存内计算与扩散模型:下一代视觉AIGC能力提升的关键
目录
前言
视觉AIGC的ChatGPT4.0时代
扩散模型的算力“饥渴症”
存内计算解救算力“饥渴症”
结语
前言

在这个AI技术日新月异的时代,我们正见证着前所未有的创新与变革。尤其是在视觉内容生成领域(AIGC,Artificial Intelligence Generated Content),技术的每一次飞跃都意味着更加逼真、创意无限的数字艺术作品的诞生。自动生成内容的愿景日益成为现实。视觉领域,尤其是在图像和视频生成技术的进步,正引领着创意产业进入一个崭新的纪元。从消费者能够体验的个性化媒体到企业需求的定制广告素材,AIGC技术正逐渐变得无处不在。在这个迅速演进的技术领域中,存内计算与Diffusion Models(扩散模型)联手,正在成为下一代视觉AIGC能力提升的关键。
视觉AIGC的ChatGPT4.0时代

2022年11月,OpenAI宣布发布了ChatGPT,这是一个基于大规模语言模型的聊天机器人,它标志着大语言模型发展的一个重要里程碑。ChatGPT的推出不仅在技术爱好者和开发者社区中引起了轰动,而且在终端消费者中也引起了极大的兴趣。这种聊天机器人凭借其自然的对话能力、广泛的知识理解和灵活的响应,展现出了人工智能在自然语言处理方面的巨大进步。ChatGPT的横空出世不仅意味着技术的突破,它还引发了对未来发展的广泛思考。大语言模型如GPT-3展示了机器学习模型处理复杂语言任务的能力,这不限于简单的问答,还包括文本生成、翻译、文本摘要和其他语言相关的多个方面。这些大模型正在逐渐从研究实验室走入商业应用,为不同的行业带来变革,如教育、客户服务、娱乐和法律咨询等领域。
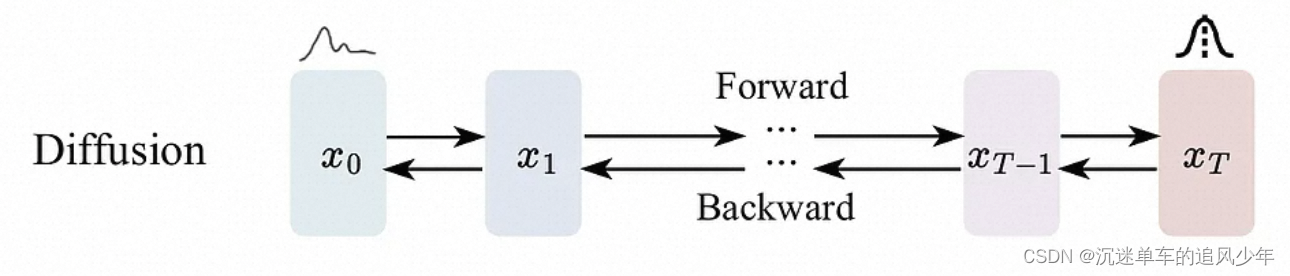
然而,尽管视觉模型的发展速度相对较慢,近期Diffusion Models技术的突破,特别是以Stable Diffusion为代表的开源模型的提出,正在改变这一现状。Diffusion Models是一种生成模型,它通过逐步引入噪声并在反向过程中去除噪声来生成数据。与传统的生成对抗网络(GANs)相比,Diffusion Models在图像质量、多样性和可控性方面展现出了显著的优势。传统的生成对抗网络(GANs)自从被提出以来,就因其强大的生成能力而受到广泛关注。然而,GANs 也存在一些局限性,例如训练过程不稳定、模式崩溃(mode collapse)问题,以及难以控制生成内容的问题。相比之下,Diffusion Models 作为一种新型的生成模型,采用了不同的生成机制。它们通过模拟数据的扩散过程,然后学习逆向过程来生成新的样本。
除了Diffusion Models本身在图像生成领域的突破,Runway公司的Stable Diffusion开源模型的出现,为技术的普及和应用带来了深远的影响。Stable Diffusion模型以其出色的性能和易用性,进一步推动了视觉AIGC技术的快速发展,并为广泛的用户群体提供了前所未有的便利。作为开源模型,允许研究者和开发者自由访问、修改和分发代码。这种开放性促进了技术的快速迭代和创新,降低了参与门槛,使得更多的人能够参与到这一领域的研究和开发中。
可以说,视觉AIGC虽然在发展速度上可能一度未展现出如大语言模型那般迅猛的势头,但在Diffusion Models及类似Stable Diffusion这样的开源项目的强力驱动下,它正以前所未有的活力和创造力,逐步缩小这一差距并开拓出独特的技术路径与应用场景。
扩散模型的算力“饥渴症”

当前限制扩散模型发展一个重要原因就是算力“饥渴症”。随着模型大小的增加及其应用领域的扩展,对算力的需求呈指数级增长,这就导致了一种对计算资源的极端“饥渴”。扩散模型工作原理中的迭代过程,需要大量的计算步骤来逐渐构建目标输出。每一步都依赖于前一步的输出,这种渐进式的生成过程涉及到大量的矩阵运算和参数调整,因此对算力的需求极高。此外,扩散模型通常含有数十亿甚至数万亿的参数,对训练数据进行学习和生成新数据时需要巨量的并行计算能力。
存内计算解救算力“饥渴症”

因此急需新的计算架构、全新的计算模式来解救扩散模型的算力“饥渴症”。存内计算技术提供了一种潜在的解决方案。存内计算技术的基本思想是将数据计算移动到存储器中,实现原位计算,消除带宽限制和数据传输成本。
神经网络的训练是一个计算密集和资源消耗巨大的过程。传统上,这个过程涉及到大量的参数,这些参数在训练过程中需要不断地进行更新和优化以达到更好的预测准确率。这不仅对计算能力提出了高要求,同时也造成了计算效率的瓶颈。特别是在训练大模型如扩散模型时,这一问题更加显著。在传统的计算架构中,处理器(如CPU或GPU)执行计算任务,而计算所需的数据和参数通常存储在外部内存(RAM)中。当处理器需要访问这些数据时,数据需要从内存搬运到处理器中。由于神经网络模型特别是大型模型涉及到的参数极多,这就导致了频繁的数据搬运。在处理器等待数据搬运的过程中,计算资源并没有得到充分利用,从而降低了整体的计算效率和训练速度。此外,数据的频繁来回传输还增加了能耗,对于追求高效能运算的现代计算环境来说是一大负担。
存内计算(In-Memory Computing)技术提供了一个颇具吸引力的解决方案。这种技术通过在存储器件(如RAM、甚至是更持久的存储介质)中直接嵌入计算单元来实现数据的处理,使得数据处理可以在数据存储的位置就近完成,而无需数据在处理器和存储设备之间的频繁搬运。在神经网络训练的上下文中,存内计算使参数更新的过程更加高效。模型训练过程中的参数,如权重和偏差,可以直接在存储单元中进行更新。这种方式减少了数据传输的需要,显著提高了参数更新的速度,从而加速了整个训练过程。此外,存内计算还有助于降低能耗,因为减少了数据传输造成的能量消耗。这种新的计算模式为处理大规模神经网络训练时的计算瓶颈提供了创新性的解决方案,有望缓解扩散模型发展中的算力“饥渴症”。
结语
扩散模型对算力的渴望与存内计算提供的解决方案相辅相成,它们一起开辟了性能提升的新途径,使得更加高效的AIGC成为可能。存内计算允许扩散模型在保证不降低生成过程质量的同时加快其迭代速度。通过在内存中即时处理数据,存内计算减少了时间消耗高昂的数据往返过程,从而提高了整体处理的速度。然而当今扩散模型的发展上饱受算力束缚,随着未来的不断探索和发展,存内计算有望在视觉AOGC领域发挥更大的作用。
如果想进一步了解存内计算,可以参与存内社区联名活动!与「扣子」&「MiniMax」官方现场交流!
