【立体匹配论文阅读】AANet: Adaptive Aggregation Network for Efficient Stereo Matching
Authors: Haofei Xu, Juyong Zhang
Link: https://arxiv.org/abs/2004.09548
Years: 2020
Credit

Novelty and Question set up
主流的立体匹配模型的代价聚合操作主要用了3D卷积,这部分操作的算力和内存消耗过大,因此作者提出一种新的模型AANet,旨在摒弃所有3D卷积操作。具体来说,作者提出多分辨率代价体构建,用基于稀疏采样点的尺度内聚合模块解决视差图的edge-fattening问题,用跨尺度聚合模块处理弱纹理问题。
Solutions and Details
-
总体架构
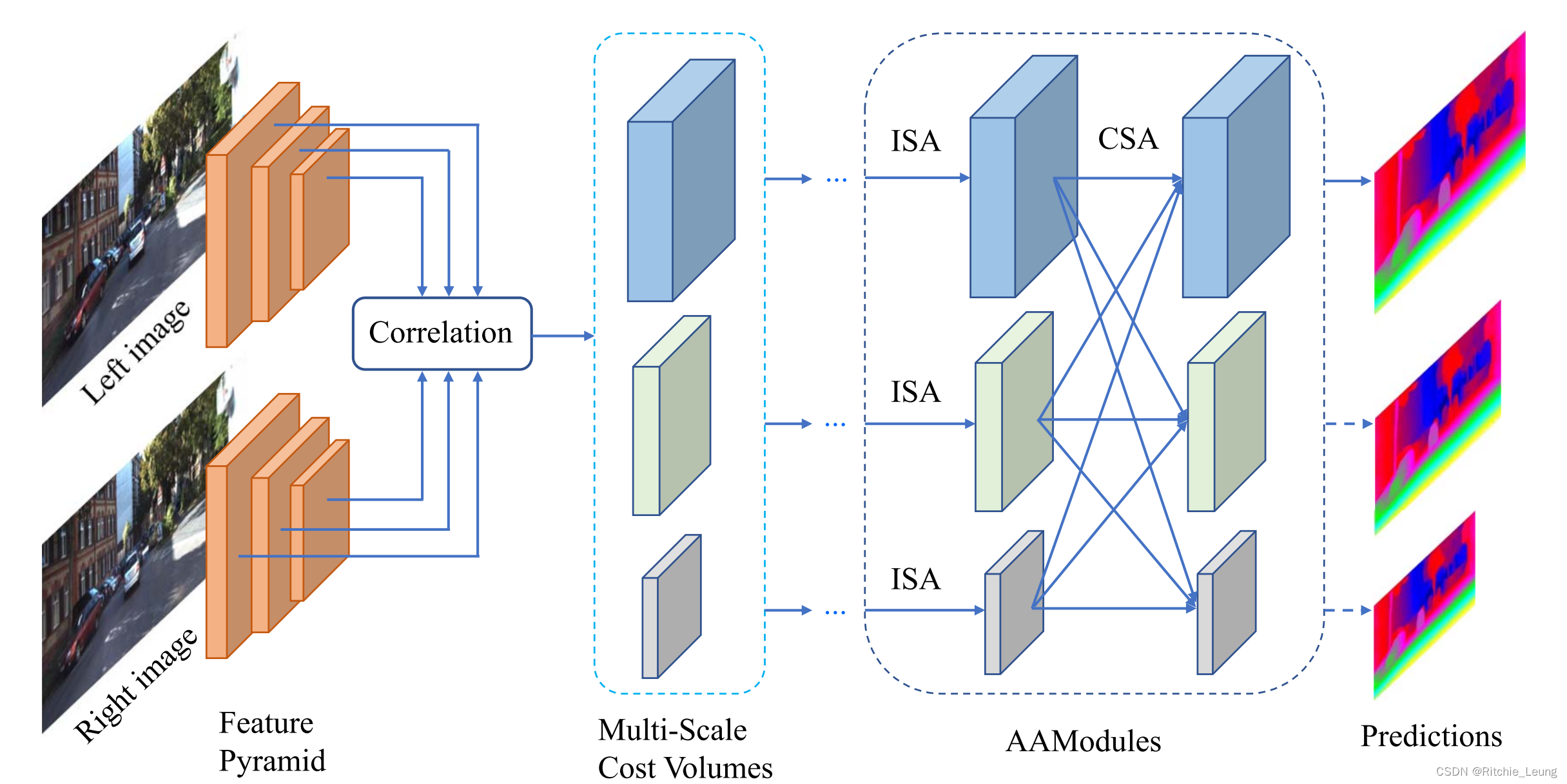
与流行的端到端立体匹配方法一样,AANet同样包含四部分:特征提取、构建代价体、代价聚合和输出视差图。在提取特征部分,会输出multi-scale feature map,分别对应不同stage的特征输出,然后利用这不同尺寸的特征图分别构建各自尺寸的代价体。
作者在这构建的是相关性(correlation)代价体,对第sss个stage的左视图特征FlsF^{s}_{l}Fls和右视图特征FrsF^{s}_{r}Frs,计算视差ddd的相关度,计算方式如下
Cs(d,h,w)=1N⟨Fls(h,w),Frs(h,w−d)⟩C^{s}(d,h,w) = \frac{1}{N}\langle F^{s}_{l}(h,w),F^{s}_{r}(h,w-d)\rangle Cs(d,h,w)=N1⟨Fls(h,w),Frs(h,w−d)⟩
计算出来的代价体是三维的,因为特征通道维度上已通过内积操作进行加和而消除掉了。
随后作者设计尺度内聚合模块(ISA)和跨尺度聚合模块(CSA)对代价体进行代价聚合,并输出对应尺度的视差图。
-
尺度内聚合模块
作者关注到一个常见的问题,在不连续视差中容易出现edge-fattening问题,这个问题本质是常规卷积窗口在边缘时容易聚合了较大视差邻域的代价,因此提出一个自适应的弹性稀疏采样方案,即对特定的视差位置,与它语义上关联度更高的位置进行聚合,整体思路与deformable convolution(v2)一致,所以直接采用他们的实现
C~(d,p)=∑k=1K2wk⋅C(d,p+pk+Δpk)⋅mk\tilde{C}(d,p)=\sum_{k=1}^{K^{2}}{w_k}\cdot{C(d,p+p_{k}+\Delta{p_k})}\cdot{m_k} C~(d,p)=k=1∑K2wk⋅C(d,p+pk+Δpk)⋅mk
与原始deformable convolution稍有不同的是,Δpk\Delta{p_k}Δpk和mkm_kmk是对所有channel共享的,作者的实现是将视差等分成GGG组,每一组使用单独的一套Δpk\Delta{p_k}Δpk和mkm_kmk。
一个ISA模块即由3个conv和一个残差结构组合而成,类似bottleneck的设计,三层分别是1×1,3×3,1×1{1}\times{1},{3}\times{3},{1}\times{1}1×1,3×3,1×1卷积,而其中的3×3{3}\times{3}3×3卷积即是deformable convolution,但与bottleneck不一样的是作者这里三层采用的一样的channel数,没有压缩通道和计算量。
-
跨尺度聚合模块
而立体匹配的另一个问题,弱纹理匹配问题,比较容易在粗颗粒度的代价体中找到纹理信息,因此作者设计了一个跨尺度的聚合模块来解决此类问题。尺度sss的聚合结果可以表示为
C^s=∑k=1Sfk(C~k),s=1,2,...,S\hat{C}^{s}=\sum_{k=1}^{S}{f_k(\tilde{C}^{k})},s=1,2,...,S C^s=k=1∑Sfk(C~k),s=1,2,...,S
这个设计的灵感来源HRNet的跨尺度特征聚合,因此函数fkf_kfk定义为
fk={I,k=s(s−k)convs3×3,stride2,k<supsampling⊕conv1×1,k>s\begin{equation} f_k= \begin{cases} \mathcal{I}& \text{,k=s} \\ (s-k)convs_{3\times{3},stride2}& \text{,k<s} \\upsampling{\oplus}conv_{1\times{1}}& \text{,k>s} \end{cases} \end{equation} fk=⎩⎨⎧I(s−k)convs3×3,stride2upsampling⊕conv1×1,k=s,k<s,k>s
虽然与HRNet结构相似,但设计的初衷和作用是不同的,AANet主要为了聚合不同尺度下代价体蕴含的几何信息,而HRNet是为了学习更丰富的特征。
-
AANet设计和损失函数设计
上述的ISA+CSA模块组成最终的AAModule(Adaptive Aggregation Module),在AANet中,作者采用了6个AAModule进行代价聚合,头3个用了普通2d卷积,后3个才用了deformable convolution。
在特征提取部分,作者采用类似ResNet的结构,将其中6个普通2d替换成deformable convolution。然后利用FPN结构分别提取出1/3x,1/6x,1/12x三个分辨率的特征图。最后利用StereoDRNet提出的refine模块来将1/3x视差图refine到原始输入尺寸。视差图的输出依然是用了softargmin来实现。
KITTI数据集提供的ground truth是稀疏深度,因此作者利用GA-Net的估计视差图作为软标签Dpseudo(⋅)D_{pseudo}(\cdot)Dpseudo(⋅)。对每个分辨率输出的视差图,首先双线性插值到原始尺寸,然后计算损失
Li=∑pV(p)⋅L(Dpredi(p),Dgt(p))+(1−V(p))⋅L(Dpredi(p),Dpseudo(p))L_i =\sum_{p}{V(p)\cdot{\mathcal{L}(D^{i}_{pred}(p),D_{gt}(p))}} + (1-V(p))\cdot{\mathcal{L}(D^{i}_{pred}(p), D_{pseudo}{(p)})} Li=p∑V(p)⋅L(Dpredi(p),Dgt(p))+(1−V(p))⋅L(Dpredi(p),Dpseudo(p))
V(p)V(p)V(p)表示像素位置ppp上是否真实ground truth,L\mathcal{L}L表示smooth L1。整个网络的损失则是各分辨率之间的加权平均数
L=∑iλi⋅LiL = \sum_i{\lambda_{i}}\cdot{L_i} L=i∑λi⋅Li
Results
-
作者在Sceneflow和KITTI-2012/2015数据集上进行验证和对比实验
-
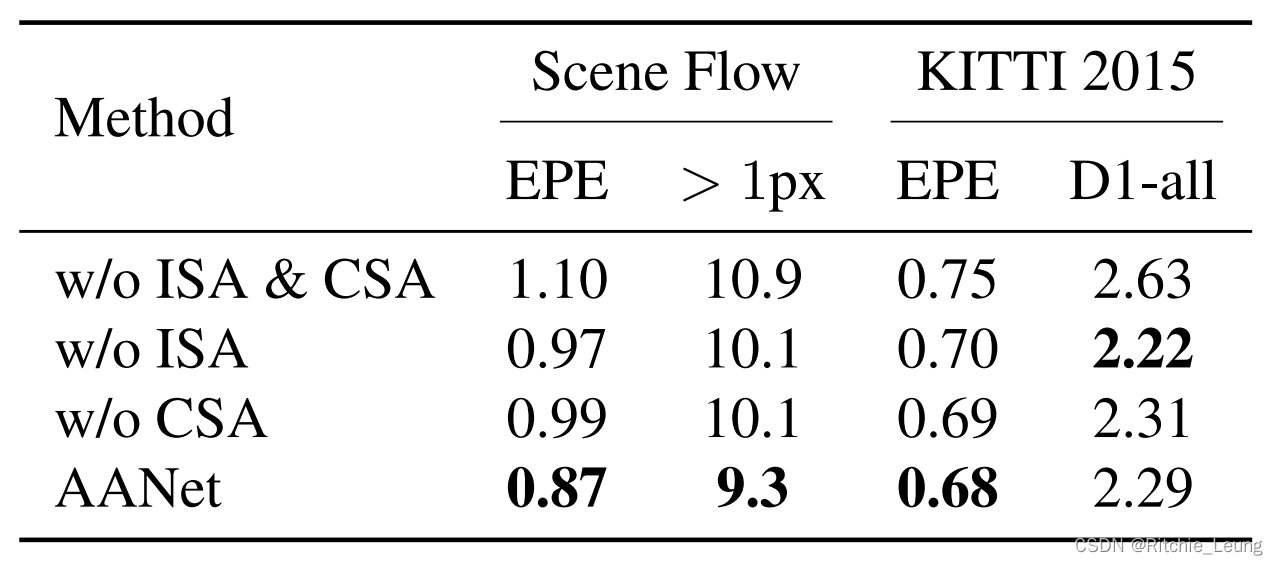
首先对比两个提出的主要聚合模块的作用,可以看出,ISA和CSA都用上效果是最好的
-
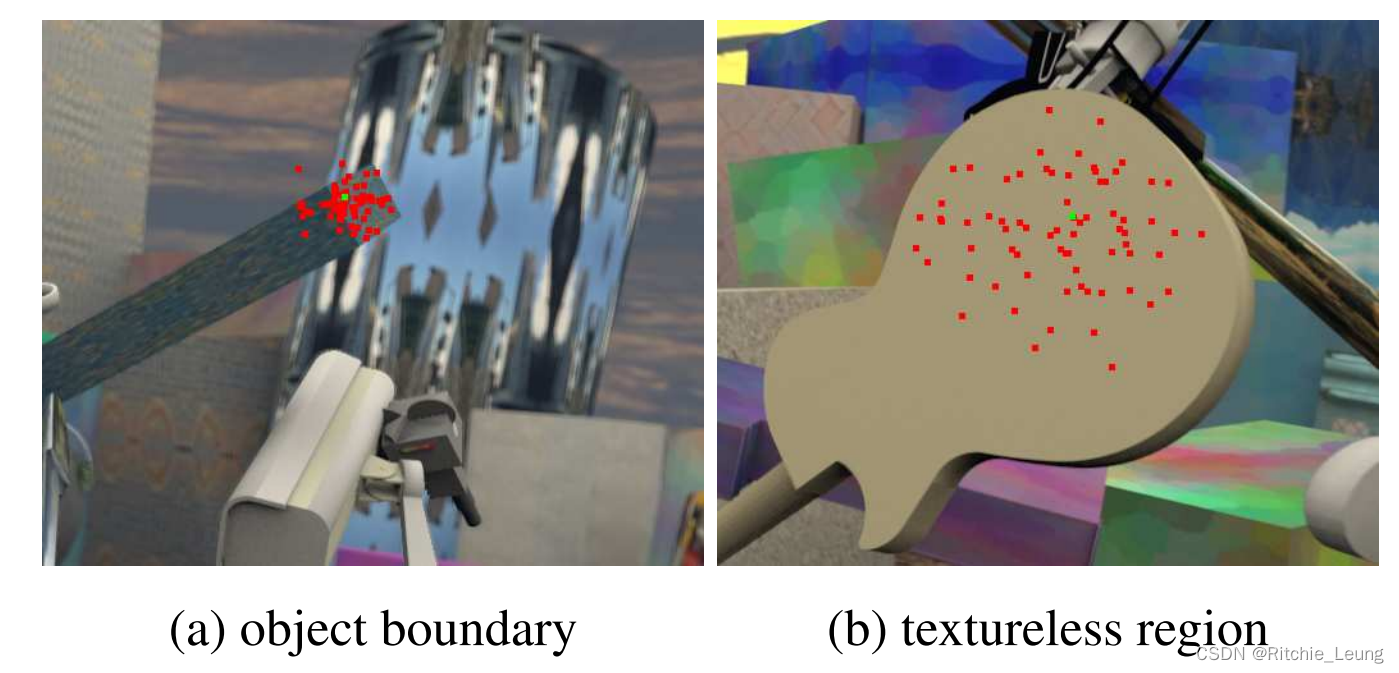
可视化证明ISA的自适应能力:在边界处时会选择临近但语义相似位置的特征,而在弱纹理区域,则倾向于搜索范围更广的区域
-
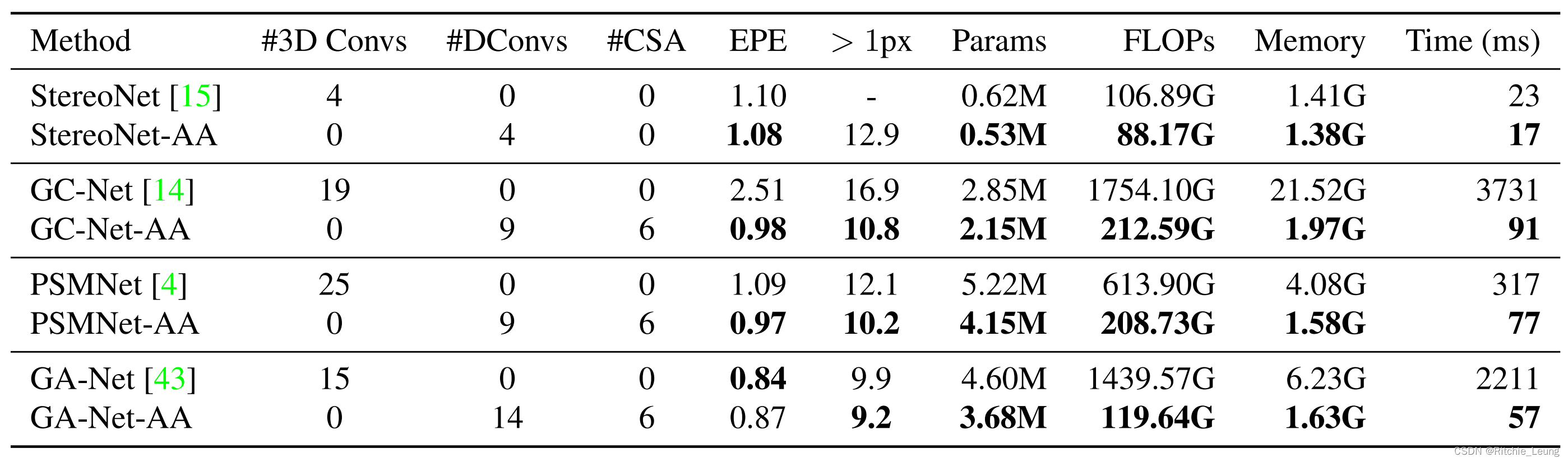
在各个使用3d卷积进行代价聚合的模型上使用AAModule进行替换,精度-速度均衡会变得更好
-
与其他SOTA在Sceneflow上进行比较,精度-速度均衡基本上能达到最佳,AANet*是网络深度更深的改进版本

-
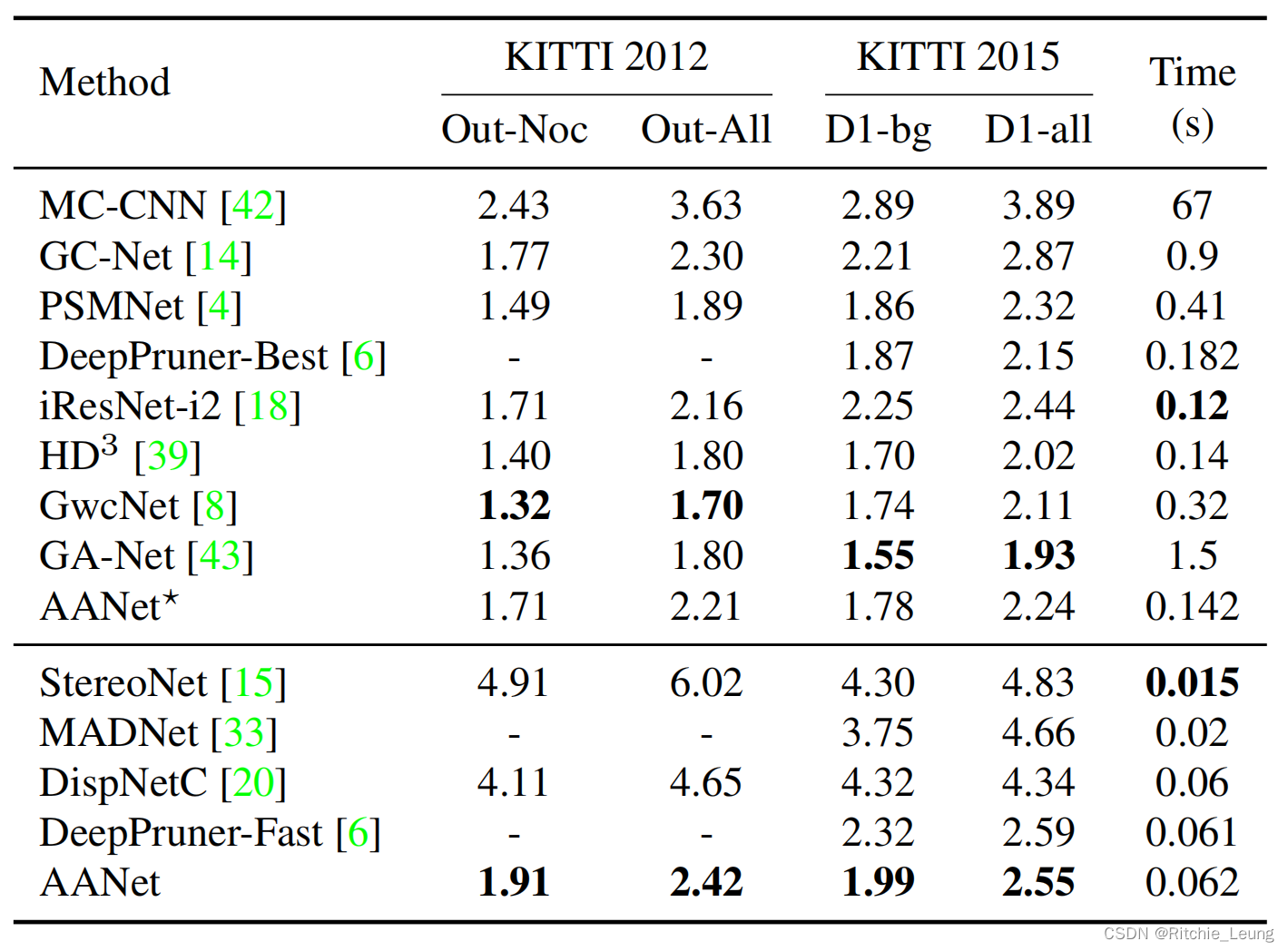
在KITTI-2012/2015上与其他SOTA比较精度,依然能达到较好的水平
Thoughts
- 作者提出的AAModule包含了尺度内和跨尺度聚合模块,针对对应的问题进行特定优化,相对比较直观
- 其中ISA使用了deformable convolution,设计比较巧妙,但在实际落地,尤其是端侧上,deformable convolution可能对硬件不太友好
- 作者使用相关性构建代价体而非特征拼接,因此可以直接使用2d卷积进行代价聚合,在参数量和计算量上都有一定优势,但引入了deformable convolution则一定程度上抵消了这个优势
- CSA模块仿照HRNet的操作设计也很巧妙,但同样会面临计算并行度问题