【强化学习】马尔可夫决策过程MDP
1.马尔可夫决策过程MDP
1.1 MDP五元组
MDP=<S,A,P,R,γ>MDP=<\mathcal{S},\mathcal{A},\mathcal{P},\mathcal{R},\mathcal{\gamma}>MDP=<S,A,P,R,γ>,其中:
- S\mathcal{S}S:状态空间
- A\mathcal{A}A:动作空间
- P\mathcal{P}P:P(s′∣s,a)\mathcal{P(s'|s,a)}P(s′∣s,a)为状态转移函数,表示采取动作aaa从状态sss转移到状态s′s's′的概率
- R\mathcal{R}R:奖励函数R(s,a)\mathcal{R(s,a)}R(s,a),表示在状态sss下采取动作aaa后的奖励。
- γ\mathcal{\gamma}γ:折扣因子γ∈[0,1)\gamma \in [0,1)γ∈[0,1),取值越大越注重长期积累的奖励。
- MDP与MRP的区分
MDP与马尔可夫奖励过程MRP=<S,P,r,γ>MRP=<\mathcal{S},\mathcal{P},\mathcal{r},\mathcal{\gamma}>MRP=<S,P,r,γ>的区别在于状态转移和奖励函数不依赖于动作aaa。举例:船在海上自由飘荡是一个MRP,船由水手掌舵在海上航行是一个MDP。
1.2 Agent与MDP环境的交互
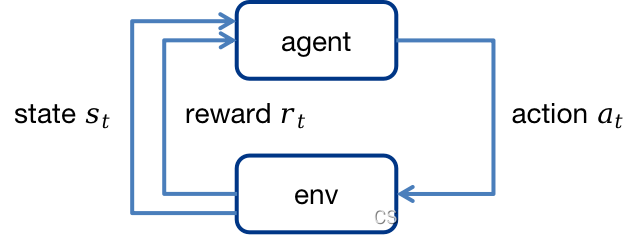
Agent通过rtr_trt学习策略,agent通过学习到的策略针对当前环境状态sts_tst采取相应动作ata_tat,该动作与环境交互后,环境中的状态将转移到新的状态st+1s_{t+1}st+1,同时获得奖励rt+1r_{t+1}rt+1。Agent的目标是最大化累积奖励的期望。
1.2.1 策略policy
策略用π\piπ表示,策略是一个函数,是agent学习的目标。策略会输出在状态sss下采取各个action的概率,即π(a∣s)=P(At=a∣St=s)\pi(a|s)=P(A_t=a|S_t=s)π(a∣s)=P(At=a∣St=s).
1.2.2 状态价值函数V(s)V(s)V(s)
Vπ(s)V^\pi(s)Vπ(s)表示从状态sss出发,采取策略π\piπ获得回报的期望,即
Vπ(s)=Eπ[Gt∣St=s]V^\pi(s) = E_\pi[G_t|S_t=s] Vπ(s)=Eπ[Gt∣St=s]
1.2.3 动作价值函数Q(a|s)
Qπ(a∣s)Q^\pi(a|s)Qπ(a∣s)表示MDP遵循策略π\piπ,在状态sss下采取动作aaa后得到回报的期望,即:
Qπ(a∣s)=Eπ[Gt∣St=s,At=a]Q^\pi(a|s)= E_\pi[G_t|S_t=s,A_t=a] Qπ(a∣s)=Eπ[Gt∣St=s,At=a]
- Vπ(s)V^\pi(s)Vπ(s) 与Qπ(a∣s)Q^\pi(a|s)Qπ(a∣s)的关系?
使用策略π\piπ,Vπ(s)V^\pi(s)Vπ(s) 为采取动作aaa的概率乘在状态sss下采取动作aaa的动作价值的累加和,即:
Vπ(s)=∑a∈Aπ(a∣s)Qπ(a∣s)V^\pi(s)=\sum_{a\in \mathcal{A}}\pi(a|s)Q^\pi(a|s)Vπ(s)=a∈A∑π(a∣s)Qπ(a∣s)
1.2.4 贝尔曼期望方程
Vπ(s)=Eπ[Gt∣St=s]=Eπ[Rt+γVπ(s′)∣St=s]=r(s,a)+γ\begin{aligned} V^\pi(s) &= E_\pi[G_t|S_t=s]\\ &=E_\pi[R_t+\gamma V^\pi(s')|S_t=s]\\ & =r(s,a)+\gamma \end{aligned} Vπ(s)=Eπ[Gt∣St=s]=Eπ[Rt+γVπ(s′)∣St=s]=r(s,a)+γ
Qπ(a∣s)=Eπ[Gt∣St=s,At=a]=Eπ[Rt+γQπ(s′∣s,a)∣St=s,At=a]\begin{aligned} Q^\pi(a|s) &= E_\pi[G_t|S_t=s,A_t=a]\\ &=E_\pi[R_t+\gamma Q^\pi(s'|s,a)|S_t=s,A_t=a] \end{aligned} Qπ(a∣s)=Eπ[Gt∣St=s,At=a]=Eπ[Rt+γQπ(s′∣s,a)∣St=s,At=a]