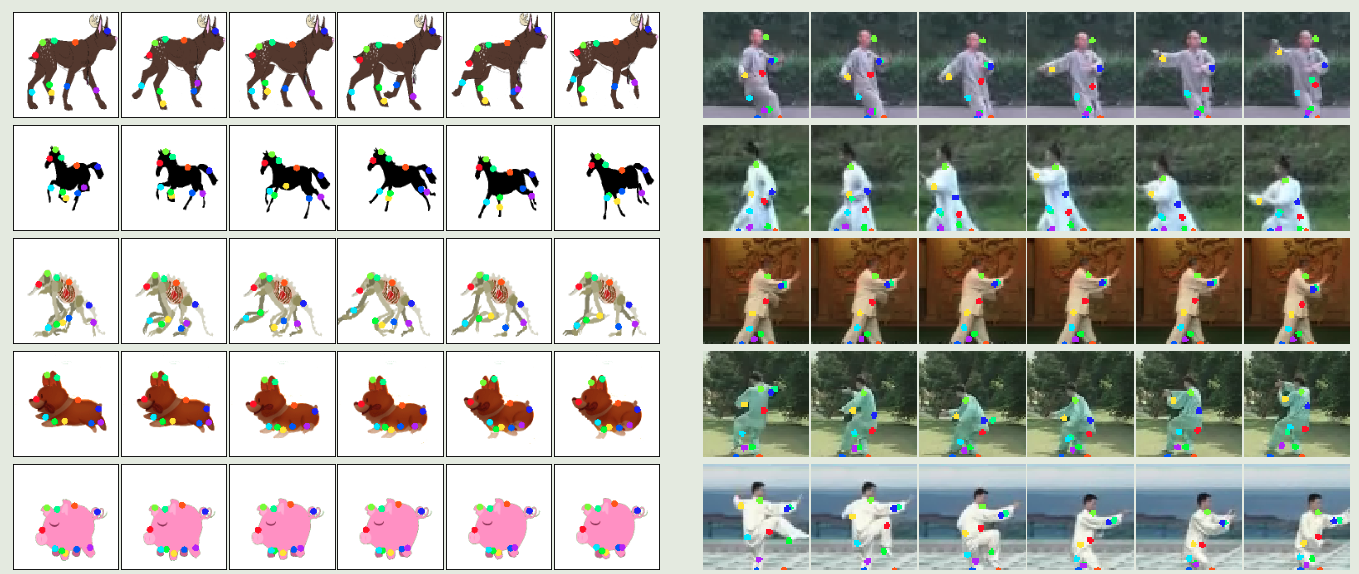
论文笔记:Image Anaimation经典论文-运动关键点模型(Monkey-Net)

Monkey-Net(MOviNg KEYpoints)
paper: https://arxiv.org/pdf/1812.08861, CVPR 2019
code: https://github.com/AliaksandrSiarohin/monkey-net/tree/master
相关工作
视频生成演变过程:
- spatio-temporal network: 如基于GAN网络的生成模型,一次生成多帧图像
- recurrent neural networks: 使用LSTM + GAN网络,生成视频,以此来增加时序信息。这类方法还可以在输入增加条件信息,如动作类别标签,以此生成所需动作的高质量视频。
- 两阶段级联结构(hierarcchical video prediction model):第一阶段生成一些列lanmark(如使用lstm);然后使用landmark生成图像帧。
Image Anaimation:*
-
该任务定义为给定一幅静态图像,和一个参考动作视频,让静态图像中物体按照参考图像中物体运动。
-
该任务的核心可以分为解偶-重构两个阶段:
- 将视频中运动信息和内容信息解偶
- 然后再根据运动信息和内容重构视频的过程
在人脸Animation中,经典3D MM模型是经常被使用的模型,但其局限性非常明显:
- 3DMM 模型仅限于人脸,domain-specific非常明显。
- 3DMM模型在一些具有挑战的情况下性能急剧下降,如人脸遮挡。
本文贡献
结合下图,贡献如下:
-
设计了一个无监督关键点检测模块,用于提取物体关键点。
- KeyPoint Detector: 输入为参考图像和驱动视频帧,输出为稀疏关键点。
- 由于训练过程是无监督的,因此不需要标注关键点信息。
- 实际上,两帧之间稀疏关键点差异可以看做一种紧致的运动表征。
-
设计了密集运动估计网络:用于从稀疏关键点中重建运动热图(motion heatmaps),热图用于更好地表征运动信息。
- Dense Motion prediction network:输入为1中的稀疏关键点,输出为运动热图。以此来估计参考图像和驱动图像之间的光流。
- 这样做有两个动机:
- 使得1中关键点检测网络不仅关注物体的结构信息,也关注运动信息。使得自监督的关键点检测网络检测到的关键点必需落在运动大的位置。
- 传统encoder-decoder密集预测模型未考虑到输出输出之间较大的像素不对齐问题。增加光流信息希望促进输入输出之间差异比较大时的对齐。
-
设计了一个运动迁移网络:使用运动热图,和从从参考图像中提取的内容表征生成视频帧图像。
Motion Transfer network: 输入为参考图像和运动热图,输出为重构后的视频帧。经典encoder-decoder结构。
训练过程核心思路:
- 生成器G需要根据参考图像、参考图像关键点、驱动图像关键点三个部分重建出驱动图像( x ′ x' x′);通过这个过程,参考图像( x x x)和驱动图像之间( x ′ x' x′)的关系被隐式建模。
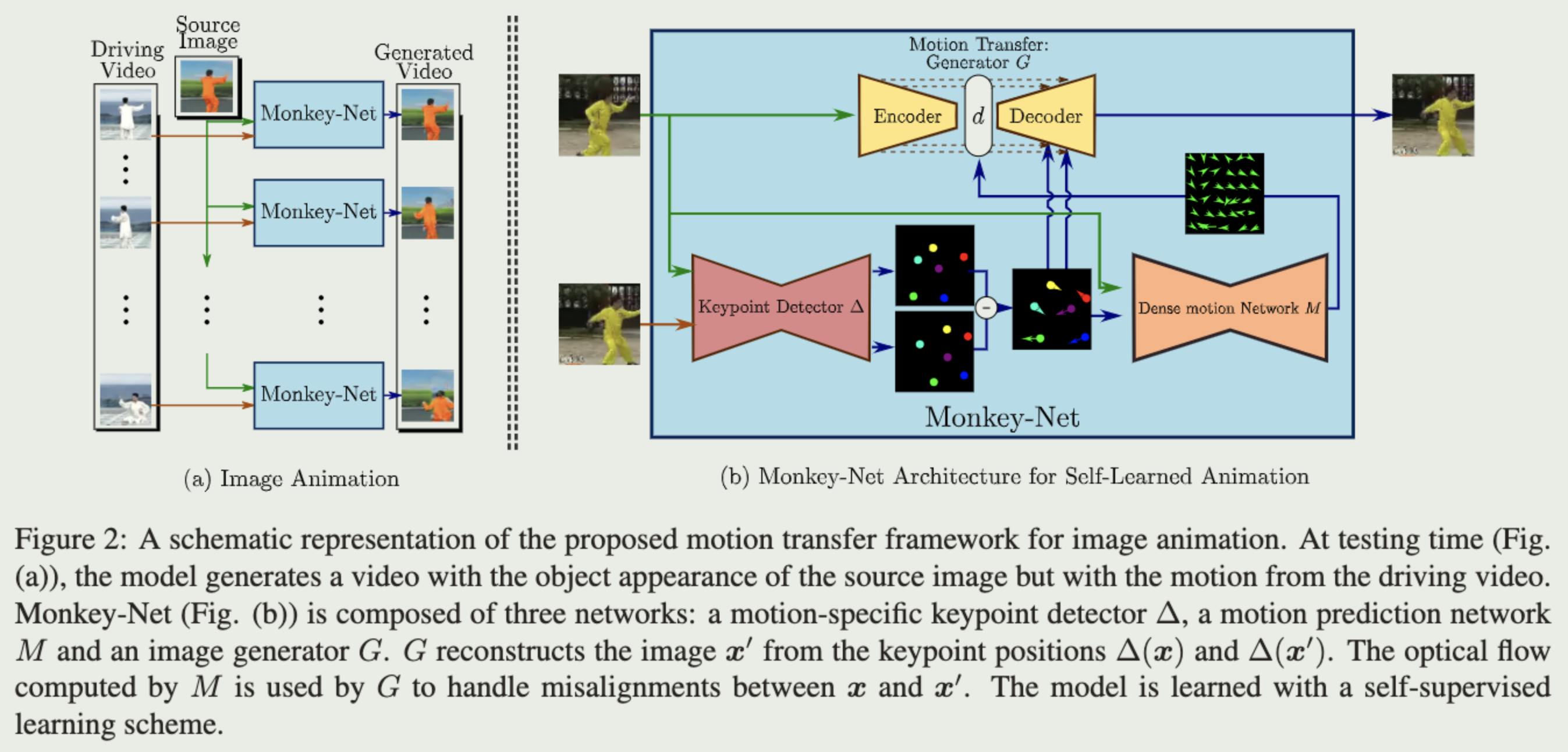
实现细节
无监督关键点检测网络:
- encoder-decoder结构,输出为K个HxW的heatmap,每个heatmap对应一个关键点,使用softmax将输出归一化至[0, 1]。
- 使用heatmap的动机:更好地适配卷积网络。
- 为了学习关键点位置信息,将每个heatmap拟合至一个高斯分布,使得模型间接学习关键点。
- 模型不仅拟合了关键点的位置信息,还拟合了关键点的协方差矩阵。目的是同时学习关键点的位置和方向信息。以人的腿为例,关键点不仅包括腿部关键点的位置信息,还可以学习到腿的运动信息。
运动迁移网络:
- 主干网络还是U-Net like 的encoder-decoder结构,增加了变形模块(Deformation module)融入光流信息。
- 核心内容:使用一个warp function将光流信息和encoder中特征进行融合。本质是一个可微的非线性变换,具体操作看代码吧:
def deform_input(self, inp, deformations_absolute):# 获取 deformations_absolute 的形状bs, d, h_old, w_old, _ = deformations_absolute.shape# 获取 inp 的形状_, _, _, h, w = inp.shape# 调整 deformations_absolute 的维度顺序,从 (bs, d, h_old, w_old, _) 变为 (bs, _, d, h_old, w_old)deformations_absolute = deformations_absolute.permute(0, 4, 1, 2, 3)# 使用插值方法调整 deformations_absolute 的大小,使其与 inp 的大小匹配deformation = F.interpolate(deformations_absolute, size=(d, h, w), mode=self.interpolation_mode)# 再次调整 deformation 的维度顺序,从 (bs, _, d, h, w) 变为 (bs, d, h, w, _)deformation = deformation.permute(0, 2, 3, 4, 1)# 使用 grid_sample 函数对 inp 进行变形deformed_inp = F.grid_sample(inp, deformation)# 返回变形后的输入return deformed_inp
从稀疏关键点到密集光流
- 密集运动估计网络M输入包括两个:1. 参考图像关键点和驱动图像关键点map的差值。2. 参考图像本身。
- 假设在每个物体上的关键点是局部刚性的,那么光流预测问题就变为:根据关键点预测掩模,这些掩模根据关键点信息将物体刚性的分成不同部分。
- 预测的密集光流可根据预测的刚性掩模和光流信息点乘得到。
- 注意:最终预测的光流信息,有一个粗粒度结果和一个残差结果相加得到。

网络训练
- 整个网络训练是一个端到端的过程
- 损失函数包括:对抗损失、特征匹配损失
结果
定量指标就不放了。这里自监督的可学习关键点很有意思,每个物体的关键点都不一样,即使是类内的关键点也会有差异。