论文阅读》学习了解自己:一个粗略到精细的个性化对话生成的人物感知训练框架 AAAI 2023
《论文阅读》学习了解自己:一个粗略到精细的个性化对话生成的人物感知训练框架 AAAI 2023
- 前言
- 简介
- 研究现状
- 任务定义
- 模型架构
- Learning to know myself
- Learning to avoid Misidentification
- 损失函数
- 实验结果
- 消融实验
前言
亲身阅读感受分享,细节画图解释,再也不用担心看不懂论文啦~
无抄袭,无复制,纯手工敲击键盘~
今天为大家带来的是《Learning to Know Myself: A Coarse-to-Fine Persona-Aware Training Framework for Personalized Dialogue Generation》

出版:AAAI
时间:2023
类型:个性化对话生成
特点:粗粒度;细粒度;个性化;多样性;回复生成
作者:Yunpeng Li
第一作者机构:Institute of Information Engineering, Chinese Academy of Sciences, Beijing, China
简介
目前存在的问题是对话中个性化信息的稀疏性,仅利用MLE(Maximum Likelihood Estimation)会导致模型生成的回复与给定的个性化信息不相关或不一致,为了解决这一问题,本文提出两阶段个性化感知的训练框架来提升个性一致性
粗粒度阶段:构建个性化问答对,通过训练模型回答个性化感知的问题,使得模型对于个性化信息高度敏感
细粒度阶段:通过对比学习显式挖掘一致性回复和生成不一致性回复之间的差别,迫使模型更加关注关键的个性化信息
研究现状
目前对于融入个性化信息的方法有:
1)使用隐变量
2)大预训练语言模型
但是这些方法是通过 MLE 损失计算的,这样通常容易生成最高频词,导致生成个性化不一致或不相关的回复

从上图,作者总结到,目前融入个性化信息主要存在的问题:
一方面,回复中包含的个性化信息太少,导致模型认为这些信息是噪声
另一方面,模型对于个性化信息中关键信息缺乏关注,导致生成个性化话相关但不一致的回复,如上述 response 2
此外,作者认为最主要是因为模型无法始终保持一致性,而这和自我意识有关
a self-conscious human should have the capacity to avoid misidentifcation, which means he can not only pick himself out but also avoid taking another person to be him.
中心思想是从粗略地了解自我学习到精细地避免误识别,提高回复的一致性
任务定义

模型架构

Learning to know myself
这部分算是自问自答吧,首先需要构造一个具有个性感知问答对
通过 DNLI 数据集提供的 P P P,构建三元组( e 1 , r , e r e_1, r, e_r e1,r,er),其中 r r r 是 r 1 _ r 2 r_1\_r_2 r1_r2 的形式, r 1 r_1 r1 是动词, r 2 r_2 r2 是名词
这样的话就可以根据三元组构建问题,模板为 “What r 2 r_2 r2 do e 1 e_1 e1 r 1 r_1 r1 ?"
三元组:[I, like sports,basketball]
问题:What sports do you like?
在生成时,由于没有个性化信息,所以需要通过用 Roberta_large 在 DNLI 数据集上微调通过输入个性化信息,得到关系,然后对于实体信息,则需要抓取输入的关键词
上述为实验的先决条件,在获取数据集之后,我们得到了 query-response(个性化信息) 对,通过输入 query 生成 response 来训练模型的自我意识
Learning to avoid Misidentification

对比学习最关键的部分就在于构造负样本对,我们直接来学习一下这个部分
为了找到回复中最关键的个性化信息,比较个性化信息与 gold response 和去掉每一个词在回复中的蕴含得分,差值为该词的个性化得分
C k ( y i ) = p ( E ∣ [ P j ; Y ] ; ϕ ) − p ( E ∣ [ P j ; Y / i ] ; ϕ ) C_k(y_i) = p(E|[P_j ; Y ]; ϕ) − p(E|[P_j ; Y_{/i}]; ϕ) Ck(yi)=p(E∣[Pj;Y];ϕ)−p(E∣[Pj;Y/i];ϕ)
然后找到前 K 个最高的个性化得分,用 [ M A S K ] [MASK] [MASK] 遮盖,送入 MLM 模型(不需要微调)中生成 [ M A S K ] [MASK] [MASK] 被掩盖的词,如果生成的词就是原来的词,则使用第二可能的词,这样就构造了 K 个不同的负样本 { Y i − } i = 1 K \{Y^-_i\}_{i=1}^K {Yi−}i=1K
损失函数

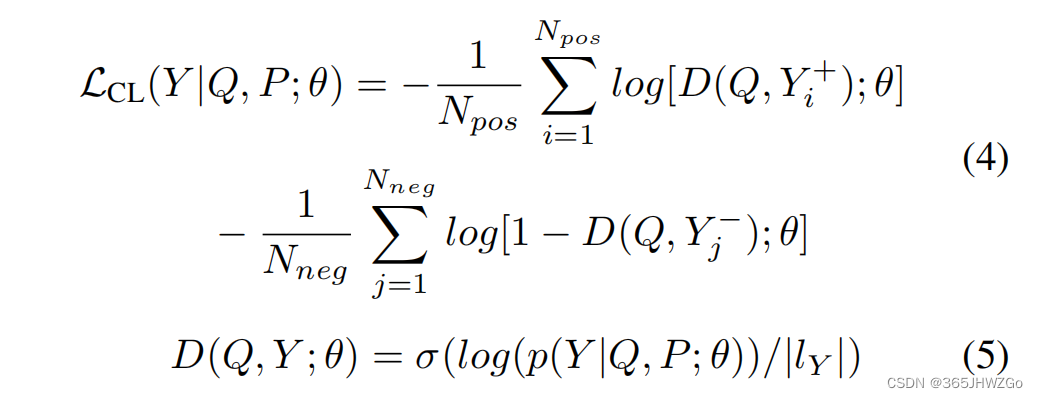

实验结果

消融实验
