浏览器的下载行为基本原理
浏览器解析
在使用浏览器访问某些资源时,有些资源是直接下载有些资源是直接打开。例如前端的html,xml,css,图片等资源都是直接打开,而txt,excel等文件是直接下载。那么如何控制访问一个资源时是下载文件还是打开文件呢?
浏览器展现的内容都是解析后端或者静态的类HTML文件,前端的都知道HTML构成浏览器的内容,CSS构成浏览器的样式,Javascript构成浏览器的行为,这些在后端都是一个个的文件,这些文件通过网络传递到浏览器会被浏览器解析出来构成用户看到的内容。
所以浏览器可以理解为一个解析多种文件的软件,主流浏览器支持解析如下的文件:

浏览器行为

常见的浏览器行为有上传,下载,预览,打开等。浏览器默认的行为是解析打开,有些时候需要开发者控制浏览器行为,来确定操作时打开开始下载等。浏览器定义了多种机制来应对文件,这些机制旨在适应不同的使用场景和用户偏好:
a标签指向文件地址
使用<a>标签的href属性指向文件的 URL,当用户点击该链接时,浏览器会触发一个文件行为。
a标签是跳转标签,如果跳转的文件是浏览可以直接解析的文件就会直接打开。如下三种文件的跳转:
<!DOCTYPE html>
<html><head></head><body><a href="./111.png">图片跳转</a><a href="./111.txt">文本文件跳转</a><a href="./111.xml">标签语言跳转</a></body></html>

通过a标签连接的可解析的文件会被直接打开。如果是浏览器不能解析的文件呢,如下:
<!DOCTYPE html>
<html><head></head><body><a href="./111.xlsx">excel表格文件</a><a href="./111.docx">word文档文件</a></body></html>
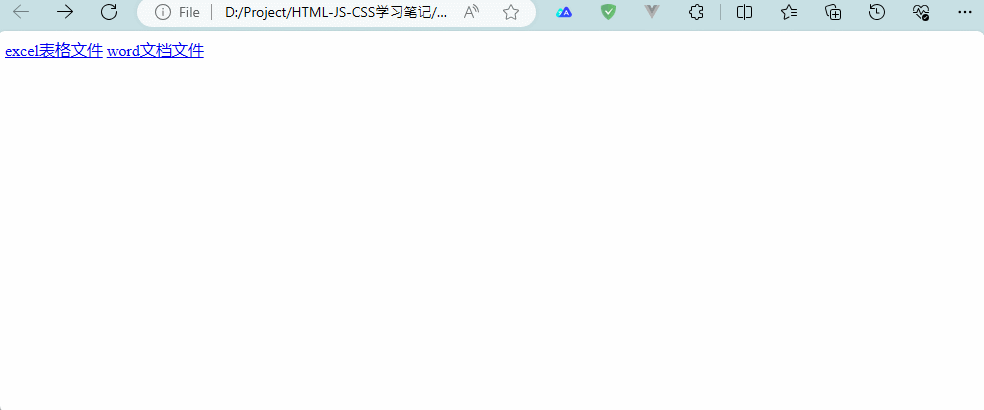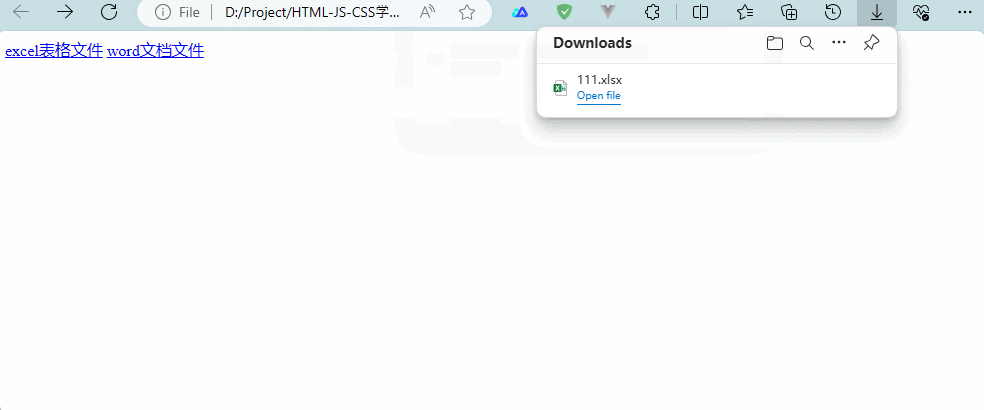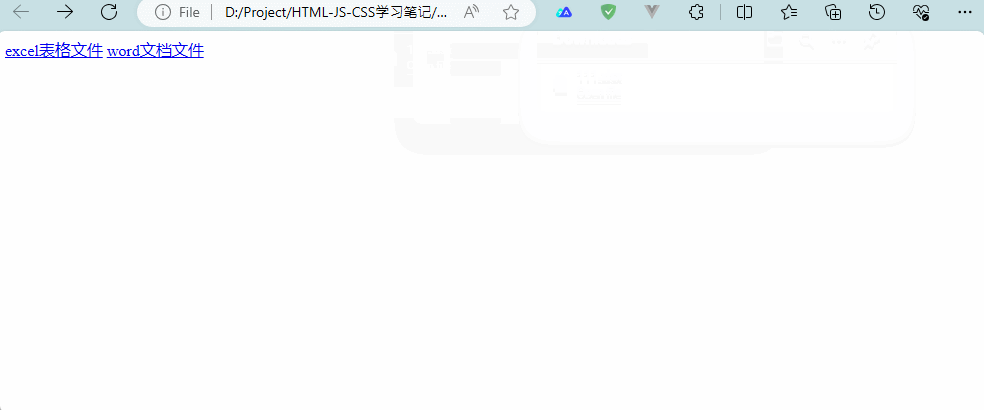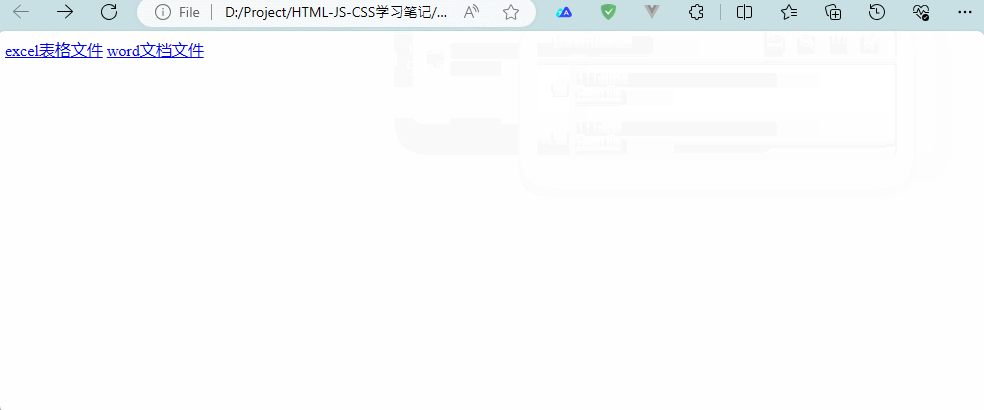
遇到这种不能解析的文件就会自动触发浏览器的下载功能。
<a>标签会把跳转的访问资源当成一个文件如果可以被解析就会打开,不能解析就会下载,a标签会直接暴露资源的地址,另外资源一般有两种协议file://和https://。
对于远程服务器来说都是https://协议。
<a>标签相对开放完全又浏览器控制,依照浏览器规则。
window.open()
由<a>标签可知浏览器访问某个资源时会直接解析该资源,不能解析的会触发下载行为,window.open()具有相似的行为。
<!DOCTYPE html>
<html><head></head><body><button type="button" onclick="downpng()">图片处理</button><button type="button" onclick="downtxt()">txt处理</button><button type="button" onclick="downxml()">xml</button><button type="button" onclick="downdocx()">docx处理</button><button type="button" onclick="downxlsx()">xlsx处理</button></body><script>function downpng(){console.log("render")window.open('./111.png')}function downtxt(){console.log("render")window.open('./111.txt')}function downxml(){console.log("render")window.open('./111.xml')}function downdocx(){console.log("render")window.open('./111.docx')}function downxlsx(){console.log("render")window.open('./111.xlsx')}</script></html>
Javascript调用DOM对象实现文件下载
JS调用dom的方式适用于用户输入数据生成文件的场景,此时文件并不存在,需要js生成。使用 JavaScript 动态创建一个 <a> 元素或修改现有元素的 href 和 download 属性,然后模拟点击事件来启动下载。
<html>
<body><h3> Create the file from the custom text and allow users to download that file </h3><p> Click the below button to download the file with custom text. </p><input type = "text" id = "file_text" value = "Entetr some text here."><button type = "button" onclick = "startDownload()"> Download </button>
</body><script>function startDownload() {let user_input = document.getElementById('file_text');let texts = user_input.value;var hidden_a = document.createElement('a');hidden_a.setAttribute('href', 'data:text/plain;charset=utf-8, '+ encodeURIComponent(texts));hidden_a.setAttribute('download', "text_file");document.body.appendChild(hidden_a);hidden_a.click();document.body.removeChild(hidden_a);}</script>
</html>参考文档:如何在点击HTML按钮或JavaScript时触发文件下载
-
hidden_a:这是一个HTML元素,是一个链接(
<a>标签)。 -
setAttribute:这是JavaScript中的一个方法,用于设置指定元素的属性值, -
href:这是要设置的属性名称,这里是href,通常用于定义超链接的目标URL。 -
data:text/plain;charset=utf-8, '+ encodeURIComponent(texts):这是要设置的属性值。这里使用了data:协议来创建一个数据URL,该URL表示一段纯文本数据。text/plain表示数据类型是纯文本,charset=utf-8表示字符集是UTF-8。encodeURIComponent(texts)是对变量texts进行URL编码,以确保其可以安全地作为URL的一部分。
这段代码的作是动态创建一个包含texts变量内容的纯文本数据URL(使用data://表示构造数据),并将其赋给动态创建的a标签的href属性。
| 数据类型 | 格式 |
|---|---|
| 图片 | image/jpeg |
| mp3 | video/mpeg |
| application/pdf | |
| 纯文本(txt) | text/plain |
更多类型参考http文件下载 response响应ContentType与a标签download属性
Javascript模拟<a>标签
<html>
<head><script src = "https://cdnjs.cloudflare.com/ajax/libs/axios/1.3.1/axios.min.js"> </script>
</head>
<body><button type = "button" onclick = "startDownload()"> Download </button>
</body><script>async function startDownload() {// get data using axioslet results = await axios({url: 'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTZ4gbghQxKQ00p3xIvyMBXBgGmChzLSh1VQId1oyhYrgir1bkn812dc1LwOgnajgWd-Yo&usqp=CAU',method: 'GET',responseType: 'blob'})let hidden_a = document.createElement('a');hidden_a.href = window.URL.createObjectURL(new Blob([results.data]));hidden_a.setAttribute('download', 'download_image.jpg');document.body.appendChild(hidden_a);hidden_a.click();}</script>
</html>使用axios从URL中获取数据,将其转换为Blob对象,并将其设置为href属性的值,JavaScript中点击了
<a>元素来触发文件下载。
下载总结
上述的4中方法其实都有一个共同之处就是均基于href和download属性实现的。
处理任何文件需要经历如下步骤:

首先href属性必须是文件的Blob URL,另外需要获取文件的类型,从而决定了浏览器是直接打开还是下载。
-
对于
<a>标签和windows.open()来说指向的是文件的地址,从该地址获取文件的类型,策略同时获取文件的Blob数据流包装为Blob URL,这些操作被浏览器隐藏了,用户无法感知,可以通过devtools查看,在preview就是返回的流数据,只是可以被浏览器打开的数据会被解析预览,如果是excel等文件,就是一堆乱码了,应为excel不再默认解析范围内。 -
对于通过Js实现的原理也是获取文件的字节流数据包装为Blob URL赋值给href属性,通过js行为实现下载。获取字节流Blob URL的方式有多种:(1)前端js编码用户输入数据,再构造Blob URL(这两步骤可以合并使用
data://协议直接将数据构造为Blob URL);(2)使用xhr或者fetch获取接口的字节流数据,再将流数据构造为Blob URL。最后将URL赋值给href属性设置download行为通过js调用该行为即可实现下载。
由此可知不论什么数据在浏览器实现下载都是需要得到文件的字节流数据的,将文件的字节流数据构造为Blob URL类型并赋值给<a>标签的href属性,按需控制download属性就可以时间文件的下载。
对于直接赋值文件地址的这种下载,浏览器隐藏了构造Blob URL的步骤和细节,是一种较为方便和实用的下载方式,但是需要文件服务器。
构造Blob URL的两种方式:
data://协议基于用户输入数据构建; JS构建数据来源任意。需要注意的是使用https协议获取的数据流需要在https响应头设置文件格式,用于解析数据。