加速模型训练 GPU cudnn
GPU的使用
在定义模型时,如果没有特定的GPU设置,会使用 torch.nn.DataParallel 将模型并行化,充分利用多GPU的性能,这在加速训练上有显著影响。
model = torch.nn.DataParallel(model).cuda()cudnn 的配置:
cudnn.benchmark = True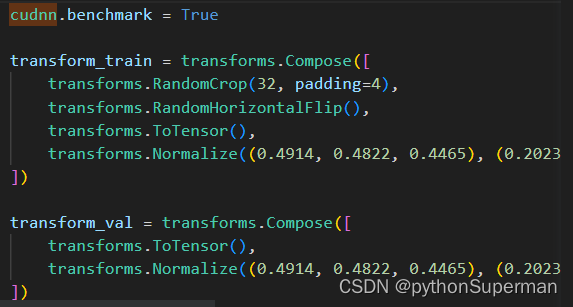
缺点:
加了之后论文不能复现
在定义模型时,如果没有特定的GPU设置,会使用 torch.nn.DataParallel 将模型并行化,充分利用多GPU的性能,这在加速训练上有显著影响。
model = torch.nn.DataParallel(model).cuda()cudnn.benchmark = True
加了之后论文不能复现