用户购物性别模型标签(USG)之决策树模型
一、USG模型引入:
首先了解一下,如何通过大数据来确定用户的真实性别,
经常谈论的用户精细化运营,到底是什么?
简单来讲,就是将网站的每个用户标签化,制作一个属于用户自己的网络身份证。然后,运营人员
通过身份证来确定活动的投放人群,圈定人群范围,更为精准的用户培养和管理。
当然,身份证最基本的信息就是姓名,年龄和性别,与现实不同的是,网络上用户填写的资料不一
定完全准确,还需要进行进一步的确认和评估。
确定性别这件事很重要,简单举个栗子,比如店铺想推荐新品的Bra,如果粗糙的
全部投放人群或者投放到不准确性别的人群,那后果可想而知了。
虽然能够通过用户的行为、购买和兴趣数据,了解用户的基本信息,但是仍然不清楚如何建
模?用什么语言建模?
购物性别的区分使用的是机器学习分类算法模型,但是算法也有很多分类,包含逻辑
回归,线性支持向量机,朴素贝叶斯模型和决策树,又该如何选择呢?
使用大数据 Spark MLlib 机器学习库, Java、Scala和Python 三种语言都支持。
其中,决策树的优点较多,主要是其变量处理灵活,不要求相互独立。可处理大维度的数
据,不用预先对模型的特征有所了解。对于表达复杂的非线性模式和特征的相互关系,模型相
对容易理解和解释,所以决定用决策树进行尝试。
核心难点:如何构建树,有三种方式
-
"ID3 算法:信息增益Info_Gain
-
C4.5 算法:信息增量率(比):lnfo Gain Rate
-
CART 算法:Classification And Regression Tree,基尼指数(Gini_Index)
建立在决策树算法之上: 集成融合学习算法 ,效果非常非常好的
-
GBT:梯度提升树算法,构建1棵树,迭代构建的树
-
RF:随机森林,构建N棵树,每个棵树不同,使用所有树预测,综合获取结果
USG:用户购物性别:
1.定义:通过用户购买的产品,确定用户的性别
2.思路:依据商品的名称、商品的颜色和商品的类别等,判断购买者的性别
如何确定USG?
基于用户购买商品确定性别的
用户在购物时,每个商品都有自己的属性,比如名称、颜色、类别等等,往往属于某个性别的用户
a.商品名称
剃须刀 male
口红 female
家用电器 male、female
b.商品颜色
衣服红色/亮色衣服 female
格子衫(黑灰色、杂色) male
中性颜色 male、female
c.商品类别
电子数码产品 male
美容保养 female
U_1001 product_01 male
U_1001 product_02 female
U_1001 product_03 male
U_1001 product_4 male
U_1001 product_05 female
U_1001 product_06 male
基于上面用户购买的物品,打上商品购买的性别,进行计算,最终确定用户购物性别
统计购物商品的个数
total =6
统计购物中男性商品个数
maletotal = 4
占比: maleRate = 4 /6 ≈ 0.666666666
统计购物中女性商品个数
femaletotal = 2
占比: femaleRate = 2/ 6 ≈ 0.333333333333
判断男性商品占比和女商品占比 if(maleRate >=0.6)时,USG = male if(femaleRate >=0.6)时,USG = female
else:USG = 末知
=========上述计算出用户购物性别USG,为什么还需要算法构建模型预测呢?=============
依据上述计算数据,构建分类算法模型以后,直接使用算法模型对用户进行预测即可,不需要在按照规则(经验) 进行分类操作。

业务目标: 精准投放,针对已有产品,寻找某性别偏好的精准人群进行广告投放。
技术目标:对用户购物性别识别:男性,女性,中性。
解决思路:选择一种分类算法,建立Spark模型,对模型进行应用。
线上投放:对得到的数据进行小范围内的测试投放,初期不宜过大扩大投放范围。
效果分析:对投放的用户进行数据分析,评估数据的准确性。若不够完美,则需要
重新建模和测试。
二、标签模型开发:
用户购物性别标签模型类: UsgModel ,继承基类 AbstractModel ,实现标签计算方法doTag 。
订单表:
需要将 订单商品表 中订单号 cordersn 关联到 订单表 中订单号 ordersn ,获取到对应的会员ID: memberid
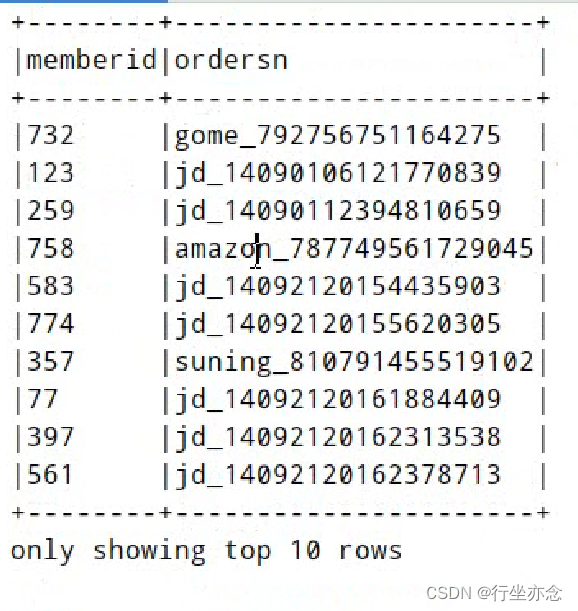
颜色维度表:

商品类别维度表:

读取订单表数据:
val session: SparkSession = businessDF.sparkSessionimport session.implicits._val ordersDF: DataFrame = spark.read.format("hbase").option("zkHosts", "bigdata-cdh01.itcast.cn").option("zkPort", "2181").option("hbaseTable", "tbl_tag_orders").option("family", "detail").option("selectFields", "memberid,ordersn").load()加载颜色维度数据并与ID进行相应的映射:
val colorsDF: DataFrame = {spark.read.format("jdbc").option("driver", "com.mysql.jdbc.Driver").option("url","jdbc:mysql://bigdata-cdh01.itcast.cn:3306/?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC").option("dbtable", "profile_tags.tbl_dim_colors").option("user", "root").option("password", "123456").load()}val colorColumn: Column = {// 声明变量var colorCol: Column = nullcolorsDF.as[(Int, String)].rdd.collectAsMap().foreach{case (colorId, colorName) =>if(null == colorCol){colorCol = when($"ogcolor".equalTo(colorName), colorId)}else{colorCol = colorCol.when($"ogcolor".equalTo(colorName), colorId)}}colorCol = colorCol.otherwise(0).as("color")// 返回colorCol}加载商品维度表数据并将其与对应ID进行映射:
val productsDF: DataFrame = {spark.read.format("jdbc").option("driver", "com.mysql.jdbc.Driver").option("url","jdbc:mysql://bigdata-cdh01.itcast.cn:3306/?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC").option("dbtable", "profile_tags.tbl_dim_products").option("user", "root").option("password", "123456").load()}var productColumn: Column = {// 声明变量var productCol: Column = nullproductsDF.as[(Int, String)].rdd.collectAsMap().foreach{case (productId, productName) =>if(null == productCol){productCol = when($"producttype".equalTo(productName), productId)}else{productCol = productCol.when($"producttype".equalTo(productName), productId)}}productCol = productCol.otherwise(0).as("product")// 返回productCol}根据运营规则标注的部分数据并关联订单数据,颜色维度和商品类别维度数据:
val labelColumn: Column = {when($"ogcolor".equalTo("樱花粉").or($"ogcolor".equalTo("白色")).or($"ogcolor".equalTo("香槟色")).or($"ogcolor".equalTo("香槟金")).or($"productType".equalTo("料理机")).or($"productType".equalTo("挂烫机")).or($"productType".equalTo("吸尘器/除螨仪")), 1) //女.otherwise(0)//男.alias("label")//决策树预测label}val goodsDF: DataFrame = businessDF// 关联订单数据:.join(ordersDF, businessDF("cordersn") === ordersDF("ordersn"))// 选择所需字段,使用when判断函数.select($"memberid".as("userId"), //colorColumn, // 颜色ColorColumnproductColumn, // 产品类别ProductColumn// 依据规则标注商品性别labelColumn)打标签,统计每个用户男女性商品个数占比:
// TODO: 直接使用标注数据,给用户打标签val predictionDF: DataFrame = goodsDF.select($"userId", $"label".as("prediction"))// 4. 按照用户ID分组,统计每个用户购物男性或女性商品个数及占比val genderDF: DataFrame = predictionDF.groupBy($"userId").agg(count($"userId").as("total"), // 某个用户购物商品总数// 判断label为0时,表示为男性商品,设置为1,使用sum函数累加sum(when($"prediction".equalTo(0), 1).otherwise(0)).as("maleTotal"),// 判断label为1时,表示为女性商品,设置为1,使用sum函数累加sum(when($"prediction".equalTo(1), 1).otherwise(0)).as("femaleTotal"))计算标签、计算占比、获取画像标签数据:
// 5.1 获取属性标签:tagRule和tagNameval rulesMap: Map[String, String] = TagTools.convertMap(tagDF)val rulesMapBroadcast: Broadcast[Map[String, String]] = session.sparkContext.broadcast(rulesMap)// 对每个用户,分别计算男性商品和女性商品占比,当占比大于等于0.6时,确定购物性别val gender_tag_udf: UserDefinedFunction = udf((total: Long, maleTotal: Long, femaleTotal: Long) => {// 计算占比val maleRate: Double = maleTotal / total.toDoubleval femaleRate: Double = femaleTotal / total.toDoubleif(maleRate >= 0.6){ // usg = 男性rulesMapBroadcast.value("0")}else if(femaleRate >= 0.6){ // usg =女性rulesMapBroadcast.value("1")}else{ // usg = 中性rulesMapBroadcast.value("-1")}})// 获取画像标签数据val modelDF: DataFrame = genderDF.select($"userId", //gender_tag_udf($"total", $"maleTotal", $"femaleTotal").as("usg"))三、ML Pipeline
在机器学习中,特别是在使用Apache Spark MLlib或Spark ML(Spark的机器学习库)时,ML Pipeline(机器学习流水线)是一个非常重要的概念。ML Pipeline提供了一种将多个机器学习步骤(如特征提取、转换、选择、模型训练和评估等)组合在一起的方式,使得数据处理和模型训练过程更加清晰、模块化和可重用。
DataFrame:数据框,一种数据结构,来源于SparkSQL中,DataFrame=Dataset[Row],存储要训练的和测试的数据集;
Transformer:转换器,一种算法Algorithm,必须实现transform方法。比如:模型 Model就是一个转换器,将输入的数据集DataFrame,转换为预测结果的数据集 DataFrame;
Estimator :估计器或者模型学习器,将数据集DataFrame转换为一个Transformer, 实现 fit() 方法,输入一个 DataFrame并产生一个 Model,即一个Transformer(转换 器);
Pipeline :管道,管道由一系列阶段组成,每个阶段都是 估计器或转换器;
Parameter :参数,无论是转换器Transformer还是模型学习器Estimator都是一个 算法,使用算法的时候必然有参数。
将USG中 构建决策树算法模型 代码修改为 训练Pipeline模型 ,整个管道Pipeline流程示意图如下:
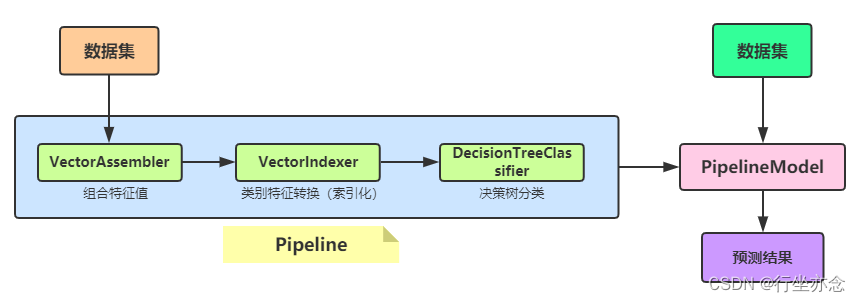
完整代码封装函数 trainPipelineModel如下:
def trainPipelineModel(dataframe: DataFrame): PipelineModel = {// 数据划分为训练数据集和测试数据集val Array(trainingDF, testingDF) = dataframe.randomSplit(Array(0.8, 0.2), seed = 123)// a. 特征向量化val assembler: VectorAssembler = new VectorAssembler().setInputCols(Array("color", "product")).setOutputCol("raw_features")// b. 类别特征进行索引val vectorIndexer: VectorIndexer = new VectorIndexer().setInputCol("raw_features").setOutputCol("features").setMaxCategories(30)// c. 构建决策树分类器val dtc: DecisionTreeClassifier = new DecisionTreeClassifier().setFeaturesCol("features").setLabelCol("label").setPredictionCol("prediction").setImpurity("gini") // 基尼系数.setMaxDepth(5) // 树的深度.setMaxBins(32) // 树的叶子数目// TODO: 构建Pipeline管道对象,组合模型学习器(算法)和转换器(模型)val pipeline: Pipeline = new Pipeline().setStages(Array(assembler, vectorIndexer, dtc))// 训练模型,使用训练数据集val pipelineModel: PipelineModel = pipeline.fit(trainingDF)// f. 模型评估val predictionDF: DataFrame = pipelineModel.transform(testingDF)predictionDF.show(100, truncate = false)println(s"accuracy = ${modelEvaluate(predictionDF, "accuracy")}")// 返回模型pipelineModel}ML Pipeline优缺点分析:
优点:
降低耦合度:将不同的处理逻辑封装成独立的阶段,每个阶段只关注自己的输入和输出,不需要知道其他阶段的细节。这使得添加、删除或修改阶段变得更加容易,且不影响整个流程的运行。
增加灵活性:通过配置化可以实现不同的业务走不同的流程,而不需要修改代码。这能够根据需求变化快速调整流程,提高开发效率和可维护性。
提高性能:可以利用多线程或异步机制来并行执行不同的阶段,从而提高整个流程的吞吐量和响应时间。
提高可读性:通过将复杂的机器学习模型分解为多个阶段,每个阶段负责特定的任务,使得整个模型的结构更加清晰,易于理解和维护。
可测试性强:由于不同的步骤之间相对独立,耦合较低,可以更方便地对每个步骤编写单元测试,从而提高代码质量。缺点:
调试困难:当流水线中的某个阶段出现问题时,可能需要逐个检查每个阶段以确定问题的根源,这可能会增加调试的复杂性和时间成本。
资源消耗:并行执行多个阶段可能会消耗更多的计算资源,包括CPU、内存和存储空间等。
配置和部署:配置和部署一个复杂的ML Pipeline可能需要一定的技术知识和经验,以确保所有组件能够正确协同工作。
注意
对管道调用 fit 方法的效果跟依次对每个评估器调用 fit 方法一样, 都是transform 输入并传递给下个步骤。 管道中最后一个评估器的所有方法,管道都有。例如,如果最后的评估器是一个分类器, Pipeline 可以当做分类器来用。如果最后一个评估器是转换器,管道也一样可以。
四、模型调优
交叉验证(Cross-Validation):
交叉验证(Cross-Validation) 是一种评估机器学习模型性能的方法,特别是当可用的训练数据较少时。这种方法通过重复使用数据来模拟训练集和测试集,从而得到模型性能的一个更可靠估计。以下是交叉验证的基本概念和一些常见的交叉验证策略:
K折交叉验证(K-Fold Cross-Validation):
- 将数据集分为K个大小相等的子集(或尽可能相等)。
- 对于每个子集,都将其视为测试集,而其余K-1个子集则作为训练集。
- 重复此过程K次,每次都使用不同的子集作为测试集。
- 最终,计算K次评估的平均值作为模型性能的估计。

五、总结:
在USG模型中,ML Pipeline(机器学习流水线)为使用决策树算法构建和评估模型提供了一个系统化的流程,确保了整个模型开发过程的一致性和可重复性。交叉验证通过将数据集划分为不同的子集,并轮流使用这些子集进行训练和测试,为模型提供了更为准确和可靠的性能评估。这有助于我们发现并避免过拟合,调整模型参数以达到最佳性能,以及在不同算法和特征集合中选择最佳模型。