YOLOv5改进(五)-- 轻量化模型MobileNetv3
文章目录
- 1、MobileNetV3论文
- 2、代码实现
- 2.1、MobileNetV3-small
- 2.2、MobileNetV3-large
- 3、运行效果
- 4、目标检测系列文章
1、MobileNetV3论文
Searching for MobileNetV3论文
MobileNetV3代码
MobileNetV3 是 Google 提出的一种轻量级神经网络结构,旨在在移动设备上实现高效的图像识别和分类任务。与之前的 MobileNet 系列相比,MobileNetV3 在模型结构和性能上都有所改进。
MobileNetV3 的结构主要包括以下几个关键组件:
-
基础模块(Base Module):MobileNetV3 使用了一种称为**“倒残差”(Inverted Residuals)**的基础模块结构。该结构采用了深度可分离卷积和线性瓶颈,它由一个1x1卷积层和一个3x3深度可分离卷积层组成。这个操作单元通过使用非线性激活函数,如ReLU6,并且在残差连接中使用线性投影,以减少参数数量和计算复杂度来提高网络的特征表示能力,并且保持了模型的有效性。
-
Squeeze-and-Excitation 模块:MobileNetV3 引入了 Squeeze-and-Excitation 模块,使用全局平均池化层来降低特征图的维度,并使用一个1x1卷积层将特征图的通道数压缩成最终的类别数量。最后,使用softmax函数对输出进行归一化,得到每个类别的概率分布。通过学习通道之间的相互关系,动态地调整通道权重,以增强模型的表征能力。这有助于提高模型对关键特征的感知能力,从而提高分类性能。
-
Hard-Swish 激活函数:MobileNetV3 使用了一种称为 Hard-Swish 的激活函数。与传统的 ReLU 激活函数相比,Hard-Swish 具有更快的计算速度和更好的性能。
-
网络架构优化:MobileNetV3 在网络结构上进行了优化,包括通过网络宽度和分辨率的动态调整,以适应不同的计算资源和任务需求。
总体而言,MobileNetV3 通过这些创新设计和优化,实现了更高的性能和更低的计算成本,使其成为移动设备上图像识别任务的理想选择之一。
MobileNetV3 的主要处理流程如下:
-
输入处理:输入图像首先经过预处理步骤,例如归一化和大小调整,以使其适应网络的输入要求。
-
特征提取:经过输入处理后,图像通过一系列基础模块(Base Module)进行特征提取。每个基础模块通常包含深度可分离卷积、激活函数(如 Hard-Swish)和通道注意力(如 Squeeze-and-Excitation)模块。
-
特征增强:在特征提取的过程中,通过 Squeeze-and-Excitation 模块对提取的特征图进行增强,以加强对重要特征的感知能力。
-
全局平均池化:在特征提取的最后阶段,通过全局平均池化操作将特征图的空间维度降低到一个固定大小。
-
分类器:全局平均池化后的特征图输入到分类器中,进行分类或其他任务的预测。分类器通常由一个或多个全连接层组成,最后输出预测结果。
2、代码实现
2.1、MobileNetV3-small
(1) 在models/common.py的引入MobileNetV3模块
# 引入MobileNetV3模块
class StemBlock(nn.Module):def __init__(self, c1, c2, k = 3, s = 2, p = None, g = 1, act = True):super(StemBlock, self).__init__()self.stem_1 = Conv(c1, c2, k, s, p, g, act)self.stem_2a = Conv(c2, c2 // 2, 1, 1, 0)self.stem_2b = Conv(c2 // 2, c2, 3, 2, 1)self.stem_2p = nn.MaxPool2d(kernel_size = 2, stride = 2, ceil_mode = True)self.stem_3 = Conv(c2 * 2, c2, 1, 1, 0)def forward(self, x):stem_1_out = self.stem_1(x)stem_2a_out = self.stem_2a(stem_1_out)stem_2b_out = self.stem_2b(stem_2a_out)stem_2p_out = self.stem_2p(stem_1_out)out = self.stem_3(torch.cat((stem_2b_out, stem_2p_out), 1))return outclass h_sigmoid(nn.Module):def __init__(self, inplace = True):super(h_sigmoid, self).__init__()self.relu = nn.ReLU6(inplace = inplace)def forward(self, x):return self.relu(x + 3) / 6class h_swish(nn.Module):def __init__(self, inplace = True):super(h_swish, self).__init__()self.sigmoid = h_sigmoid(inplace = inplace)def forward(self, x):y = self.sigmoid(x)return x * yclass SELayer(nn.Module):def __init__(self, channel, reduction = 4):super(SELayer, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(channel, channel // reduction),nn.ReLU(inplace = True),nn.Linear(channel // reduction, channel),h_sigmoid())def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x)y = y.view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * yclass Conv_bn_hswish(nn.Module):"""This equals todef conv_3x3_bn(inp, oup, stride):return nn.Sequential(nn.Conv2d(inp, oup, 3, stride, 1, bias=False),nn.BatchNorm2d(oup),h_swish())"""def __init__(self, c1, c2, stride):super(Conv_bn_hswish, self).__init__()self.conv = nn.Conv2d(c1, c2, 3, stride, 1, bias = False)self.bn = nn.BatchNorm2d(c2)self.act = h_swish()def forward(self, x):return self.act(self.bn(self.conv(x)))def fuseforward(self, x):return self.act(self.conv(x))class MobileNetV3(nn.Module):def __init__(self, inp, oup, hidden_dim, kernel_size, stride, use_se, use_hs):super(MobileNetV3, self).__init__()assert stride in [1, 2]self.identity = stride == 1 and inp == oup# 输入通道图 = 扩张通道数 则不进行通道扩张if inp == hidden_dim:self.conv = nn.Sequential(# dwnn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups = hidden_dim,bias = False),nn.BatchNorm2d(hidden_dim),h_swish() if use_hs else nn.ReLU(inplace = True),# Squeeze-and-ExciteSELayer(hidden_dim) if use_se else nn.Sequential(),# Eca_layer(hidden_dim) if use_se else nn.Sequential(),#1.13.2022# pw-linearnn.Conv2d(hidden_dim, oup, 1, 1, 0, bias = False),nn.BatchNorm2d(oup),)else:# 否则先进行扩张self.conv = nn.Sequential(# pwnn.Conv2d(inp, hidden_dim, 1, 1, 0, bias = False),nn.BatchNorm2d(hidden_dim),h_swish() if use_hs else nn.ReLU(inplace = True),# dwnn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups = hidden_dim,bias = False),nn.BatchNorm2d(hidden_dim),# Squeeze-and-ExciteSELayer(hidden_dim) if use_se else nn.Sequential(),# Eca_layer(hidden_dim) if use_se else nn.Sequential(), # 1.13.2022h_swish() if use_hs else nn.ReLU(inplace = True),# pw-linearnn.Conv2d(hidden_dim, oup, 1, 1, 0, bias = False),nn.BatchNorm2d(oup),)def forward(self, x):y = self.conv(x)if self.identity:return x + yelse:return y
(2) 在models/yolo.py的parse_model函数,添加Conv_bn_hswish,MobileNetV3 两个模块
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,C3, C3TR,Conv_bn_hswish,MobileNetV3]:

(3) 构建yolov5s-mobileNetV3-samll.yaml 网络模型
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 6 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.5 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# Mobilenetv3-small backbone# MobileNetV3_InvertedResidual [out_ch, hid_ch, k_s, stride, SE, HardSwish]
backbone:# [from, number, module, args]# /2 /4 /6 /8,/16,/32 位置特征图的大小降半# MobileNetV3模块包含六个参数[out_ch, hidden_ch, kernel_size, stride, use_se, use_hs][[-1, 1, Conv_bn_hswish, [16, 2]], # 0-p1/2 320*320[-1, 1, MobileNetV3, [16, 16, 3, 2, 1, 0]], # 1-p2/4 160*160[-1, 1, MobileNetV3, [24, 72, 3, 2, 0, 0]], # 2-p3/8 80*80[-1, 1, MobileNetV3, [24, 88, 3, 1, 0, 0]], # 3 80*80[-1, 1, MobileNetV3, [40, 96, 5, 2, 1, 1]], # 4-p4/16 40*40[-1, 1, MobileNetV3, [40, 240, 5, 1, 1, 1]], # 5 40*40[-1, 1, MobileNetV3, [40, 240, 5, 1, 1, 1]], # 6 40*40[-1, 1, MobileNetV3, [48, 120, 5, 1, 1, 1]], # 7 40*40[-1, 1, MobileNetV3, [48, 144, 5, 1, 1, 1]], # 8 40*40[-1, 1, MobileNetV3, [96, 288, 5, 2, 1, 1]], # 9-p5/32 20*20[-1, 1, MobileNetV3, [96, 576, 5, 1, 1, 1]], # 10 20*20[-1, 1, MobileNetV3, [96, 576, 5, 1, 1, 1]], # 11 20*20]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [96, 1, 1]], # 12 20*20[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 13 40*40[[-1, 8], 1, Concat, [1]], # cat backbone P4 40*40[-1, 3, C3, [144, False]], # 15 40*40[-1, 1, Conv, [144, 1, 1]], # 16 40*40[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 17 80*80[[-1, 3], 1, Concat, [1]], # cat backbone P3 80*80[-1, 3, C3, [168, False]], # 19 (P3/8-small) 80*80[-1, 1, Conv, [168, 3, 2]], # 20 40*40[[-1, 16], 1, Concat, [1]], # cat head P4 40*40[-1, 3, C3, [312, False]], # 22 (P4/16-medium) 40*40[-1, 1, Conv, [312, 3, 2]], # 23 20*20[[-1, 12], 1, Concat, [1]], # cat head P5 20*20[-1, 3, C3, [408, False]], # 25 (P5/32-large) 20*20[[19, 22, 25], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
MobileNetV3-samll网络结构

- out_ch: 输出通道
- hidden_ch: 表示在Inverted residuals中的扩张通道数
- kernel_size: 卷积核大小
- stride: 步长
- use_se: 表示是否使用 SELayer,使用了是1,不使用是0
- use_hs: 表示使用 h_swish 还是 ReLU,使用h_swish是1,使用 ReLU是0
2.2、MobileNetV3-large
MobileNetV3-large和MobileNetV3-small 区别在于网络层数加深,深度因子,宽度因子不同以及yaml文件中head中concat不同层数拼接。我们就直接改动yaml的部分,其余参考上面步骤。
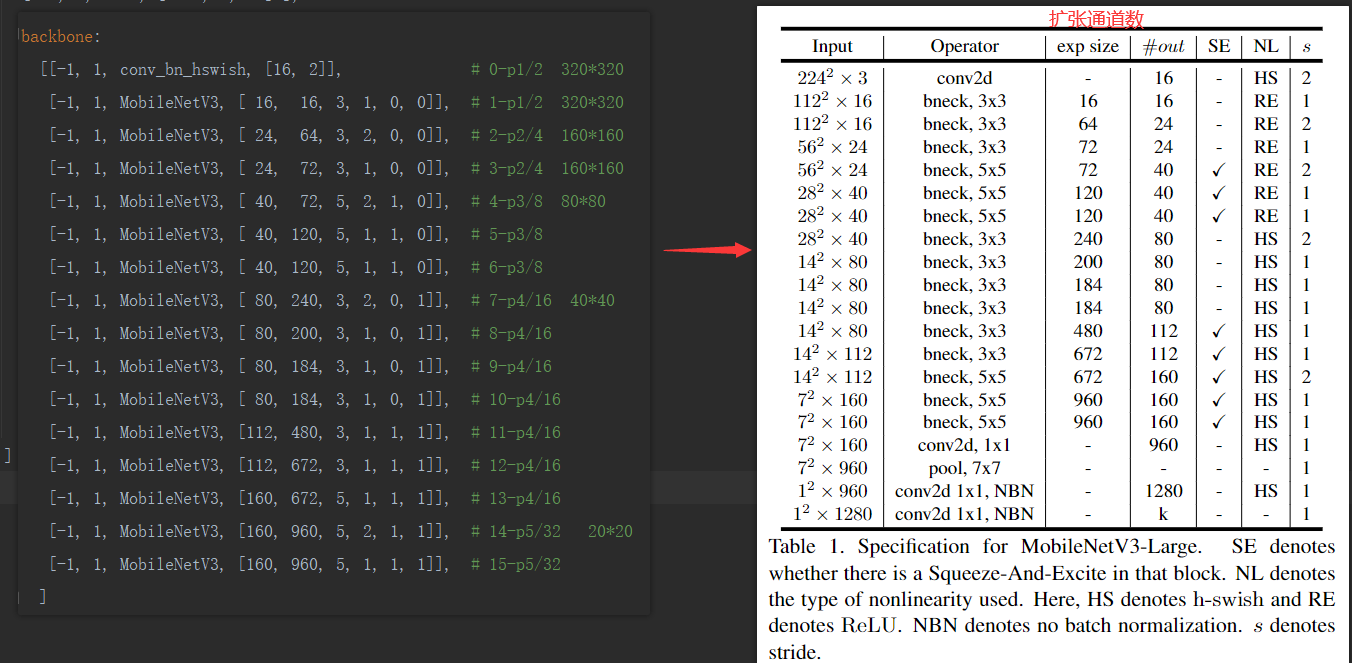
MobileNetV3-large.yaml
# Parameters
nc: 6 # number of classes
depth_multiple: 1 # model depth multiple
width_multiple: 0.5 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:[[-1, 1, conv_bn_hswish, [16, 2]], # 0-p1/2 320*320[-1, 1, MobileNetV3, [ 16, 16, 3, 1, 0, 0]], # 1-p1/2 320*320[-1, 1, MobileNetV3, [ 24, 64, 3, 2, 0, 0]], # 2-p2/4 160*160[-1, 1, MobileNetV3, [ 24, 72, 3, 1, 0, 0]], # 3-p2/4 160*160[-1, 1, MobileNetV3, [ 40, 72, 5, 2, 1, 0]], # 4-p3/8 80*80[-1, 1, MobileNetV3, [ 40, 120, 5, 1, 1, 0]], # 5-p3/8[-1, 1, MobileNetV3, [ 40, 120, 5, 1, 1, 0]], # 6-p3/8[-1, 1, MobileNetV3, [ 80, 240, 3, 2, 0, 1]], # 7-p4/16 40*40[-1, 1, MobileNetV3, [ 80, 200, 3, 1, 0, 1]], # 8-p4/16[-1, 1, MobileNetV3, [ 80, 184, 3, 1, 0, 1]], # 9-p4/16[-1, 1, MobileNetV3, [ 80, 184, 3, 1, 0, 1]], # 10-p4/16[-1, 1, MobileNetV3, [112, 480, 3, 1, 1, 1]], # 11-p4/16[-1, 1, MobileNetV3, [112, 672, 3, 1, 1, 1]], # 12-p4/16[-1, 1, MobileNetV3, [160, 672, 5, 1, 1, 1]], # 13-p4/16[-1, 1, MobileNetV3, [160, 960, 5, 2, 1, 1]], # 14-p5/32 20*20[-1, 1, MobileNetV3, [160, 960, 5, 1, 1, 1]], # 15-p5/32]
# YOLOv5 v6.0 head
head:[ [ -1, 1, Conv, [ 512, 1, 1 ] ],[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],[ [ -1, 13], 1, Concat, [ 1 ] ], # cat backbone P4[ -1, 1, C3, [ 512, False ] ], # 19[ -1, 1, Conv, [ 256, 1, 1 ] ],[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],[ [ -1, 6 ], 1, Concat, [ 1 ] ], # cat backbone P3[ -1, 1, C3, [ 256, False ] ], # 23 (P3/8-small)[ -1, 1, Conv, [ 256, 3, 2 ] ],[ [ -1, 20 ], 1, Concat, [ 1 ] ], # cat head P4[ -1, 1, C3, [ 512, False ] ], # 26 (P4/16-medium)[ -1, 1, Conv, [ 512, 3, 2 ] ],[ [ -1, 16 ], 1, Concat, [ 1 ] ], # cat head P5[ -1, 1, C3, [ 1024, False ] ], # 29 (P5/32-large)[ [ 23, 26, 29 ], 1, Detect, [ nc, anchors ] ], # Detect(P3, P4, P5)]3、运行效果
如果训练之后发现掉点纯属正常现象,因为轻量化网络在提速减少计算量的同时会降低精度
4、目标检测系列文章
- YOLOv5s网络模型讲解(一看就会)
- 生活垃圾数据集(YOLO版)
- YOLOv5如何训练自己的数据集
- 双向控制舵机(树莓派版)
- 树莓派部署YOLOv5目标检测(详细篇)
- YOLO_Tracking 实践 (环境搭建 & 案例测试)
- 目标检测:数据集划分 & XML数据集转YOLO标签
- DeepSort行人车辆识别系统(实现目标检测+跟踪+统计)
- YOLOv5参数大全(parse_opt篇)
- YOLOv5改进(一)-- 轻量化YOLOv5s模型
- YOLOv5改进(二)-- 目标检测优化点(添加小目标头检测)
- YOLOv5改进(三)-- 引进Focaler-IoU损失函数
- YOLOv5改进(四)–轻量化模型ShuffleNetv2