STEEL ——首个利用 LLM 检测假新闻的框架算法解析
1.概述
近年来,假新闻的泛滥确实对政治、经济和整个社会产生了深远的负面影响。为了解决这一问题,人们开发了各种假新闻检测方法,这些方法试图通过分析新闻内容、来源和传播方式来识别虚假信息。
然而,正如你所提到的,现有的假新闻检测方法存在一些局限性。其中一个主要问题是它们通常依赖于静态资料库,如维基百科,这导致它们在处理新出现的新闻和索赔时存在困难,因为这些资料库可能没有最新的信息。
为了克服这些挑战,研究人员开始探索利用大型语言模型(LLM)的能力。LLMs因其在自然语言处理任务中的卓越表现而受到关注,它们能够理解、推理并生成语言,这为假新闻检测提供了新的可能性。
尽管如此,基于LLM的解决方案也面临着一些挑战,例如信息可能过时,以及在检索低质量信息和处理长上下文时的能力受限。
在这种背景下,你提到的STEEL框架是一个创新的尝试,它利用了LLMs的推理能力来进行自动信息检索,以增强假新闻的检测能力。STEEL框架可能是第一个尝试将LLMs的推理和生成能力与信息检索相结合的系统,以提高假新闻检测的准确性和效率。
论文地址:https://arxiv.org/pdf/2403.09747.pdf
2.STEEL 算法架构
LLM(Large Language Models,大型语言模型)确实在多个领域展现出了卓越的能力,包括自然语言理解、文本生成、翻译、问答系统等。在假新闻检测领域,它们也被证明是有用的工具。
**RAG(Retrieval-Augmented Generation,检索增强生成)**是一种结合了检索和生成的方法,它允许模型从外部知识库中检索相关信息,并将这些信息整合到生成的输出中。这种方法特别适用于假新闻检测,因为它可以提供额外的上下文和证据来帮助评估新闻的真实性。
然而,这种方法也面临一些挑战:
- 依赖有限数据源的局限性:如果检索到的信息不全面或有偏差,可能会影响假新闻检测的准确性。
- 在瞬息万变的新闻环境中进行实时更新的困难:新闻内容不断更新,而模型需要能够快速适应这些变化,以提供准确的检测。
针对这些挑战,本文提出的**STEEL(Strategic Extraction and Evaluation of Evidence with Large Language models,用大语言模型增强的战略检索)**框架是一个创新的解决方案。STEEL基于多轮LLM的RAG框架,它通过以下方式解决上述难题:
- 搜索模块:STEEL可能包含一个专门的搜索模块,用于从互联网上检索与新闻相关的最新信息。
- 搜索引擎:通过直接与搜索引擎集成,STEEL能够访问更广泛的信息源,并可能实现实时更新,以适应新闻环境的快速变化。
下图显示了算法架构:
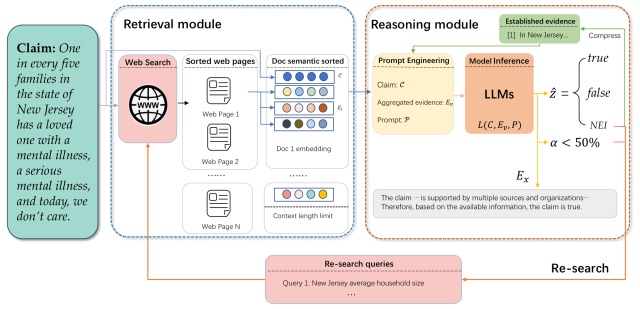
如图所示,STEEL 主要包括两个主要模块,即检索模块和****推理模块,这两个模块被整合成一个综合的再研究机制框架。
检索模块
检索模块通过搜索引擎搜索可确定为假新闻的证据来源,并根据相似性对检索到的文件和输入信息(即 “权利要求”)进行排序。
该源代码实施了基本的过滤机制,并根据现有研究使用 1044 个已知假新闻网站的列表作为过滤器。
推理模块
从网络上检索到的可确定为假新闻的信息源被汇总为提示信息,并提供给 LLM 进行推理。
然后,LLM 会根据给定的信息源进行评估,包括决定是否有必要重新搜索,并输出true(真)、false(假)或 NEI(信息不足 = 信息不够)的结果。
再搜索机制
如果上述 "推理 "模块产生了下图所示的 “NEI”,就会判定没有足够的信息来确定新闻是假的,并重新进行调查。

重新审查首先会合并在初始搜索中收集到的资料来源,并将其添加到名为**"既定证据 “的资料库中以供参考。
接下来,会设置"更新查询**”,目的是检索更多相关信息,并将新信息添加到查询中。
其机制是,通过重复这种方法,模型逐渐建立起判断假新闻的证据体系,并提高模型辨别新闻真伪的能力。
3. 实验
为了评估 STEEL 的性能,我们在三个真实世界的数据集上进行了广泛的实验,其中包括两个英文数据集LIAR 和****PolitiFact,以及一个中文数据集CHEF。(这些数据集分为真实新闻和虚假新闻两类)。
此外,本实验共使用了 11 个模型,包括 7 个基于证据的方法和 4 个基于 LLM 的方法,如下所示。
- 证据基础(G1):七个: DeClarE、HAN、EHIAN、MAC、GET、MUSER****和 ReRead。
- 基于 LLM(G2): GPT-3.5-Turbo**、Vicuna-7B、WEBGLM****和 ProgramFC**。
假新闻检测是一个二元分类问题,以F1****、精确度、召回率、F1 宏****和 F1 微作为评估标准。
实验结果如下表所示。
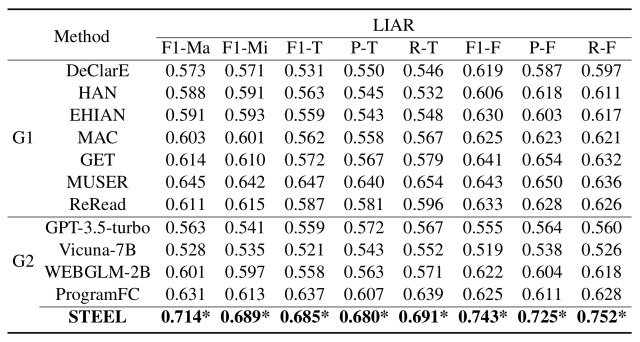
该表证实,**在所有方法中,STEEL 的得分最高,在三个真实世界数据集中,F1 宏观和 F1 微观得分都提高了 5%**以上。
从这个实验中可以看出,STEEL 在检测假新闻方面非常有效,在推理和准确性方面都有显著优势。
4. 总结
STEEL框架在假新闻检测方面取得了积极的进展,并且通过大规模实验显示出其性能优于现有的假新闻检测方法。这是一个重要的成就,因为它表明利用大型语言模型(LLMs)进行自动信息检索和推理是检测假新闻的有效途径。
然而,文章也指出了STEEL框架目前的一些局限性,特别是它目前仅涉及文本数据。在假新闻的传播中,文本只是众多媒介之一。为了更全面地识别和分析假新闻,需要考虑以下方面:
-
多模态信息的整合:假新闻可能包含图像、视频和音频等多种媒介形式。扩展STEEL框架,使其能够处理和分析这些非文本数据,将有助于提高检测的准确性和全面性。
-
上下文理解:图像、视频和音频中的视觉和听觉线索可以提供额外的上下文信息,有助于理解新闻内容的真实性。
-
跨模态分析:通过跨模态分析,可以更好地理解文本内容与图像、视频和音频之间的关系,从而提高假新闻检测的准确性。
-
实时更新和适应性:随着技术的不断进步,STEEL框架需要能够适应新的媒介形式和传播方式,以保持其有效性。
-
用户交互和反馈:用户反馈可以作为评估新闻真实性的一个额外维度,帮助模型学习和改进。
通过解决这些挑战,STEEL框架不仅能够提高假新闻检测的准确性,还能够增强新闻的整体可靠性。这将有助于构建一个更加健康和可信的信息生态系统,减少假新闻对社会的负面影响。未来的工作可能会集中在如何将STEEL框架扩展到多模态数据的处理,以及如何通过用户交互和反馈来进一步优化模型的性能。