Mixed-precision计算原理(FP32+FP16)
原文:
https://lightning.ai/pages/community/tutorial/accelerating-large-language-models-with-mixed-precision-techniques/
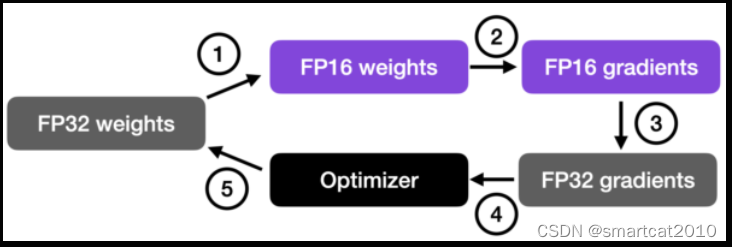
This approach allows for efficient training while maintaining the accuracy and stability of the neural network.
In more detail, the steps are as follows.
- Convert weights to FP16: In this step, the weights (or parameters) of the neural network, which are initially in FP32 format, are converted to lower-precision FP16 format. This reduces the memory footprint and allows for faster computation, as FP16 operations require less memory and can be processed more quickly by the hardware.
- Compute gradients: The forward and backward passes of the neural network are performed using the lower-precision FP16 weights. This step calculates the gradients (partial derivatives) of the loss function with respect to the network’s weights, which are used to update the weights during the optimization process.
- Convert gradients to FP32: After computing the gradients in FP16, they are converted back to the higher-precision FP32 format. This conversion is essential for maintaining numerical stability and avoiding issues such as vanishing or exploding gradients that can occur when using lower-precision arithmetic.
- Multiply by learning rate and update weights: Now in FP32 format, the gradients are multiplied by a learning rate (a scalar value that determines the step size during optimization).
- The product from step 4 is then used to update the original FP32 neural network weights. The learning rate helps control the convergence of the optimization process and is crucial for achieving good performance.
简而言之:
g * lr + w老 --> w新,这里的g、w老、w新,都是FP32的;
其余计算梯度中的w、activation、gradient等,全部都是FP16的;
训练效果:
耗时缩减为FP32的1/2 ~ 1/3
显存变化不大(因为,增加显存:weight多专一份FP16,减少显存:forward时保存的activation变成FP16了,二者基本抵消)
推理效果:
显存减少一半;耗时缩减为FP32的1/2;
使用FP16后的test accuracy反而上升,解释:(正则效应,带来噪音,帮助模型泛化得更好,减少过拟合)
A likely explanation is that this is due to regularizing effects of using a lower precision. Lower precision may introduce some level of noise in the training process, which can help the model generalize better and reduce overfitting, potentially leading to higher accuracy on the validation and test sets.
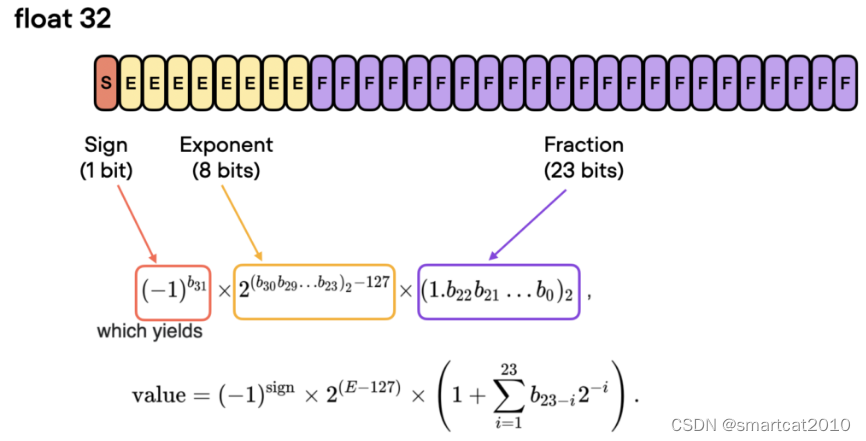
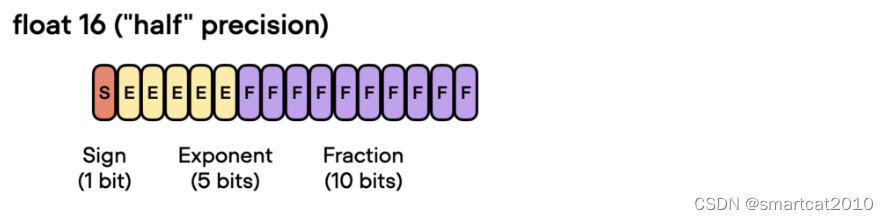
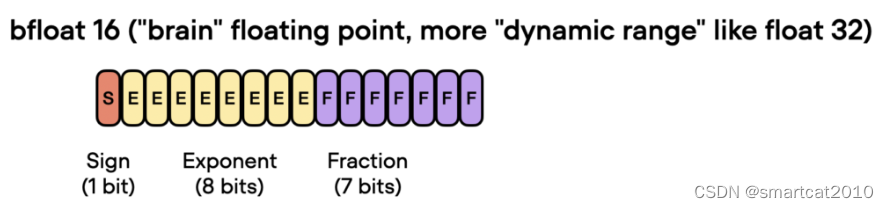
bf16,指数位增加,所以能覆盖更大的数值范围,所以能使训练过程更鲁棒,减少overflow和underflow的出现概率;