DETR论文重点
DETR就是 DEtection TRansformer 的缩写。
论文原名:End-to-End Object Detection with Transoformers。
重点有两个:端到端、Transformer结构
论文概述
注意:斜体的文字为论文原文,其他部分内容则是为增进理解而做的解释。
我们提出了一种将目标检测视为直接集合预测问题的新方法。
如何理解集合预测?
假设一张图像中有 N 个目标,那这 N 个 目标就是一个集合,DETR这个算法就是可以一次性从图像中预测出这个包含 N 个 目标的集合。
我们的方法简化了检测流程,有效地消除了许多手工设计的组件,如非极大值抑制过程或锚生成,这些组件明确地编码了我们关于任务的先验知识。
之前的算法一般都要在最后得到的一堆预测框中做NMS去删除冗余的预测框,或者是手工设计锚,这就需要我们使用先验知识,比如说对于一些像素,我们需要为它去设计产生几个锚,比如说产生三个锚,那么这三个锚的尺寸和高宽比是什么样的,这些都需要使用先验知识去进行设计,而 DETR 则不需要这些,它是一个端到端的网络。

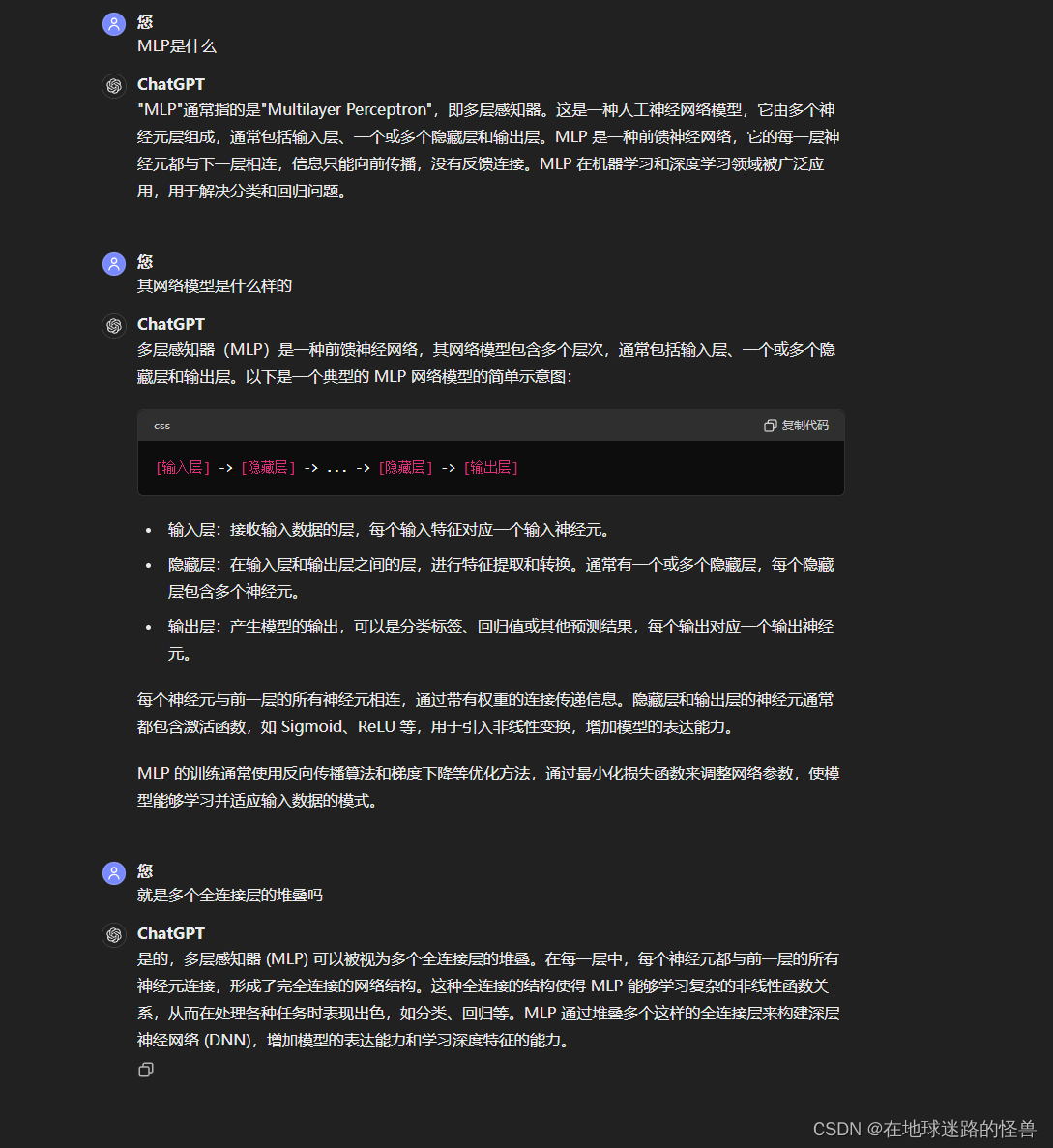
DETR训练和测试的框架示意图:
从上图可以看到,在训练阶段中,将一张图像扔入 DETR 模型,然后会得到一百(这个一百数值是个超参数,因为大部分图像中的 object 的数量都不会超过一百个,所以这里选择一百)个预测框,其中包括了这一百个预测框的类别信息和坐标信息。
然后从标注信息中我们可以知道这张图像中总共有两个 object ,然后就使用匈牙利算法从预测出的一百个候选框当中筛选中两个预测框,这两个预测框和这两个标注框是一一对应的关系,最后再使用筛选出的这两个预测框和这两个标注框一起去计算损失,然后再反向传播(图中虚线位置)去优化模型。
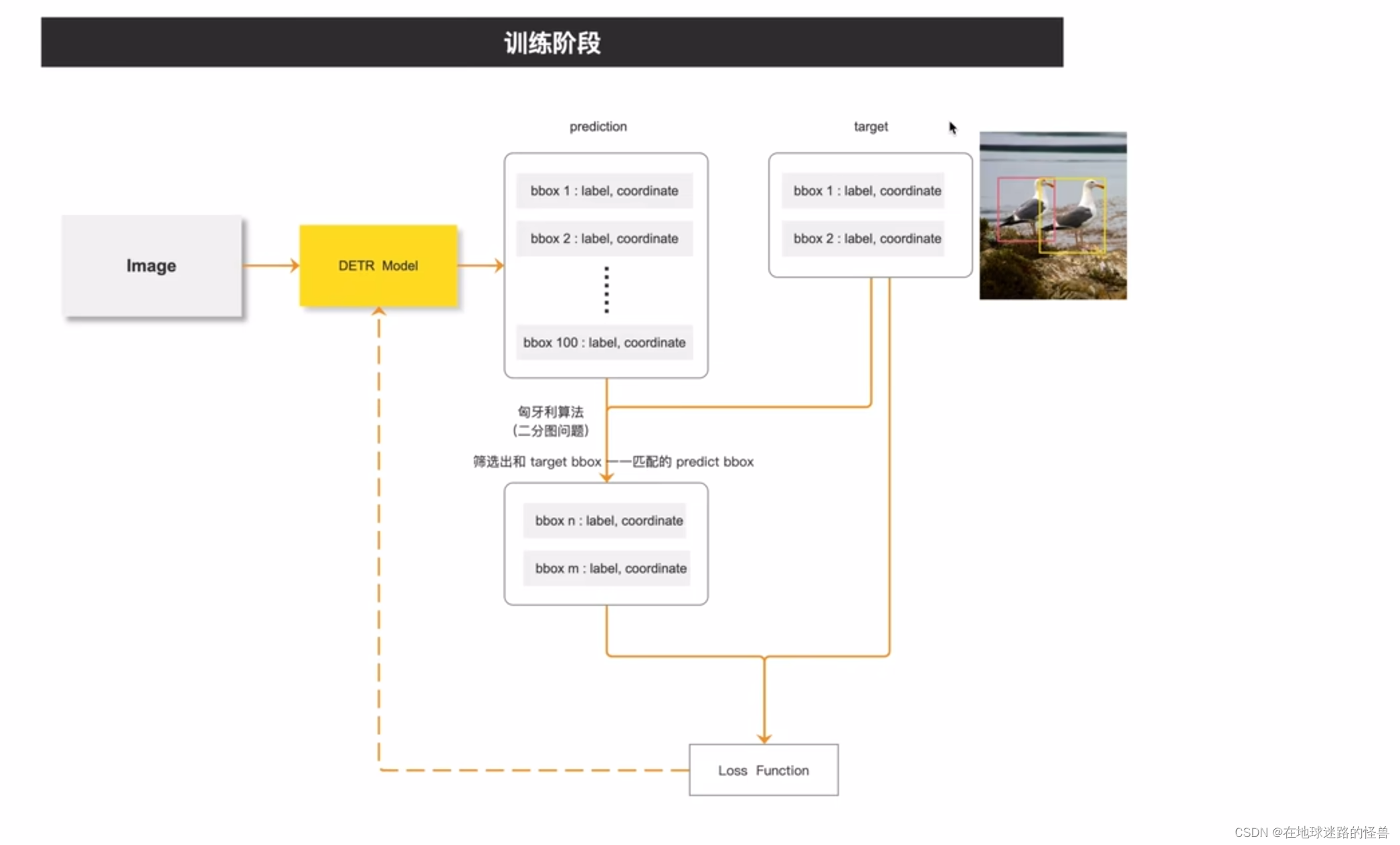
测试阶段:
上图是测试阶段,在测试阶段,同样通过网络预测出一百个预测框之后,将这一百个预测框的类别的置信度和类别置信度阈值进行对比,大于阈值的预测框我们进行保留,小于阈值的就排除掉,所以通过训练阶段框架和测试阶段框架我们可以知道,在 DETR 里我们是不用手动设计anchor的。
同样,也没有用到 NMS 。
新框架的主要成分称为DEtect TRansformer或DETR,是一个基于集合的全局损失,通过二分匹配强制进行唯一预测,以及一个转换器编码器-解码器架构。给定一个固定的小的学习对象查询集合,DETR推理对象之间的关系和全局图像上下文直接并行输出最终的预测集合。
然后摘要给出了算法中的两个重点:一个是损失函数,另一个是 Transformer 框架。
对于损失函数,其是一个基于集合的全局损失,通过二分类匹配得到独一无二的预测结果,这个也就是刚刚上文在训练阶段说的通过匈牙利算法去解决这个二分图匹配问题,然后就得到了一个和标注框一一对应的匹配的独一无二的预测结果。
然后是对于 Transformer 的 编解码框架,在 Decoder 模块中,其设定了一个 learned object queries,通过这个 learned object queries ,DETR就可以对 objects 和图像的全局信息的关系进行推理,并行的直接的输出最后的预测结果。
其网络的结构图如下:
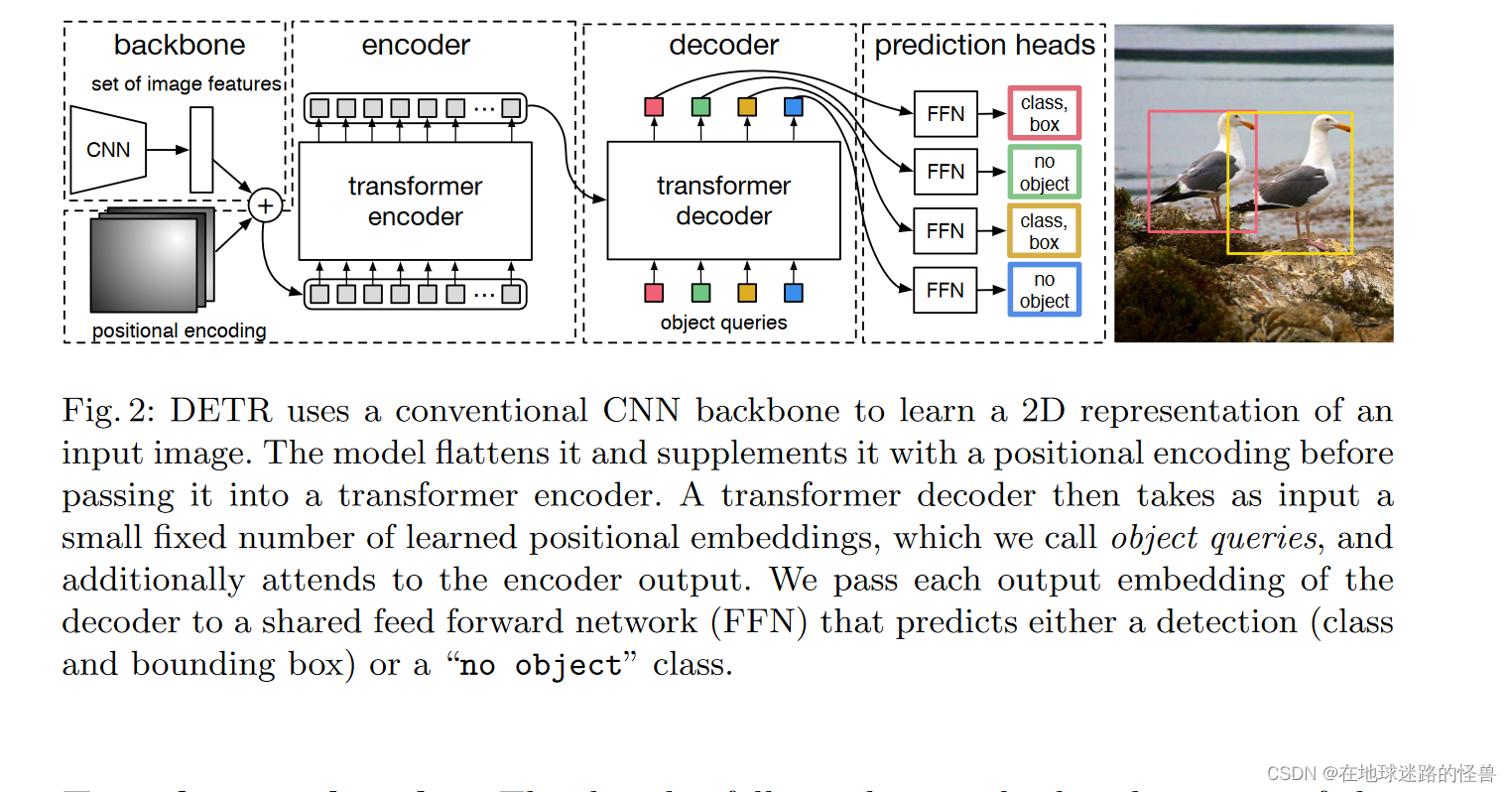
DETR使用传统的CNN主干来学习输入图像的2D表示。该模型将其拉平,并在传递到 Transformer 编码器之前用位置编码进行补充。然后,一个 Transformer 解码器将少量固定数量的学习位置嵌入作为输入,我们称之为对象查询,并附加到编码器输出。我们将解码器的每个输出嵌入传递给一个共享前馈网络( FFN ),该网络预测一个检测(类和边界框)或一个"无对象"类。
在上图的 decoder 模块中的 object queries 是一个可以学习的参数,同时我们也用它来指定输出的预测框的个数,是通过它的尺寸来指定的,在 transformer 中输出 token 个数是等于输入 token 个数的,如果我们把 object queries 的个数设置为一百,那么在输出就可以得到一百个预测框。
原图像通过 CNN 和 Transformer 中的 encoder 模块之后就可以得到一个图像的全局信息,transformer 的 decoder 模块就用于让 object 的预测框和图像的全局信息做自注意力操作,然后得到预测框的集合的输出,还有一点就是 decoder 在生成输出的时候那些 token 的计算是并行的,也就是这一百个预测框的结果是并行计算得到的。
新模型在概念上简单,不需要专门的库,与许多其他现代检测器不同。DETR在具有挑战性的COCO目标检测数据集上表现出与公认的、高度优化的更快速的区域卷积神经网络基线相当的准确性和运行时性能。此外,DETR可以很容易地推广,以统一的方式产生全景分割。我们表明它明显优于竞争性基线。
模型结构
论文中提供了下面两幅图,第一幅是模型的整体结构图,包含一个 CNN 的 backbone 结构,一个 Transformer (编解码器以及位置编码)结构和检测头结构(两个检测头,一个用于预测 bounding box 的类别,另一个用于预测 bounding box 的坐标)。
第二张图则是论文附录部分的内容,是 DETR 模型所使用的 Transformer 结构中的编解码器架构的细节图,其与原本的 Transformer 有些许不同,一会儿我们会仔细学习。
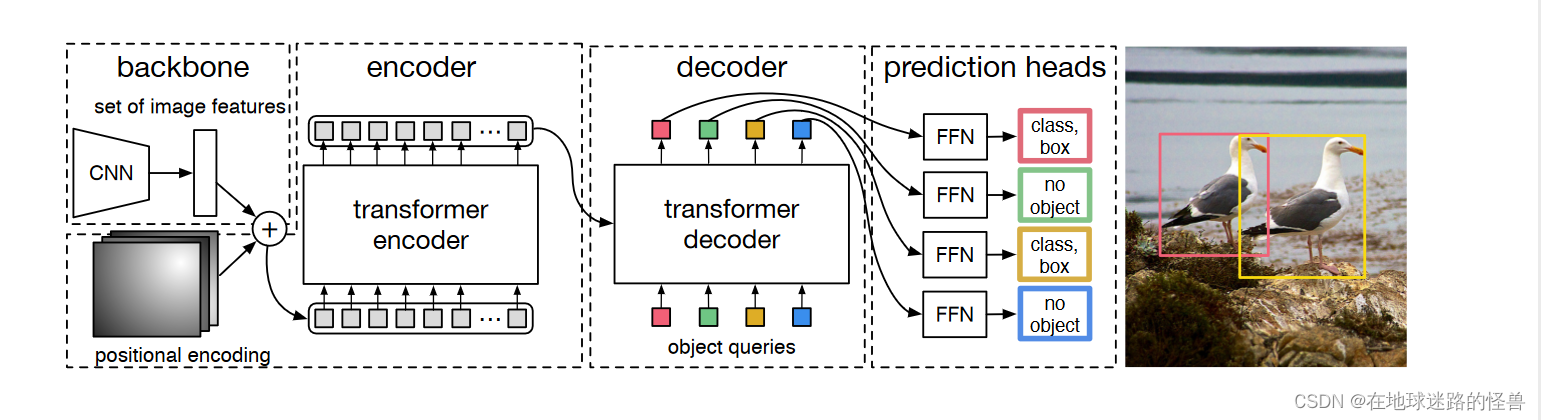
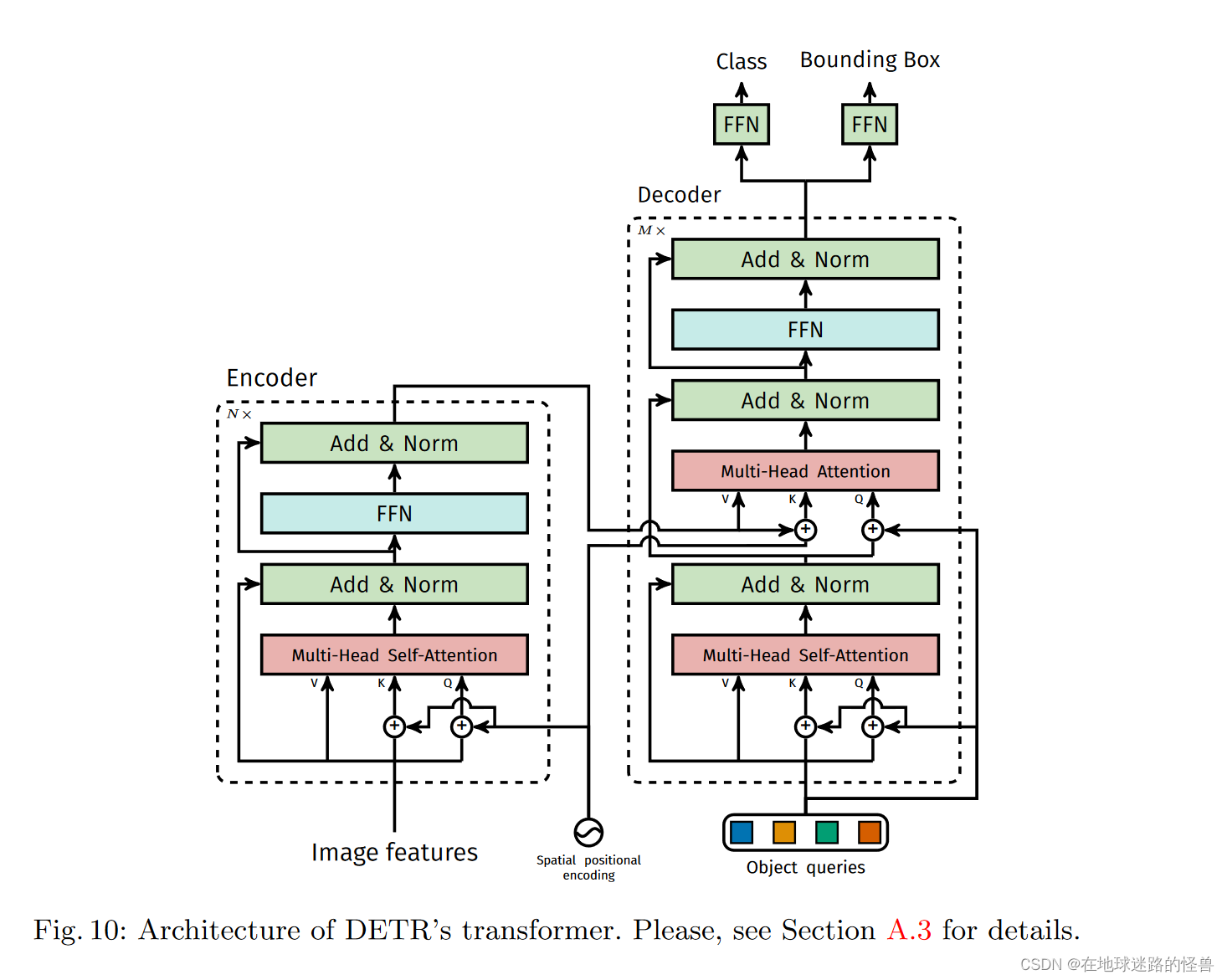
为了便于学习,将这两幅图给合整合在一起变成下面这副模型细节结构图:
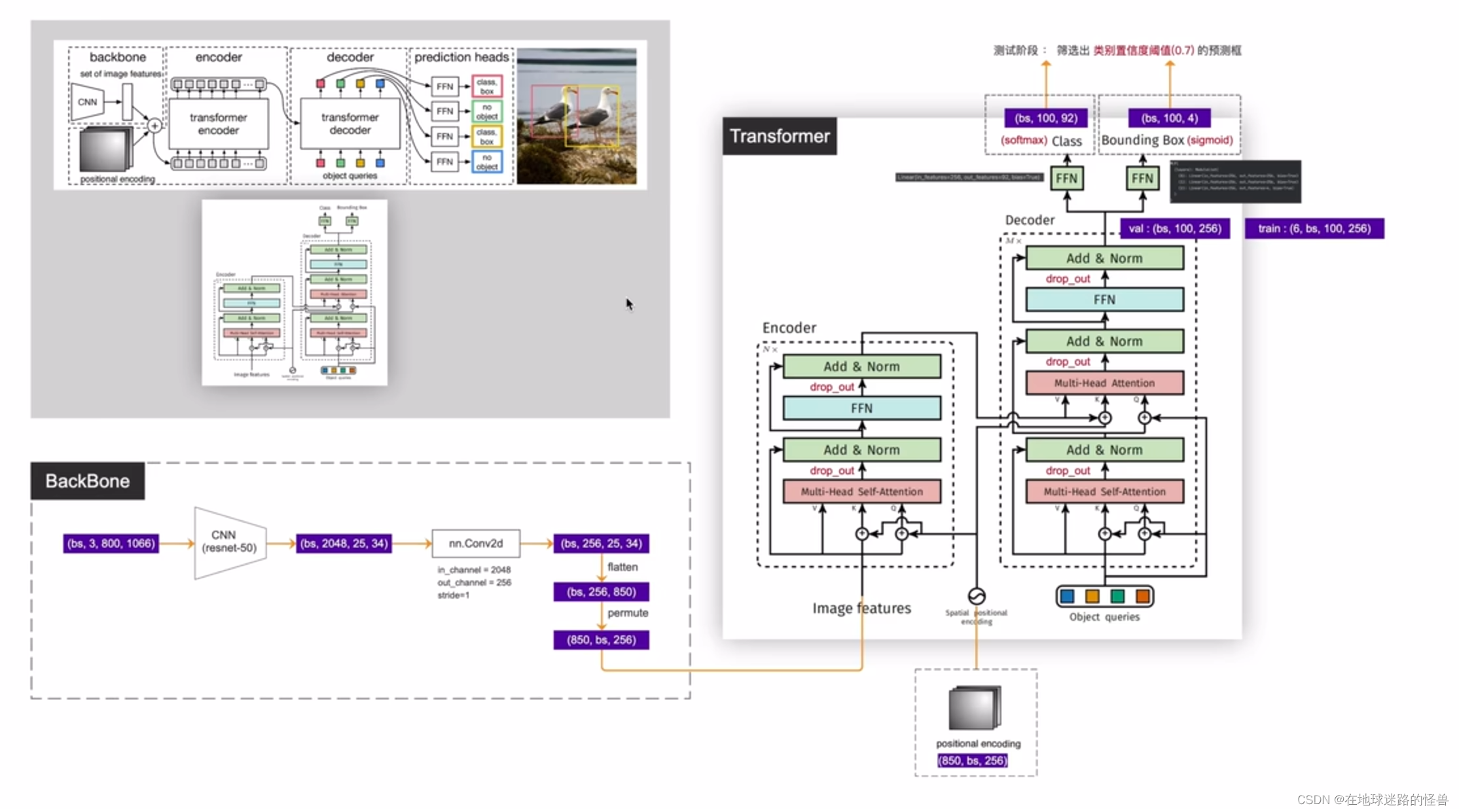
上图的左侧可以看到,拿到一张 image 之后经过 CNN 网络学习之后得到的特征为(850, batchsize, 256),其中 850 就是稍后使用 transformer 的 token 的个数,而 256 就是每一个 token 的特征向量长度,然后输出结果到上图右侧的 transformer 结构中。
在输入时,图片的特征向量还要结合位置编码之后,才能进入 transformer 中的 Encoder 编码器中。这里和标准 transformer 有些许不同:
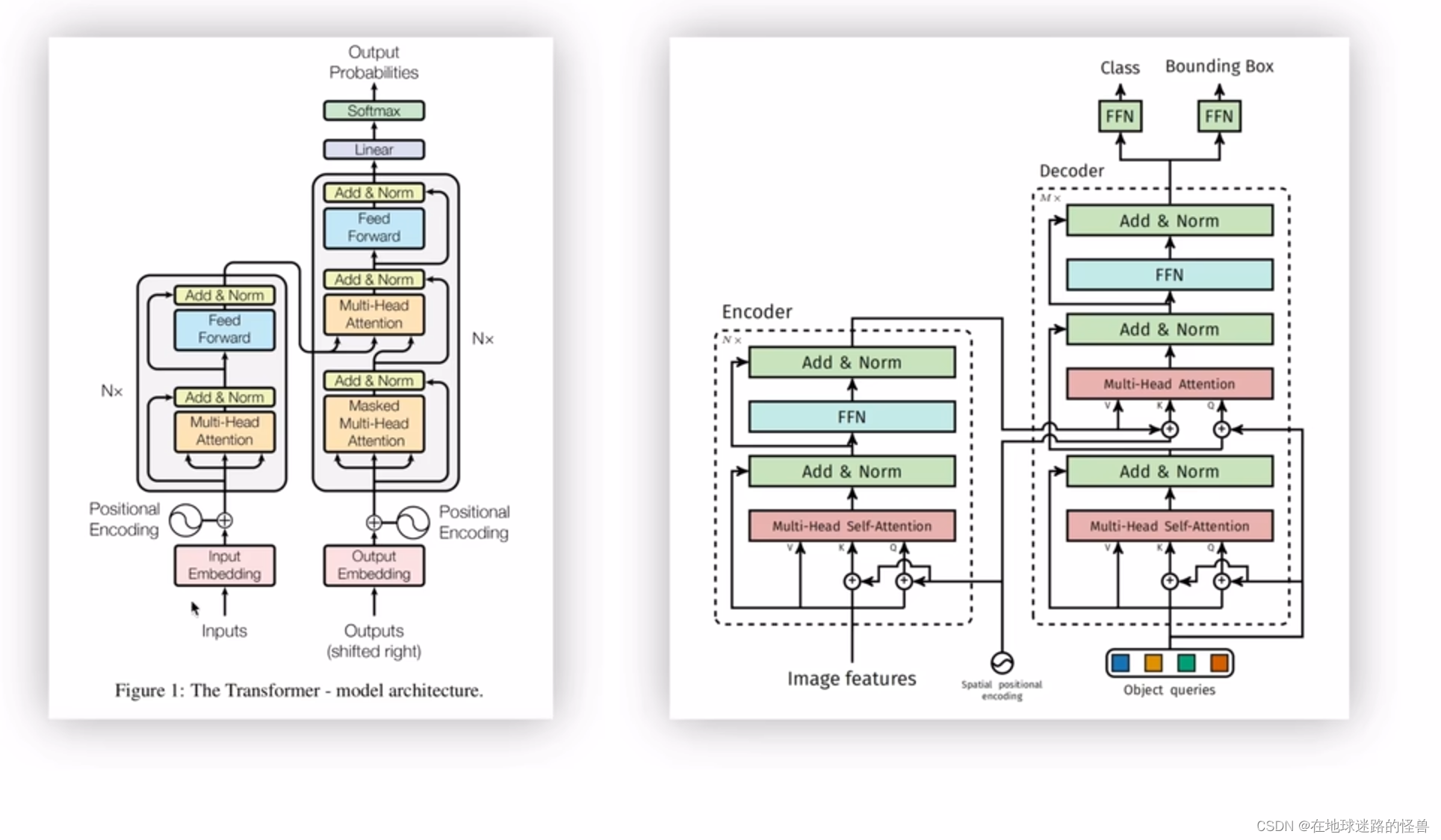
在标准的 transformer 中(上图左侧),位置编码是直接加在 inputs 上的并且只在 inputs 上操作了一次,而 DETR 的 transformer 里位置编码是在每个堆叠的 Encoder、Decoder 中都要使用的,比如假设 Encoder 有六层,也就是上图右侧的编码器框图中的 N 为6,说明 Encoder 模块需要堆叠六次,那么对于每个 Encoder 模块中的 Multi-Head Self-Attention 层位置编码则都需要加在其对应的输入上然后生成 Key 和 Query 值。因为输入是一样的,位置编码也是一样的,因此这里得到的 Key 和 Query 也是一样的,而 Value 就等于 Image Features,也就是输入。然后在这六个 Encoder 当中,每个 Encoder 都需要这样子操作一次,而 Decoder 模块也同样有六块,也需要堆叠六次,然后在每个 Decoder 模块中位置编码都需要和 Encoder 的输出进行相加,然后得到 Decoder 模块中的 Key,这个操作同样要执行六次。
这就是 DETR 的 Tramsformer 所不一样的地方。
然后是 Decoder,可以看到其接受三个输入,第一个是 queries,初始值是 0,第二个是 output positional encoding,也就是 object queries,而第三个则是encoder memory,也就是我们刚刚说的 encoder 的输出加上位置编码后形成了 encoder memory 成为了 decoder 模块的第三个输入(图像的全局特征信息)。
经过多个多头自注意力机制层、编码器解码器层之后就生成了预测类别标签和 bounding box 的坐标,确切的说就是通过最后两个检测头得到的。
整个 Decoder 部分可以分成上下两部分来看,上图右侧的下面这一部分(也就是在得到 encoder memory 之前的部分),我们可以理解成 Multi-Head Self-Attention 在学习 anchor 的特征,然后上面这一部分我们可以理解成其在拿到图像的全局特征信息以及 anchor 特征的基础上进行预测或者是学习图像中的 bounding box 的坐标以及物体的类别。
注意,论文原文中有一句:Decoder 模块中的第一个 self-attention 层是可以被省略掉的(也就是刚刚说的在拿到 encoder memory 之前的部分)。
结合关键代码片段理解
encoder 部分
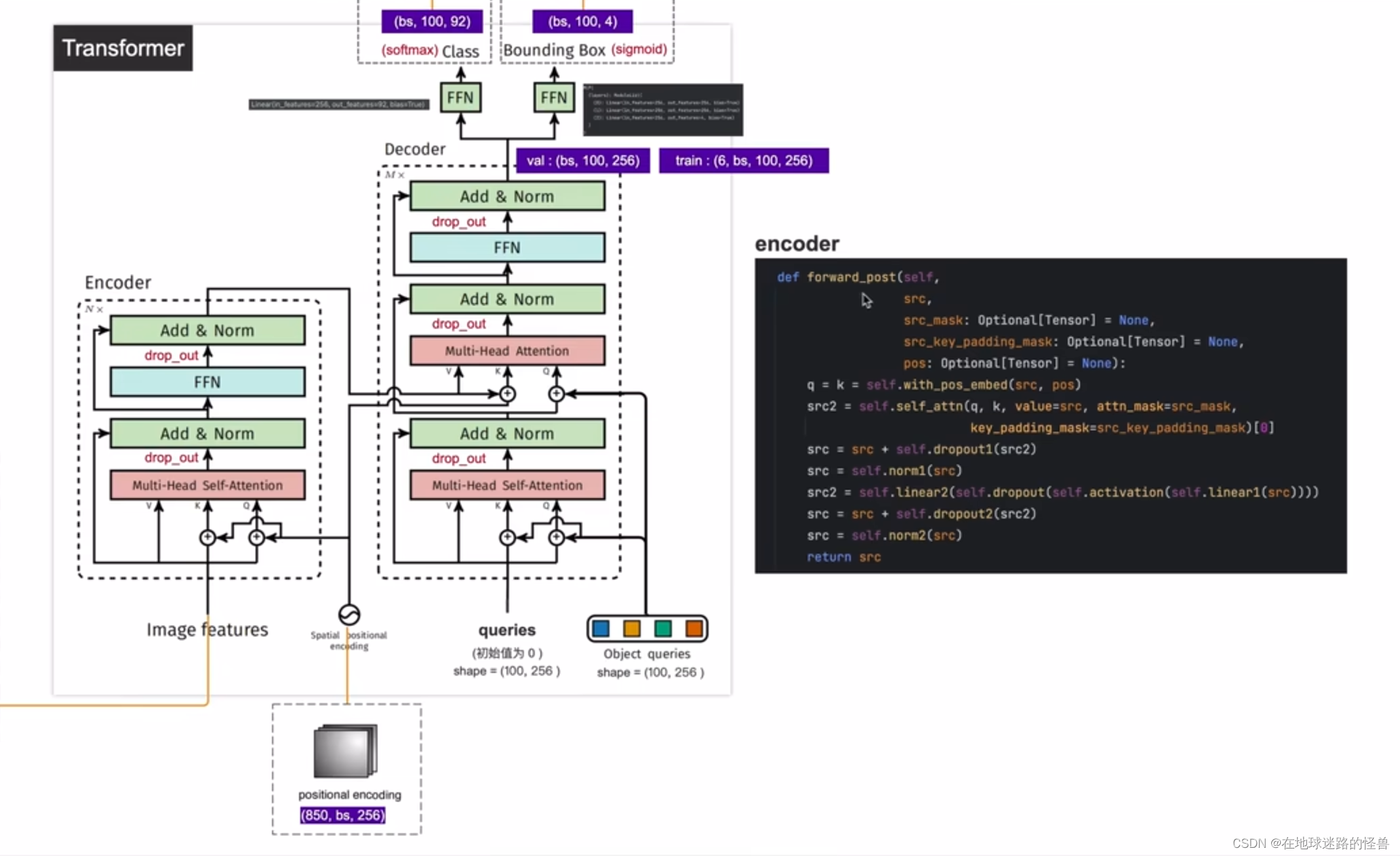
函数包括两个参数,一个是 src,也就是从 CNN 的 backbone 中得到的输出 image features,另一个是 pos,也就是 positional encoding位置编码,而上图中间还有两个参数我们用不到,其是用来做分割任务的,和我们没关系,不管即可。
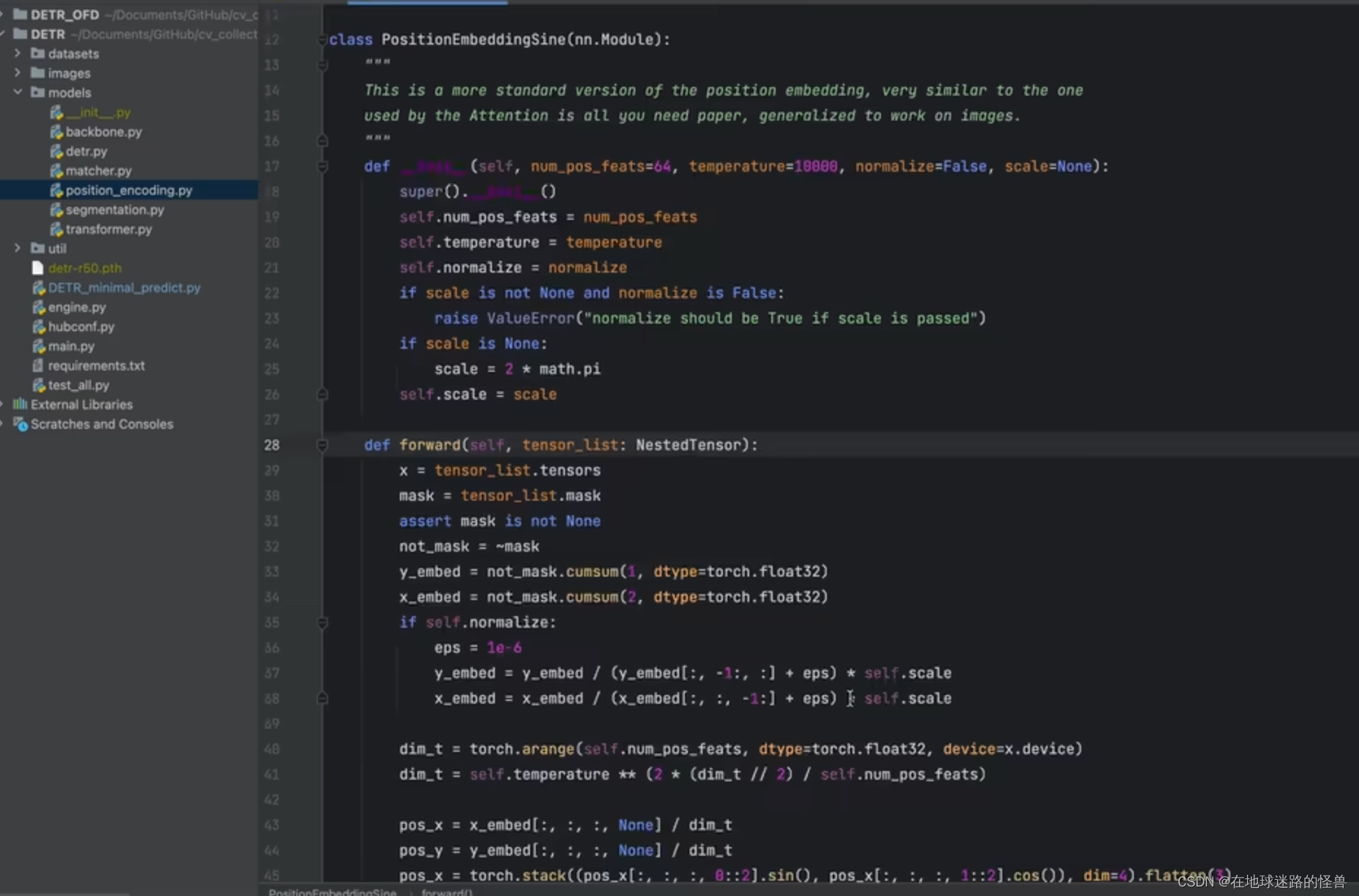
对于怎么生成位置编码,作者给了两种方法,第一种是使用 sin 和 cos 函数来实现的:
第二个方式是可学习的位置编码:
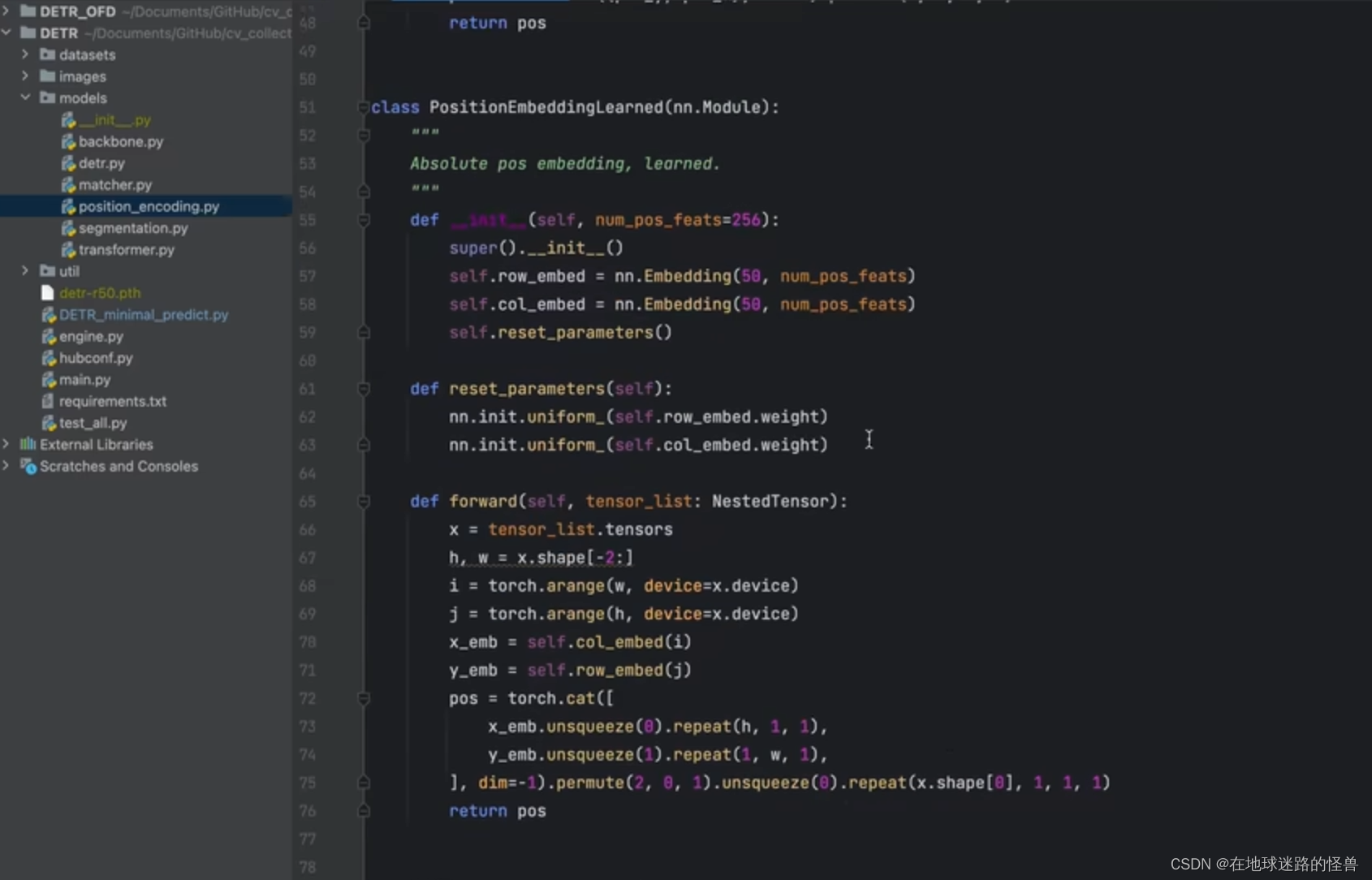
可以随便选一个,但作者源码种所使用的是第一种基于三角函数的方式。
有了这两个参数之后,在函数内部使用了 with_pos_embed,也就是像我们之前在理论时讲的,将 image features 和 位置编码进行相加生成 Queries 和 Key 值,而 Value 值就是直接等于 Image Features 。
第二步按照流程就是调用 self_attn 函数,也就是进行 Multi-Head Self-Attention 操作,向该函数中输入 q、k、v 的值即可(后面两个多余的参数不用管,我们用不到),该函数执行完拿到一个 src2。
然后 src2 进行 dropout 操作,再加上原来的 src 更新成新的 src(就是做一个类似于残差网络的跨层连接),然后进行一个归一化操作,然后再进行一个 FFN 的操作,也就是图中的下面这行代码:
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
即 src 先进行一个全连接层 linear1,然后再进行一个 Relu 激活层 activation,然后 dropout 最后再进行一个全连接层 linear2,得到一个值 src2,也就是 FFN 层的输出。
然后对该输出进行 dropout的同时还要加上原来的 src(跨层连接),最后再进行一个归一化 norm2 层就可以拿到 encoder 模块的输出了,这就是 encoder 模块的整体结构。
decoder 部分
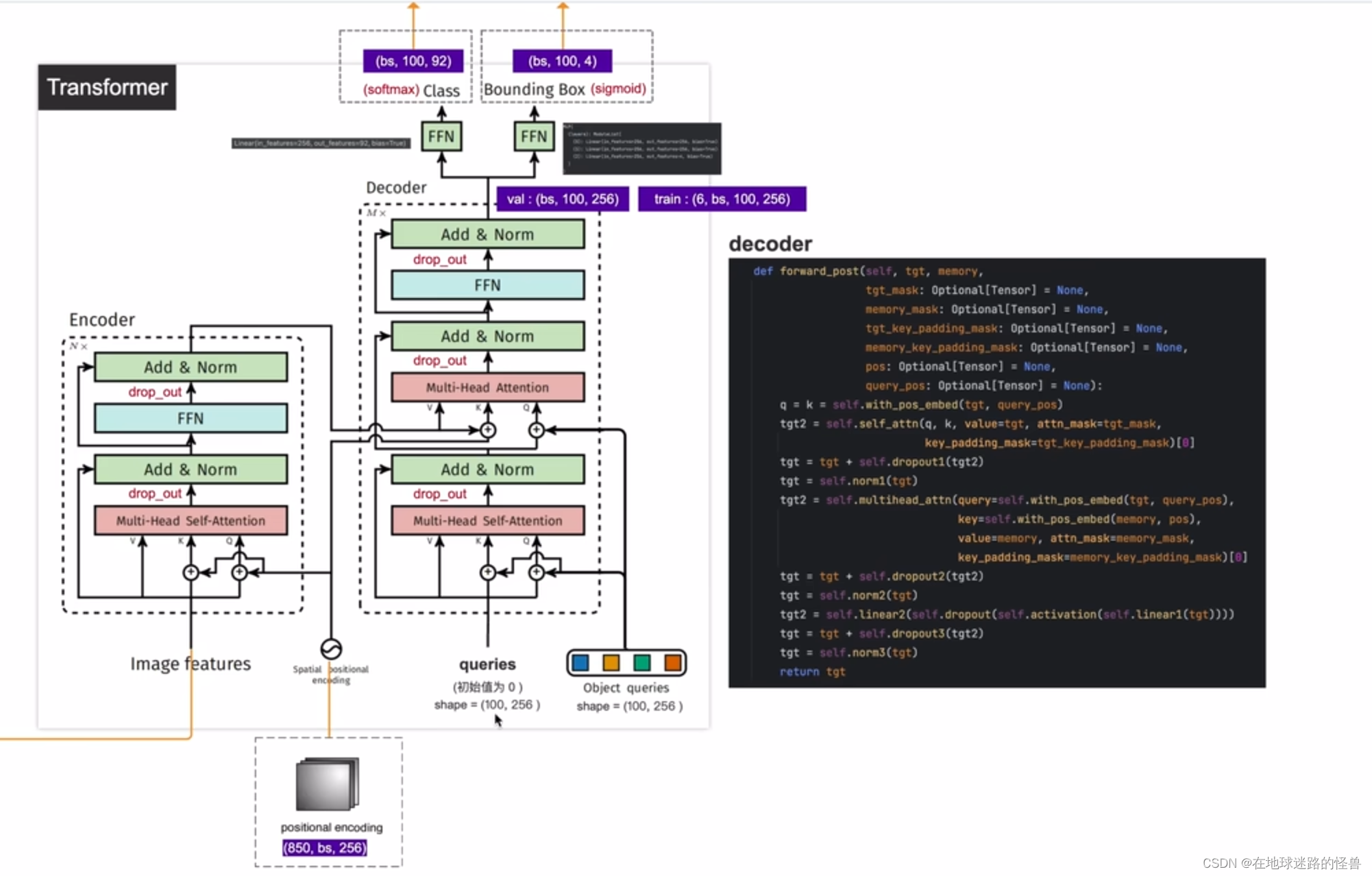
从上图可以看出,其反向传播函数的参数有第一个 tgt,也就是上图左侧的 queries,第二个参数是 memory,这个 memory 就是 encoder 的输出,中间带有 mask 字样的参数我们都不需要管,是用来做分割任务的,然后是第三个参数 pos,即位置编码,第四个参数是 query_pos,即 object queries 对象查询参数。对于函数的执行流程的化也和之前将的 encoder 部分比较相似,是比较好理解的因此就不再赘述。
FFN 部分
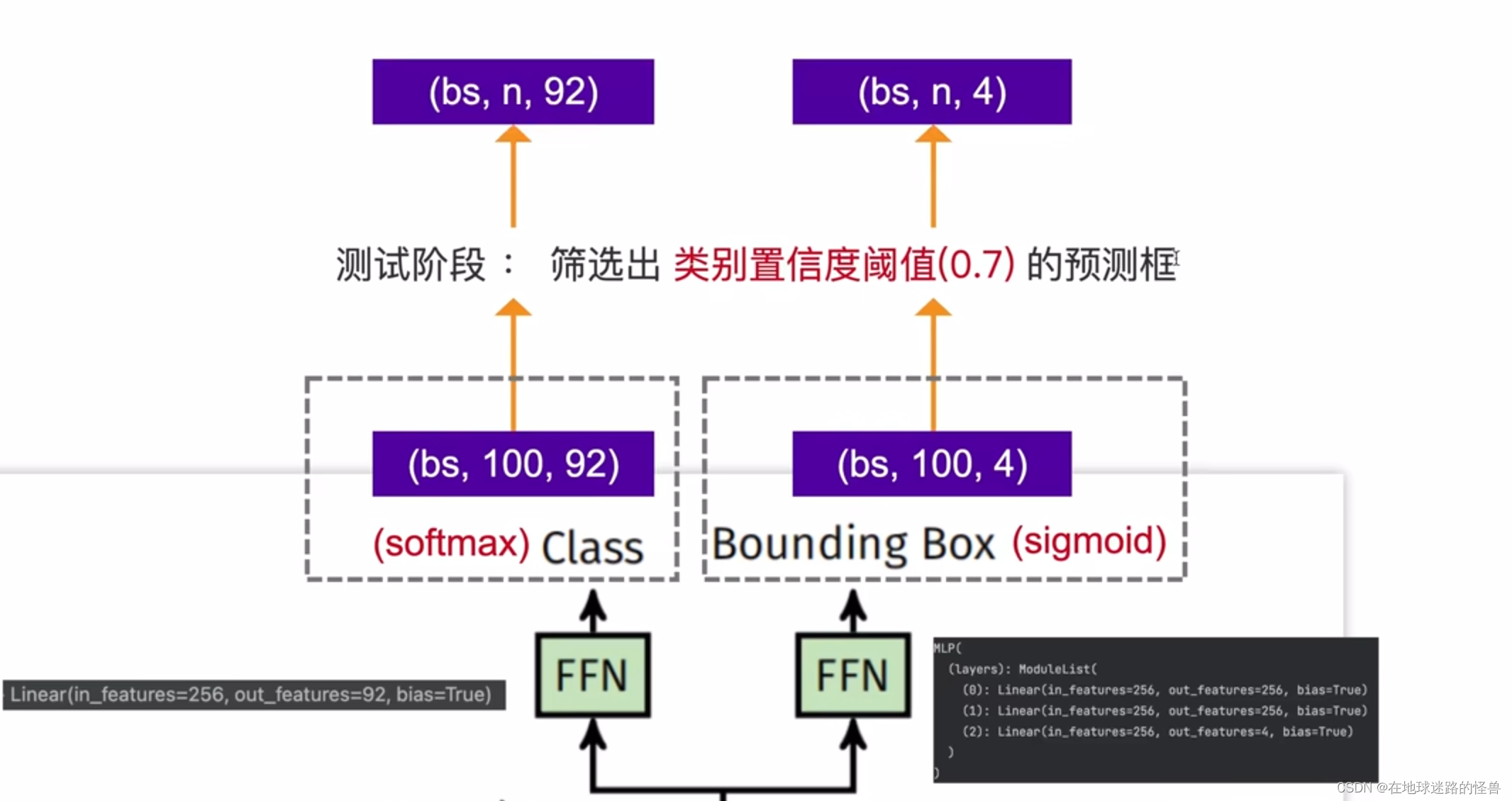
比较简单就没什么好说的了,简单介绍一下 MLP: