KafkaQ - 好用的 Kafka Linux 命令行可视化工具
软件效果前瞻 ~
鉴于并没有在网上找到比较好的linux平台的kafka可视化工具,今天为大家介绍一下自己开发的在 Linux 平台上使用的可视化工具KafkaQ
虽然简陋,主要可以实现下面的这些功能:
1)查看当前topic的分片数量和副本数量
2)查看当前topic下面每个分片的最大offset
3)查看当前topic某个分片下面指定offset范围的数据
4)搜索当前topic指定关键词的message
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++

KafkaQ分为普通版本和搜索版本:
* 普通版本支持上述3种查询
* 搜索版本支持上述3种查询之外,增加关键词搜索,即在分片中搜索指定关键词的message
一、普通版 KafkaQ.sh

使用方法:
Usage: KafkaQ.sh --topic<topic> [--partition<partition>] [--offset<offset>] [--limit<limit>]--topic 话题名称
--partition 分片索引(可选)
--offset 从第k个offset开始检索(可选)
--limit 从第k个offset开始检索X条结果(可选)显示的效果如下,十分简洁,分片数据里面左边一列是消息入库的时间,右边是message内容:

KafkaQ 源码如下:
#!/bin/bash# 默认值
PARTITION=${2:-0}
OFFSET=${3:-0}
LIMIT=${4:-0}# 检查参数
if [ -z "$1" ]; thenecho "Usage: $0 --topic<topic> [--partition<partition>] [--offset<offset>] [--limit<limit>]"exit 1
fiTOPIC="$1"# 检查Kafka命令是否存在
if ! command -v /usr/local/kafka/bin/kafka-topics.sh >/dev/null 2>&1; thenecho "Kafka not found at /usr/local/kafka/bin/"exit 1
fi# 获取Topic信息
echo -e "\033[0;31m* 话题: $TOPIC\033[0m"# 获取分区数和副本数
PARTITION_INFO=$(/usr/local/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic "$TOPIC")
PARTITION_COUNT=$(echo "$PARTITION_INFO" | awk '/Partition:/ {print $2}' | wc -l)
REPLICA_COUNT=$(echo "$PARTITION_INFO" | grep -oP 'ReplicationFactor: \K\d+')echo "* 分片: $PARTITION_COUNT, 副本: $REPLICA_COUNT"# 获取分片a和分片b的最大偏移量
MAX_OFFSET=$(/usr/local/kafka/bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic "$TOPIC" | awk -F: '{ printf " 分片: %s,MaxOffset: %s\n", $2, $3 }')
echo "$MAX_OFFSET"# 获取分片数据
if [ "$LIMIT" -gt 0 ]; thenecho -e "\033[0;33mFetching messages from partition $PARTITION with offset $OFFSET and limit $LIMIT ...\033[0m"MESSAGES=$(/usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic "$TOPIC" --partition "$PARTITION" --offset "$OFFSET" --max-messages "$LIMIT" --property print.key=true --property print.value=true --property print.timestamp=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.StringDeserializer)# 格式化输出消息echo "$MESSAGES" | awk -F'\t' 'BEGIN {print "* 分片数据:"}{if ($3 != "null") {timestamp = substr($1, 12) / 1000 # 从第10个字符开始提取时间戳,并除以1000以转换为秒级时间戳value = $3printf "\033[0;33m%s\033[0m %s\n", strftime("%Y-%m-%d %H:%M:%S", timestamp), value}}'
fi
二、搜索版 KafkaQ-Search.sh
使用方法:
Usage: KafkaQ-Search.sh --topic<topic> [--partition<partition>] [--offset<offset>] [--limit<limit>] [--search<keyword>]--topic 话题名称
--partition 分片索引(可选)
--offset 从第k个offset开始检索(可选)
--limit 从第k个offset开始检索X条结果(可选)
--search 搜索字符串示例(所有参数是必选的哦):
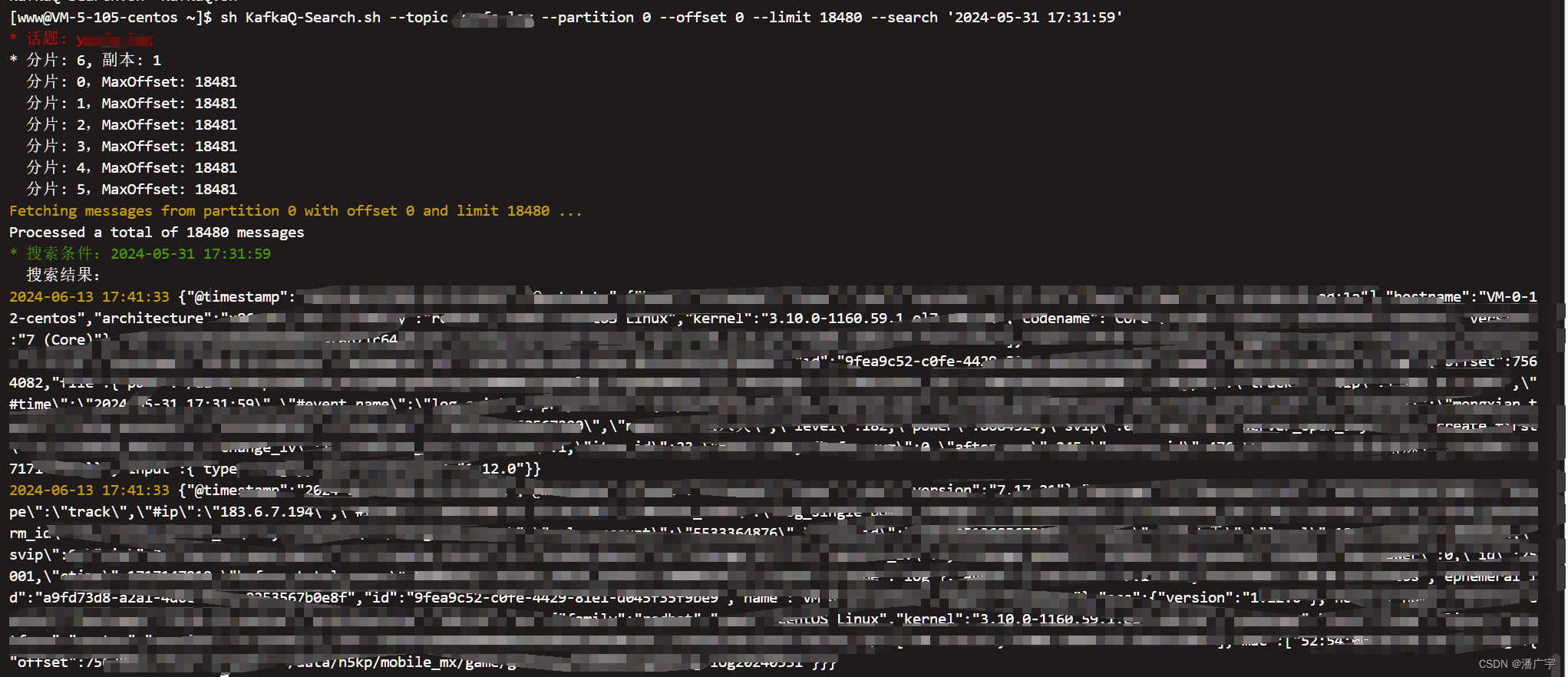
sh KafkaQ-Search.sh --topic log --partition 0 --offset 0 --limit 18480 --search '9fea9c52-c0fe-4429-81e1-d045f35f9be9'显示效果如下:

KafkaQ-Search.sh 源码如下:
#!/bin/bash# 默认值
PARTITION=${2:-0}
OFFSET=${3:-0}
LIMIT=${4:-0}
SEARCH=${5:-""}# 检查参数
if [ -z "$1" ]; thenecho "Usage: $0 --topic<topic> [--partition<partition>] [--offset<offset>] [--limit<limit>] [--search<keyword>]"exit 1
fiwhile [[ $# -gt 0 ]]; docase "$1" in--topic)TOPIC="$2"shift 2;;--partition)PARTITION="$2"shift 2;;--offset)OFFSET="$2"shift 2;;--limit)LIMIT="$2"shift 2;;--search)SEARCH="$2"shift 2;;*)echo "Unknown parameter: $1"exit 1;;esac
done# 检查Kafka命令是否存在
if ! command -v /usr/local/kafka/bin/kafka-topics.sh >/dev/null 2>&1; thenecho "Kafka not found at /usr/local/kafka/bin/"exit 1
fi# 获取Topic信息
echo -e "\033[0;31m* 话题: $TOPIC\033[0m"# 获取分区数和副本数
PARTITION_INFO=$(/usr/local/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic "$TOPIC")
PARTITION_COUNT=$(echo "$PARTITION_INFO" | awk '/Partition:/ {print $2}' | wc -l)
REPLICA_COUNT=$(echo "$PARTITION_INFO" | grep -oP 'ReplicationFactor: \K\d+')echo "* 分片: $PARTITION_COUNT, 副本: $REPLICA_COUNT"# 获取分片a和分片b的最大偏移量
MAX_OFFSET=$(/usr/local/kafka/bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic "$TOPIC" | awk -F: '{ printf " 分片: %s,MaxOffset: %s\n", $2, $3 }')
echo "$MAX_OFFSET"# 获取分片数据
if [ "$LIMIT" -gt 0 ]; thenecho -e "\033[0;33mFetching messages from partition $PARTITION with offset $OFFSET and limit $LIMIT ...\033[0m"MESSAGES=$(/usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic "$TOPIC" --partition "$PARTITION" --offset "$OFFSET" --max-messages "$LIMIT" --property print.key=true --property print.value=true --property print.timestamp=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.StringDeserializer)# 搜索关键词并输出结果if [[ ! -z $SEARCH ]]; thenecho -e "\033[0;32m* 搜索条件:$SEARCH\033[0m"echo " 搜索结果:"echo "$MESSAGES" | grep --color=never "$SEARCH" | awk -F'\t' '{timestamp = substr($1, 12) / 1000 # 从第12个字符开始提取时间戳,并除以1000以转换为秒级时间戳value = $3printf "\033[0;33m%s\033[0m %s\n", strftime("%Y-%m-%d %H:%M:%S", timestamp), value}'fi
fi
* (附注)参考的shell如下
1、获取kafka的topic 分区数量
/usr/local/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic <topic>2、获取kafka每个分片最大的offset
/usr/local/kafka/bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic <topic>3、获取kafka分片指定offset范围的具体信息
/usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic <topic> --partition <partition> --offset <offset> --max-messages <max-message> --property print.key=true --property print.value=true --property print.timestamp=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.StringDeserializer