Reward Model,RM) ;
- 用强化学习 (RL) 方式微调 LM。

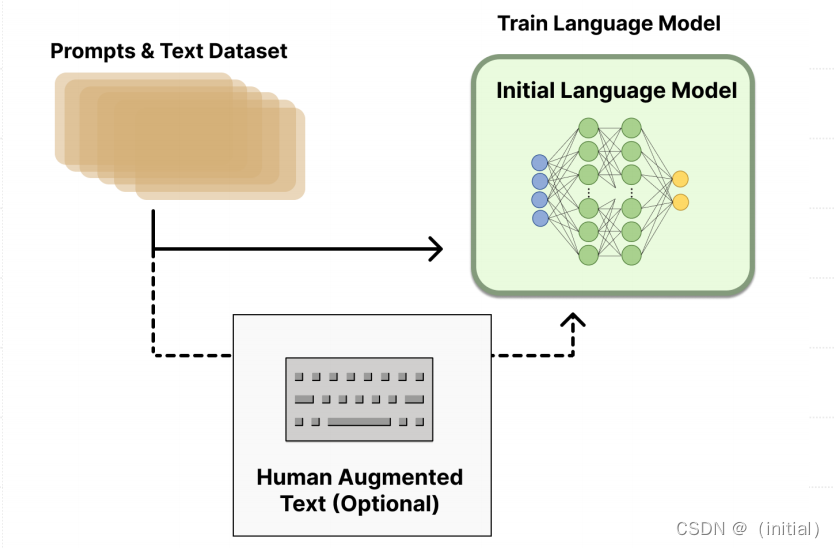
步骤一:使用SFT微调预训练语言模型
先收集⼀个提示词集合,并要求标注⼈员写出⾼质量的回复,然后使⽤该数据集以监督的⽅式微调预训练的基础模型。对这⼀步的模型,OpenAI 在其第⼀个流⾏的 RLHF 模型 InstructGPT 中使⽤了较⼩版本的 GPT-3; Anthropic 使⽤了 1000 万 ~ 520 亿参数的 Transformer 模型进⾏训练;DeepMind 使⽤了⾃家的 2800 亿参数模型 Gopher。
步骤二:训练奖励模型(Reward Model)
RM 的训练是 RLHF 区别于旧范式的开端。这⼀模型接收⼀系列⽂本并返回⼀个标量奖励,数值上对应⼈的偏好。我们可以⽤端到端的⽅式⽤ LM 建模,或者⽤模块化的系统建模 (⽐如对输出进⾏排名,再将排名转换为奖励) 。这⼀奖励数值将对后续⽆缝接⼊现有的 RL 算法⾄关重要。

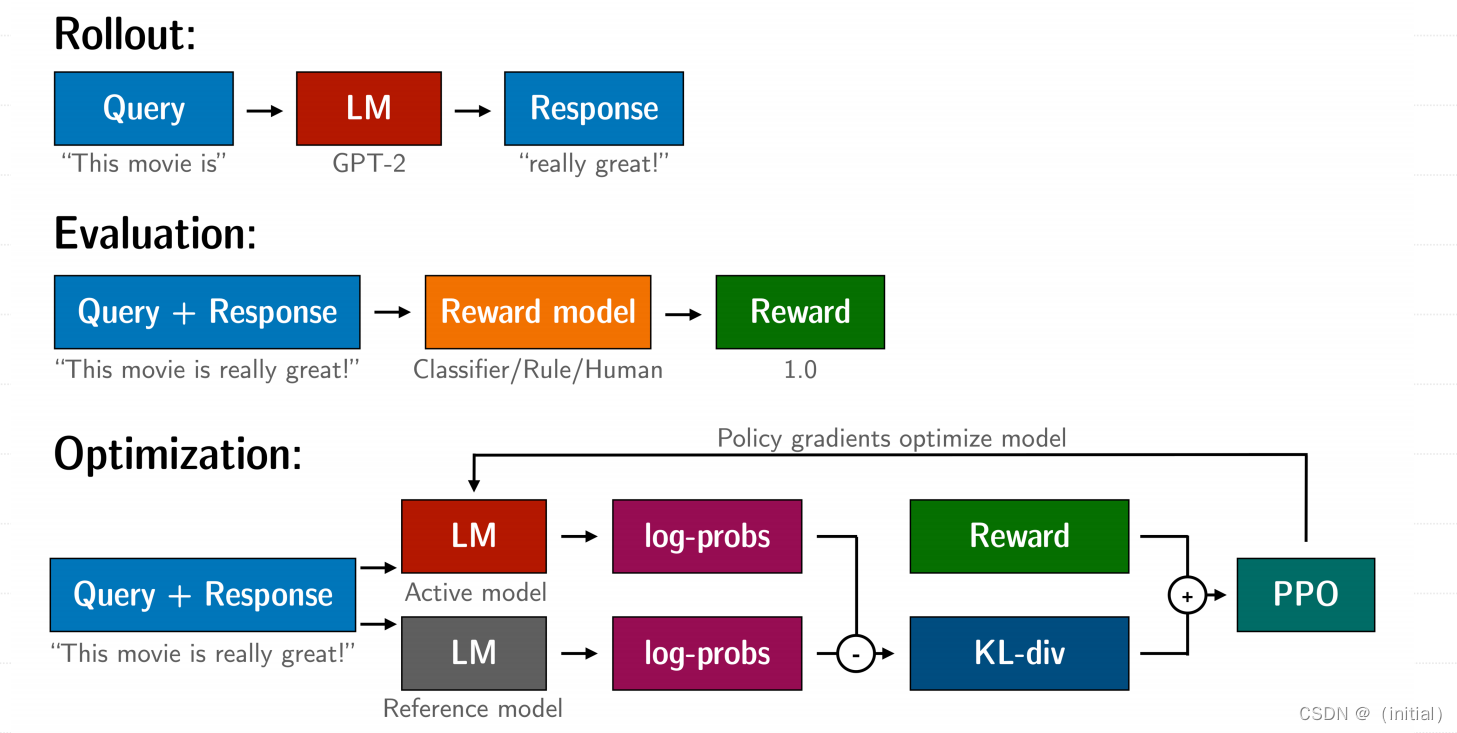
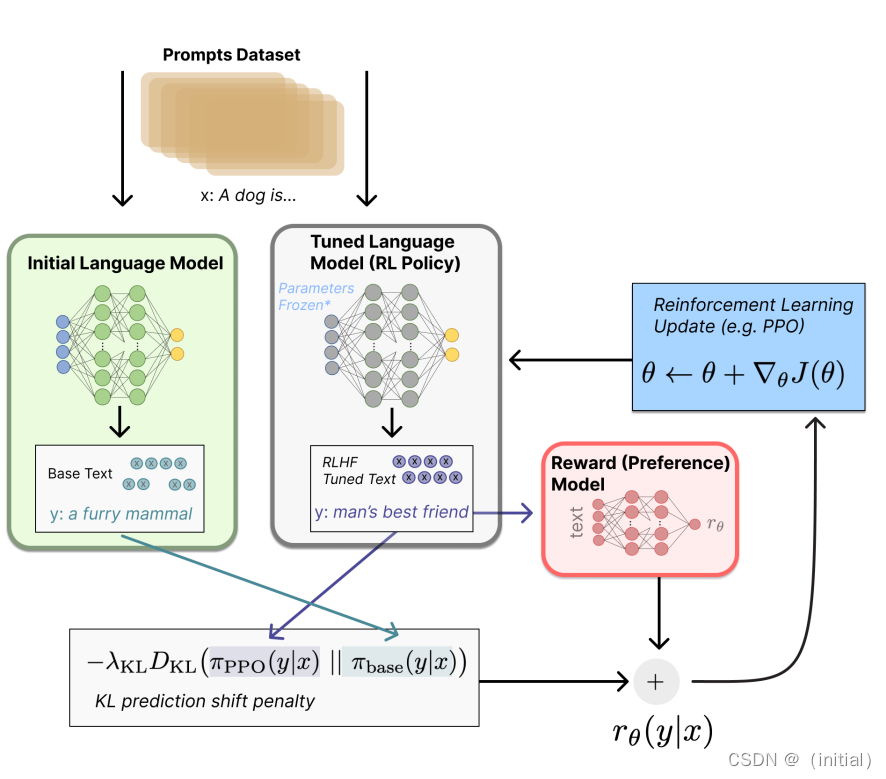
步骤三:使用 PPO 优化微调语言模型
将微调任务表述为 RL 问题:
首先,该策略 (policy) 是一个接受提示并返回一系列文本 (或文本的概率分布) 的 LM。这个策略的行动空间 (action space) 是 LM 的词表对应的所有词元 (一般在 50k 数量级)
观察空间 (observation space) 是可能的输入词元序列,也比较大 (词汇量 ^ 输入标记的数量) 。
奖励函数是偏好模型和策略转变约束 (Policy shiftconstraint) 的结合。
PPO 算法确定的奖励函数具体计算如下:将提示 x 输入初始 LM 和当前微调的 LM,分别得
到了输出文本 y1, y2,将来自当前策略的文本传递给 RM 得到一个标量的奖励 rθ 。将两个模型的生成文本进行比较计算差异的惩罚项KL散度。
这一项被用于惩罚 RL 策略在每个训练批次中生成大幅偏离初始模型,以确保模型输出合理连贯的文本。如果去掉这一惩罚项可能导致模型在优化中生成乱码文本来愚弄奖励模型提供高奖励值
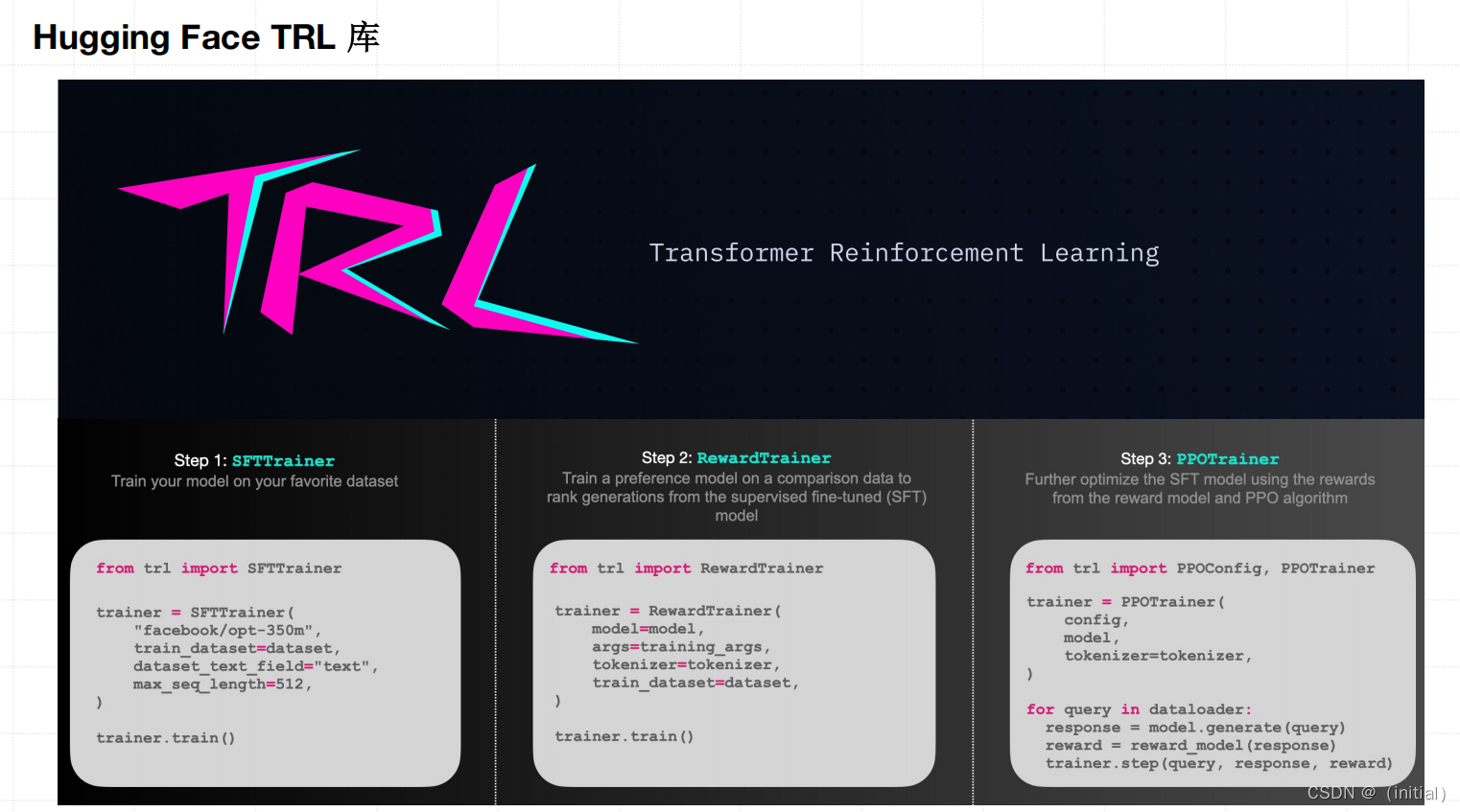
使用 Hugging Face TRL 实现 PPO 流程图解