Hive---sqoop安装教程及sqoop操作
sqoop安装教程及sqoop操作
文章目录
- sqoop安装教程及sqoop操作
- 上传安装包
- 解压并更名
- 添加jar包
- 修改配置文件
- 添加sqoop环境变量
- 启动
- sqoop操作
- 查看指定mysql服务器数据库中的表
- 在hive中创建一个teacher表跟mysql的mysql50库中的teacher结构相同
- 将mysql中mysql50库中的sc数据导出到hdfs指定的文件目录中
- sqoop -m 参数
- 带条件过滤
- 带条件过滤,指定查询列
- query使用
- 将mysql50中sc表导入到hive bigdata库中
- 重写,原数据会被覆盖
- 增量导入
上传安装包
这里两个安装包 sqoop-1.4.7 bin_hadoop-2.6.0.tar.gz和sqoop-1.4.7.tar.gz
因为hadoop版本为3.1.3 所以sqoop的版本太低,需要自行配置


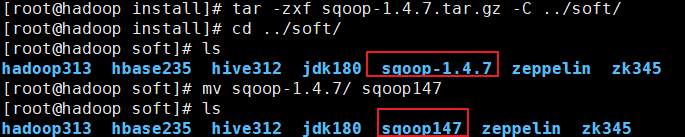
解压并更名
# 解压
[root@hadoop install]# tar -zxf sqoop-1.4.7.tar.gz -C ../soft/
# 切换目录
[root@hadoop install]# cd ../soft/
# 更名
[root@hadoop soft]# mv sqoop-1.4.7/ sqoop147
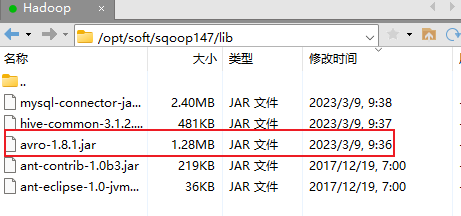
添加jar包
切换目录到 /opt/soft/sqoop147/lib/
添加avro-1.8.1.jar
# 将hive312/lib下的两个jar包拷贝过来
[root@hadoop lib]# cp /opt/soft/hive312/lib/hive-common-3.1.2.jar ./
[root@hadoop lib]# cp /opt/soft/hive312/lib/mysql-connector-java-8.0.29.jar ./

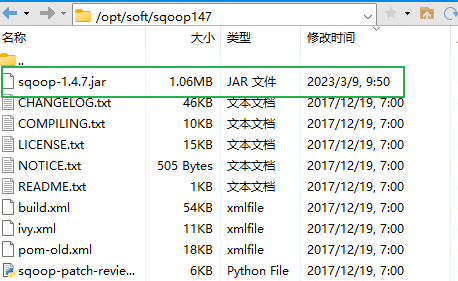
将sqoop-1.4.7.jar 拷贝到 /opt/soft/sqoop147/

修改配置文件
切换到cd /opt/soft/sqoop147/conf
# 将配置文件复制并更名
[root@hadoop conf]# cp sqoop-env-template.sh sqoop-env.sh
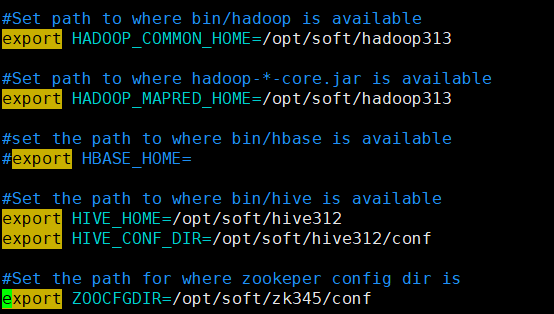
# 编辑 sqoop-env.sh
[root@hadoop conf]# vim ./sqoop-env.sh 22 #Set path to where bin/hadoop is available23 export HADOOP_COMMON_HOME=/opt/soft/hadoop31324 25 #Set path to where hadoop-*-core.jar is available26 export HADOOP_MAPRED_HOME=/opt/soft/hadoop31327 28 #set the path to where bin/hbase is available29 #export HBASE_HOME=30 31 #Set the path to where bin/hive is available32 export HIVE_HOME=/opt/soft/hive31233 export HIVE_CONF_DIR=/opt/soft/hive312/conf34 35 #Set the path for where zookeper config dir is36 export ZOOCFGDIR=/opt/soft/zk345/conf

添加sqoop环境变量
# 编辑/etc/profile
[root@hadoop conf]# vim /etc/profile
# SQOOP_HOME
export SQOOP_HOME=/opt/soft/sqoop147
export PATH=$PATH:$SQOOP_HOME/bin
# 刷新文件
[root@hadoop conf]# source /etc/profile

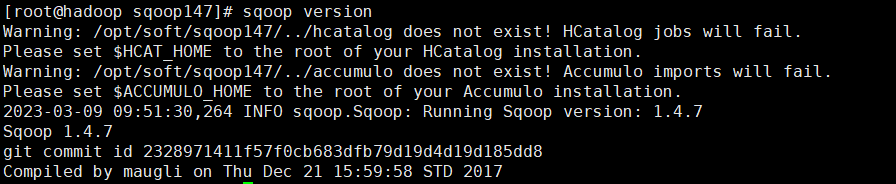
启动
[root@hadoop conf]# sqoop version
sqoop操作
\ 符号为连接符
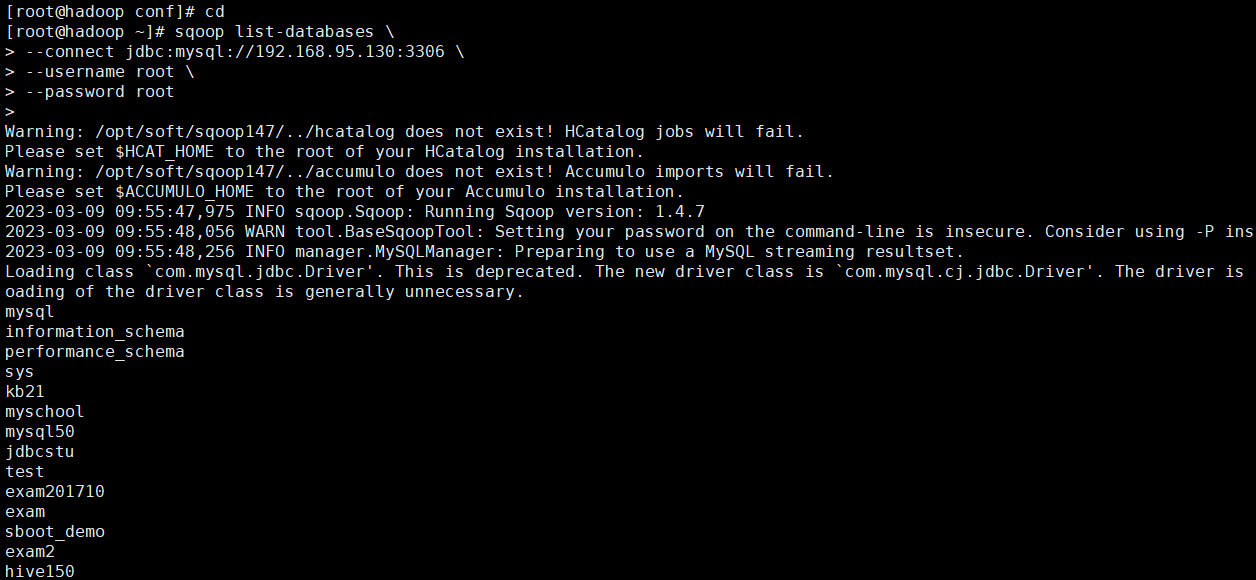
查看指定mysql服务器数据库中的表
[root@hadoop ~]# sqoop list-databases --connect jdbc:mysql://192.168.95.130:3306 --username root --password root
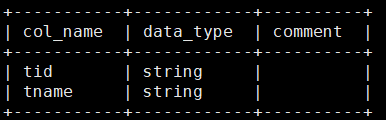
在hive中创建一个teacher表跟mysql的mysql50库中的teacher结构相同
[root@hadoop ~]# sqoop create-hive-table --connect jdbc:mysql://192.168.95.130:3306/mysql50 --username root --password root --table teacher --hive-table teacher
将mysql中mysql50库中的sc数据导出到hdfs指定的文件目录中
[root@hadoop ~]# sqoop import --connect jdbc:mysql://192.168.95.130:3306/mysql50 --username root --password root --table sc --target-dir /tmp/mysql50/sc --fields-terminated-by '\t' -m 1
sqoop -m 参数
sqoop并行化是启多个map task实现的,-m(或–num-mappers)参数指定map task数,默认是四个。当指定为1时,可以不用设置split-by参数,不指定num-mappers时,默认为4,当不指定或者num-mappers大于1时,需要指定split-by参数。并行度不是设置的越大越好,map task的启动和销毁都会消耗资源,而且过多的数据库连接对数据库本身也会造成压力。在并行操作里,首先要解决输入数据是以什么方式负债均衡到多个map的,即怎么保证每个map处理的数据量大致相同且数据不重复。–split-by指定了split column,在执行并行操作时(多个map task),sqoop需要知道以什么列split数据,其思想是:
1、先查出split column的最小值和最大值2、然后根据map task数对(max-min)之间的数据进行均匀的范围切分
带条件过滤
[root@hadoop ~]# sqoop import --connect jdbc:mysql://192.168.95.130:3306/mysql50 --username root --password root --table sc --where "SID='01'" --target-dir /tmp/mysql50/sid01 -m 1
带条件过滤,指定查询列
[root@hadoop ~]# sqoop import --connect jdbc:mysql://192.168.95.130:3306/mysql50 --username root --password root --table sc --columns "CID,score" --where "SID='01'" --target-dir /tmp/mysql50/sid01column -m 1
query使用
[root@hadoop ~]# sqoop import --connect jdbc:mysql://192.168.95.130:3306/mysql50 --username root --password root --target-dir /tmp/mysql50/scquery --query 'select * from sc where $CONDITIONS and CID="02" and score>80 ' --fields-terminated-by '\t' -m 1
注意:如果使用–query这个命令的时候,需要注意的是where后面的参数, AND $ CONDITIONS 这个参数必须加上而且存在单引号与双引号的区别,如果–query后面使用的是双引号,那么需要在$CONDITIONS前加上 \即 \ $ CONDITIONS
如果设置map数量为1个时即-m 1,不用加上–split-by ${tablename.column},否则需要加上
将mysql50中sc表导入到hive bigdata库中
[root@hadoop ~]# sqoop import --connect jdbc:mysql://192.168.95.130:3306/mysql50 --username root --password root --table sc --hive-import --hive-database bigdata -m 1
重写,原数据会被覆盖
[root@hadoop~]# sqoop import --connect jdbc:mysql://192.168.95.130:3306/mysql50 --username root --password root --table sc --hive-import --hive-overwrite --hive-database bigdata -m 1
增量导入
[root@hadoop ~]# sqoop import --connect jdbc:mysql://192.168.95.130:3306/mysql50 --username root --password root --table sc --hive-import --incremental append --hive-database bigdata -m 1