Golang编译导致的代码错觉
文章目录
- 背景
- 分析代码
- 疑问
- 直接上汇编
- gdb调试优化后的汇编
- staticunit64s
- 查看禁止优化后的汇编
- 查看编译过程的SSA
- 生成SSA
- b对应的SSA
- c对应的SSA
- go官方文档的解释
- 对比C语言的表现
- 总结
背景
网上看到一段代码,来源是Golang 编译器优化那些事,百思不得其解。本篇文章主要是分析以下代码,一方面是知其然知其所以然,另一方面也是避免以后掉进类似的深坑。
分析代码
func main() {var a byte = (1 << uint(len(s))) / 128 // 编译器计算var b byte = (1 << uint(len(s[:]))) / 128 // 运行时计算, 溢出了var c byte = byte(int(1<<uint(len(s[:]))) / 128) // 运行时计算,用int 所以没有溢出fmt.Println(a, b, c)
}# 输出结果
a:4
b:0:
c:4
从直觉上来看a,b,c的行为应该是类似的,区别是a的len(s)可以直接获取到长度,b和c因为涉及到切片操作,需要在runtime层计算。但这个结果还是很费解。
疑问
- a在汇编的时候表现是什么样子的?为什么说是编译器计算?
- b为什么是0,512/128=4才对? 为什么是0?
- c和b的行为也不一样,只是多了个int类型转换
- 以上行为出现的理论支撑是什么
直接上汇编
# 带优化的编译
go build -o demo ./demo.go
# 输出汇编,查看demo的main函数
go tool objdump -S -s main.main demo# 结果
func main() {0x4808e0 493b6610 CMPQ SP, 0x10(R14)0x4808e4 7673 JBE 0x4809590x4808e6 55 PUSHQ BP0x4808e7 4889e5 MOVQ SP, BP0x4808ea 4883ec58 SUBQ $0x58, SPfmt.Println(a, b, c)
从最终汇编上看不出来什么东西,因为编译器做了太多优化。我们可以用gdb调试去查看生成的汇编以及对应的代码行,会更加清晰一些。
关于gdb调试go程序可以参考我之前的文章:Golang汇编之通过map地址找到value的值_golang如何获取map中的每个value-CSDN博客
gdb调试优化后的汇编
gdb demo // 开始调试
b main.main // 打断点
run // 运行程序
layout split // 查看源码和汇编
si // 根据汇编指令一次一行的查看
结果如下: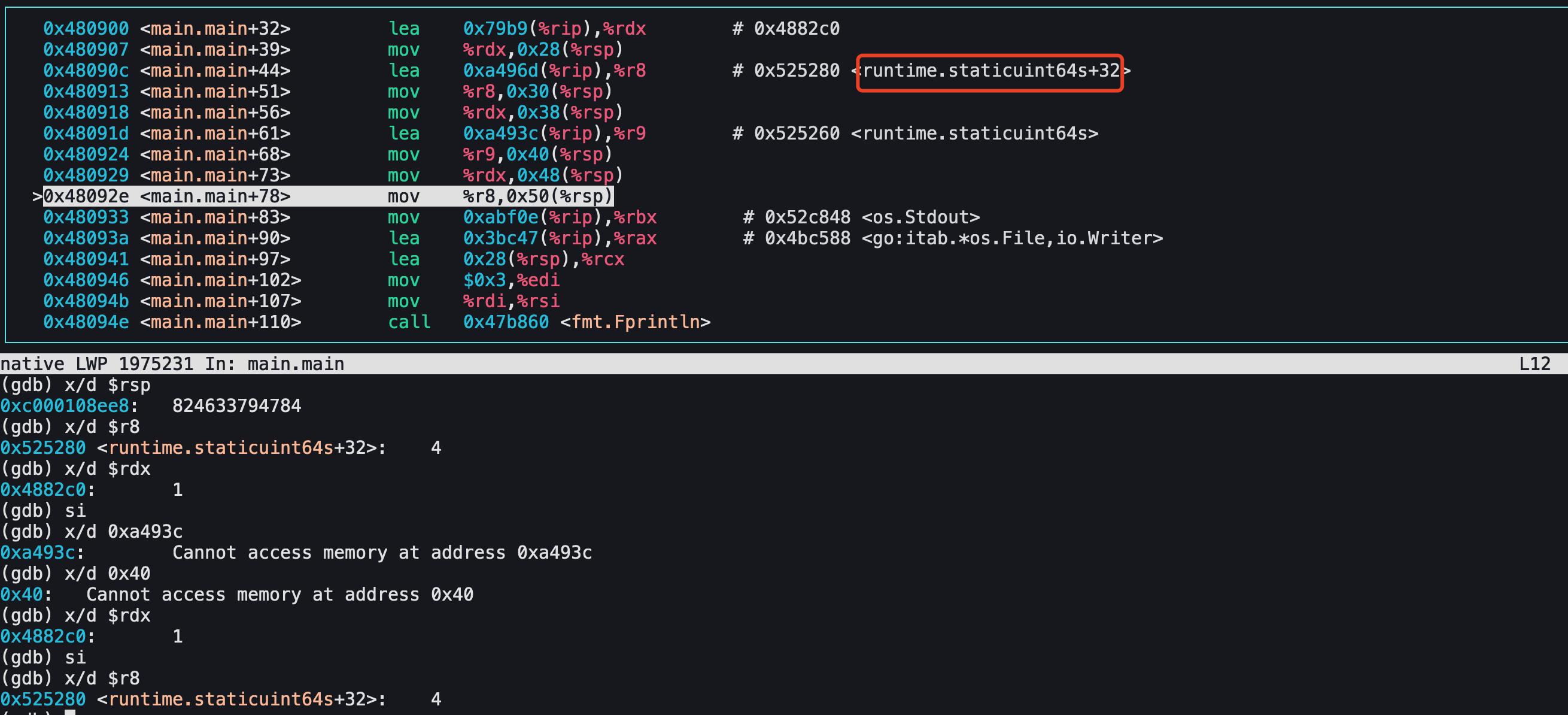
- abc在最终汇编中都是常量,编译器做过优化了
- 以上汇编看不到内部都经过哪些转换以及runtime层都做了什么
- 出现了runtime.staticunit64s? 这个是什么意思?
staticunit64s
在go源码中通过rg搜索 staticunit64s,发现在runtime/iface.go中有如下代码。
看起来是为了避免分配小整数值。这里一共有256个,通过地址偏移量来找到0-255的值。
例如上面汇编中的staticuint64s+32意思是偏移32为,打印地址结果确实是4.

可以参考: https://g4s8.wtf/posts/go-low-latency-one/
查看禁止优化后的汇编
# 编译命令: go build -gcflags="-S -N -l" demo.goFUNCDATA $2, main.main.stkobj(SB)MOVB $4, main.a+33(SP)LEAQ go:string."123456789"(SB), DXMOVQ DX, main..autotmp_3+120(SP)MOVQ $9, main..autotmp_3+128(SP)MOVQ $9, main..autotmp_4+40(SP)MOVB $0, main.b+32(SP)LEAQ go:string."123456789"(SB), DXMOVQ DX, main..autotmp_3+120(SP)MOVQ $9, main..autotmp_3+128(SP)MOVQ $9, main..autotmp_4+40(SP)MOVB $4, main.c+31(SP)
这里可以看到,变量a直接作为常量赋值了。
变量b和变量c是有计算过程的,但是有一些注意的点:
MOVQ: 用于将64位的数据从源操作数移动到目标操作数。
MOVB: 用于将8位的数据从源操作数移动到目标操作数。
从代码上也能理解,毕竟我们的a,b,c类型都是byte类型,使用MOVB是合适的。
main…autotmp_3-16(SP) 和 main.b-112(SP) 实际上指向堆栈指针 SP 的偏移位置。autotmp_xx是 runtime 临时变量,反映当前栈帧指针位置。
所以现在的疑问变成了中间计算过程的临时变量类型是什么?是int还是byte?
查看编译过程的SSA
生成SSA
GOSSAFUNC=main go build -gcflags="-N -l" ./demo.go
默认会在当前目录生成个ssa.html,我们可以浏览器打开查看。
b对应的SSA

可以看到中间计算过程的临时变量类型都是byte。那么基本上破案了,byte的类型范围是0-255,我们中间计算的1 << 9的结果是512,从这一步开始就溢出了,所以结果为0. 0/128的结果还是0,因此b=0!
c对应的SSA

可以看到在计算c的时候,因为有int转换类型,中间变量类型都是int类型,因此没有溢出。
go官方文档的解释
以上go编译器的行为理论上来说都能从go的文档中找到蛛丝马迹。我们可以搜索"go spec"来查看文档。
说实话没有找到直接关于这部分的描述,只有以下一句比较符合:
链接: https://go.dev/ref/spec#Constants
An untyped constant has a default type which is the type to which the
constant is implicitly converted in contexts where a typed value is
required, for instance, in a short variable declaration such as
i := 0 where there is no explicit type. The default type of an
untyped constant is bool, rune, int, float64, complex128,
or string respectively, depending on whether it is a boolean, rune,
integer, floating-point, complex, or string constant.
对于没有明确类型指定的常量来说,会默认转换成目标类型,也就是byte.
虽然可以这么理解,但仍然是比较反直觉的,我们可以看看c语言的表现如何。
对比C语言的表现
#include <stdio.h>
#include <string.h>
#include <stdint.h> // For uint8_t// b=4
void calculate_and_print_b_4(char* s) {unsigned char b = (1 << strlen(s)) / 128;printf("b: %u\n", b);
}// b=0
void calculate_and_print_b_0(char* s) {unsigned char b = (uint8_t)(1 << strlen(s)) / 128;printf("b: %u\n", b);
}int main() {char s[] = "123456789";calculate_and_print_b_0(s);return 0;
}
通过gcc编译,然后运行查看:
gcc test.c
./a.out
我们可以看到,如果仿照go的写法,默认输出是4,而不是0.
C语言是计算结束,然后转换成目标类型,和go的表现不一样,更符合直觉。
如果想重现b=0也简单,直接把中间的类型强制转换成uint8即可。
总结
为什么要分析这段程序,主要是觉得坑挺多的,一不小心代码就会出bug,而且还是难以排查的bug。想要避免类似的问题,要么是熟悉go的规范,要么就是尽量写一些“朴实无华”的代码。
越发明白大佬说的那句话,编程语言玩到最后玩的就是规范。虽然go的规范有点晦涩难懂,但我们可以通过遇到的问题去跟规范对照起来理解,也算是一种进步的方式吧。
尽量不要错过深究的机会,也许深究下去会得到更多呢?
end