EelasticSearch是什么?及EelasticSearch的安装
一、概述
Elasticsearch 是一个基于 Apache Lucene 构建的开源分布式搜索引擎和分析引擎。它专为云计算环境设计,提供了一个分布式的、高可用的实时分析和搜索平台。Elasticsearch 可以处理大量数据,并且具备横向扩展能力,能够通过增加更多的硬件资源来应对数据和查询量的增长。
Elasticsearch 的核心特点包括:
-
全文搜索:支持对各种类型的数据(包括结构化、半结构化和非结构化文本数据)进行快速高效的全文本搜索。
-
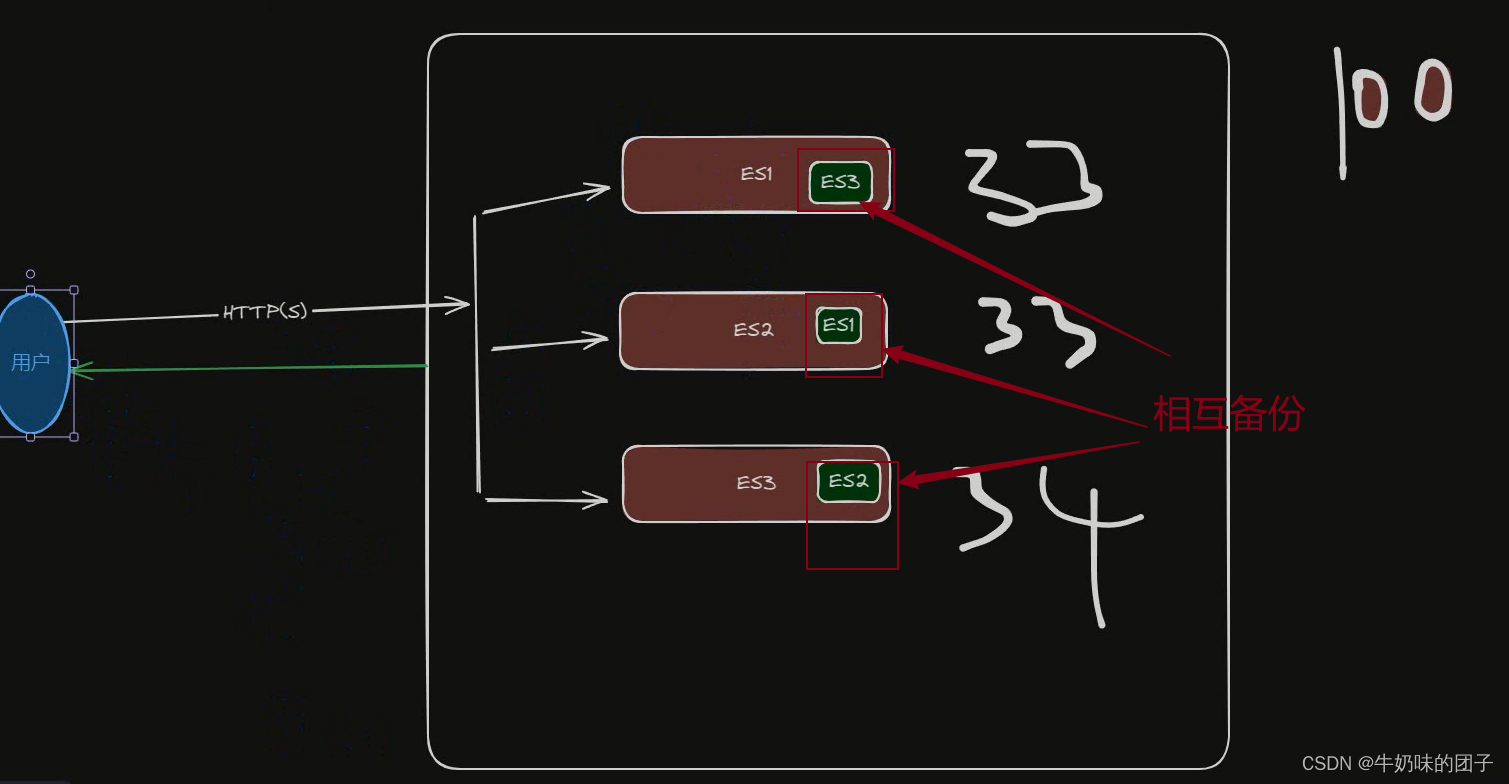
分布式:数据在集群中的多个节点间分布和复制,确保高可用性和容错性,同时也支持水平扩展,以应对更大的数据量和更高的并发访问。
-
实时性:数据一旦写入 Elasticsearch,几乎可以立即被搜索到,提供近乎实时的搜索体验。
-
分析能力:内置丰富的数据分析工具,包括聚合分析(Aggregations)和其他统计功能,便于用户对数据进行深入挖掘和洞察。
-
多租户:支持索引级别的隔离,每个索引可以配置分片数量和副本数量,以满足不同业务场景的需求。
-
RESTful API:通过 HTTP/HTTPS 协议提供 JSON 格式的 REST API 接口,易于与其他系统集成,支持多种开发语言调用。
-
灵活的文档模型:无需预定义严格的表结构,而是采用动态 schema 或映射,可以根据文档内容自动识别数据类型和结构。
Elasticsearch 被广泛应用在日志分析、监测数据、企业搜索、电子商务搜索、实时分析等多个领域,并常与 Logstash(日志收集和处理工具)、Kibana(数据可视化平台)共同构成 Elastic Stack(原 ELK Stack),形成一套完整的日志管理和数据分析解决方案。
二、什么场景会用到Elasticsearch
-
全文搜索:
-
电商搜索:快速查找商品信息,支持模糊匹配、关键词高亮显示、过滤、排序等功能。
-
站内搜索:网站内部的页面、文章、博客等内容的搜索,提供类似Google的搜索体验。
-
文档管理系统:企业级文档搜索,如办公文档、合同、法律文件等的高效检索。
-
论坛和社交媒体:用户发表的内容搜索,如帖子、评论、话题等。
-
日志分析与监控:
-
服务器日志:收集、索引和分析服务器产生的各类日志,用于故障排查、性能优化、安全审计等。
-
应用日志:跟踪应用程序的行为,帮助开发人员迅速定位错误、诊断问题。
-
运维监控:收集系统指标、网络流量数据,实时或历史数据分析,可视化展示系统状态和趋势。
-
数据分析:
-
业务分析:实时或批量分析业务数据,生成报表,进行趋势分析、关联分析等。
-
时序数据分析:存储和分析时间序列数据,例如设备传感器数据、用户行为数据等。
-
NoSQL JSON文档数据库:
-
作为JSON文档数据库使用,存储和检索半结构化数据,支持地理位置查询和混合查询。
-
搜索推荐:
-
实现个性化搜索和推荐功能,根据用户的搜索历史和行为模式,智能推荐相关内容。
-
地理信息系统:
-
存储和查询带有地理位置信息的数据,构建地图应用、位置服务等相关功能。
-
大规模监控系统:
-
结合Logstash和Kibana,搭建ELK Stack,进行大规模分布式环境下的日志集中管理、实时分析和可视化展示。
总之,Elasticsearch 适合那些需要对大量数据进行快速检索、实时分析和可视化展现的应用场景,特别是在处理非结构化或半结构化数据方面表现尤为出色。随着功能的不断丰富和完善,Elasticsearch 已经成为现代数据驱动型企业不可或缺的基础架构组件之一。
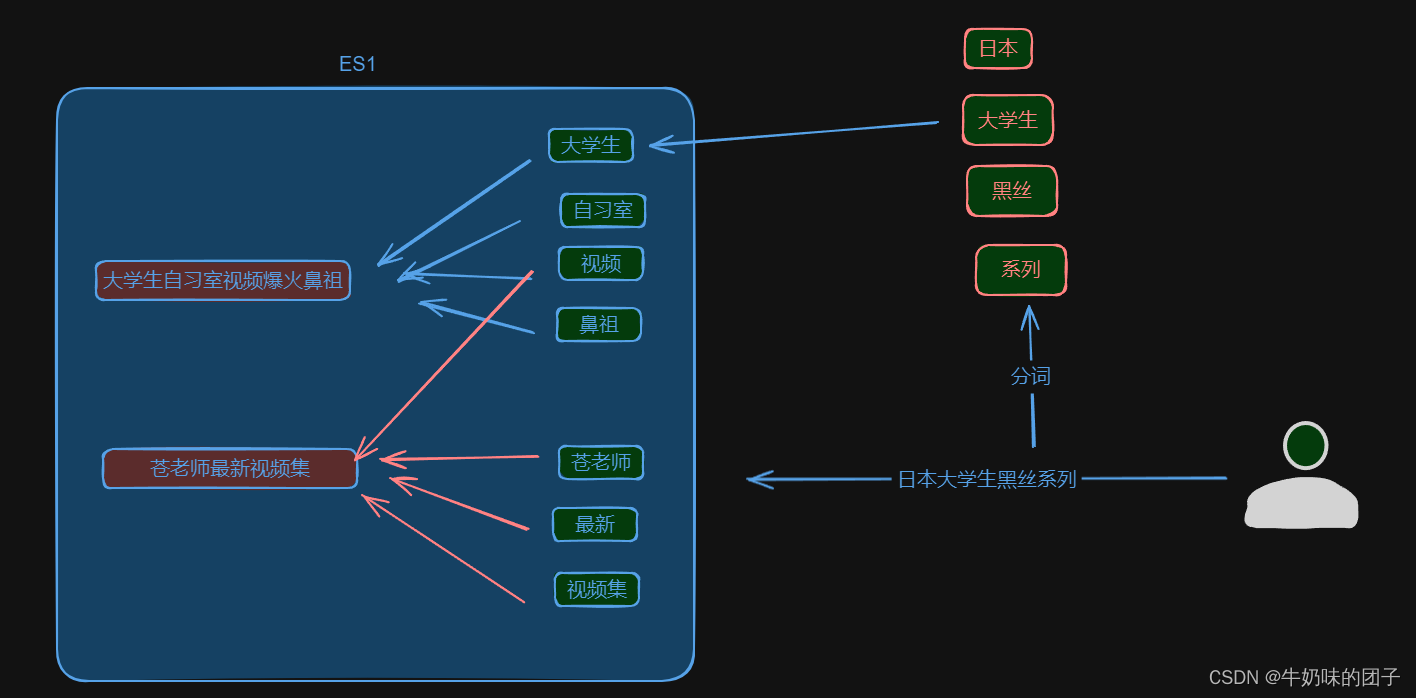
es分布式特点 :
三、Elasticsearch的安装
1.Docker安装
-e:参数是用来设置环境变量的。这个参数允许你在启动容器时定义或覆盖容器内部的环境变量。由于ES安装启动时默认占用全部内存,使用-e用来限制Elasticsearch容器内Java进程的初始堆大小(-Xms)和最大堆大小(-Xmx)。这意味着Elasticsearch启动时,其Java虚拟机将使用256MB作为最小和最大内存。
docker run -d --name es7 -e ES_JAVA_POTS="-Xms256m -Xmx256m" -e "discovery.type=single-node" -v /opt/es7/data/:/usr/share/elasticsearch/data -p 9200:9200 -p 9300:9300 elasticsearch:7.14.0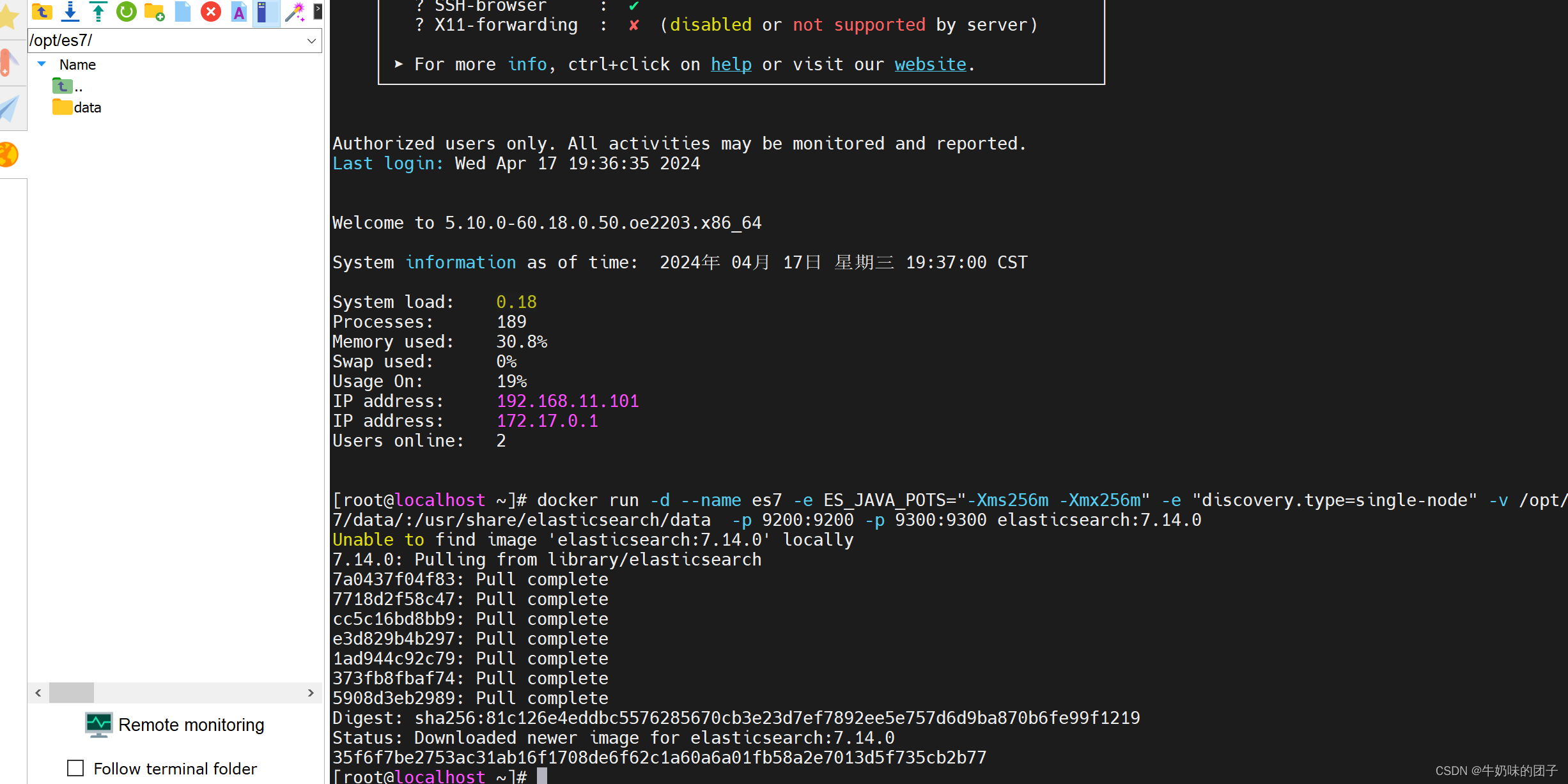
查看容器

查看容器日志
 如果出现权限不足的错误,修改权限重新运行容器
如果出现权限不足的错误,修改权限重新运行容器
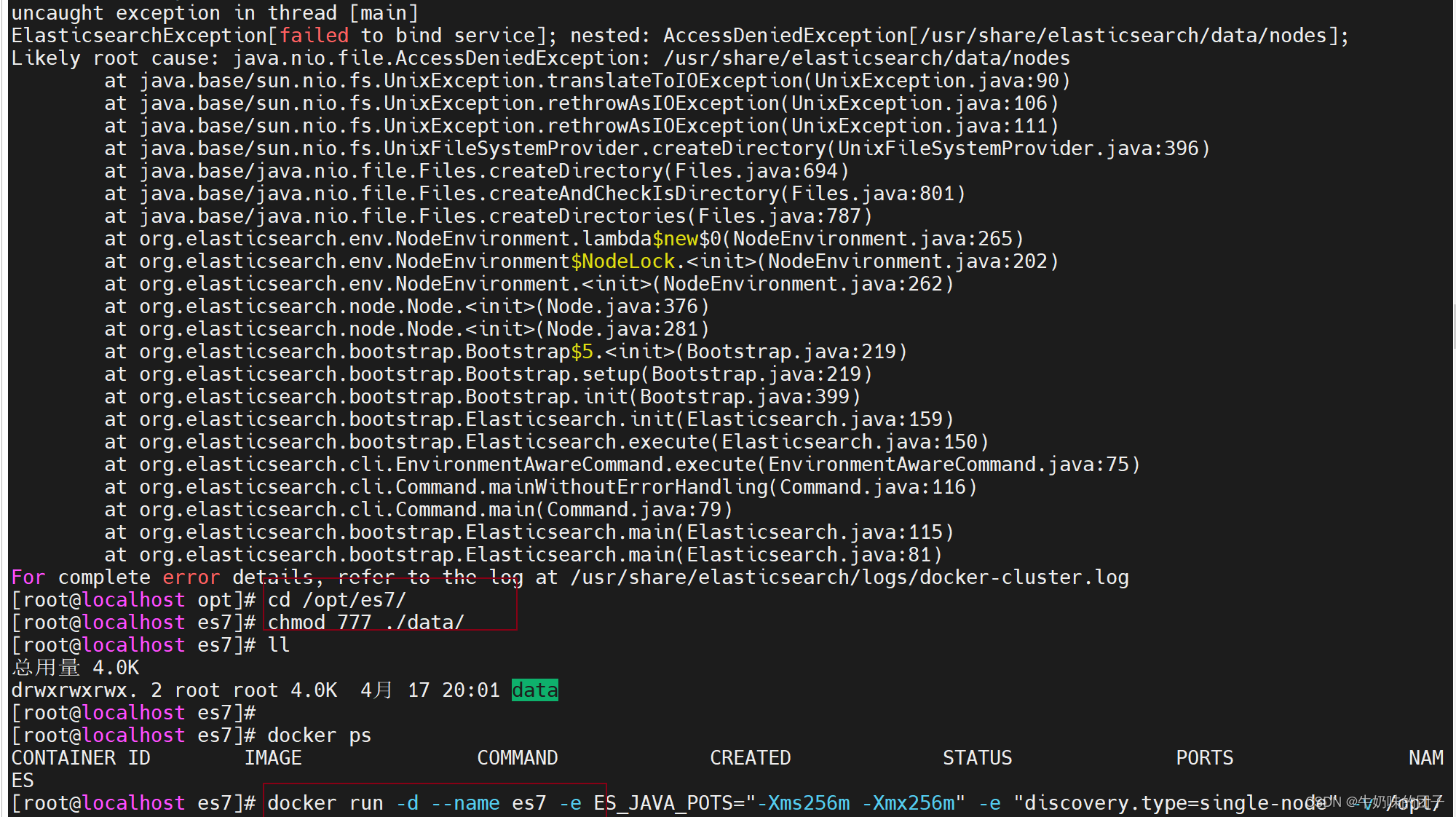
再次查看容器日志,显示正常,安装成功
2.客户端UI工具,Edge浏览器扩展
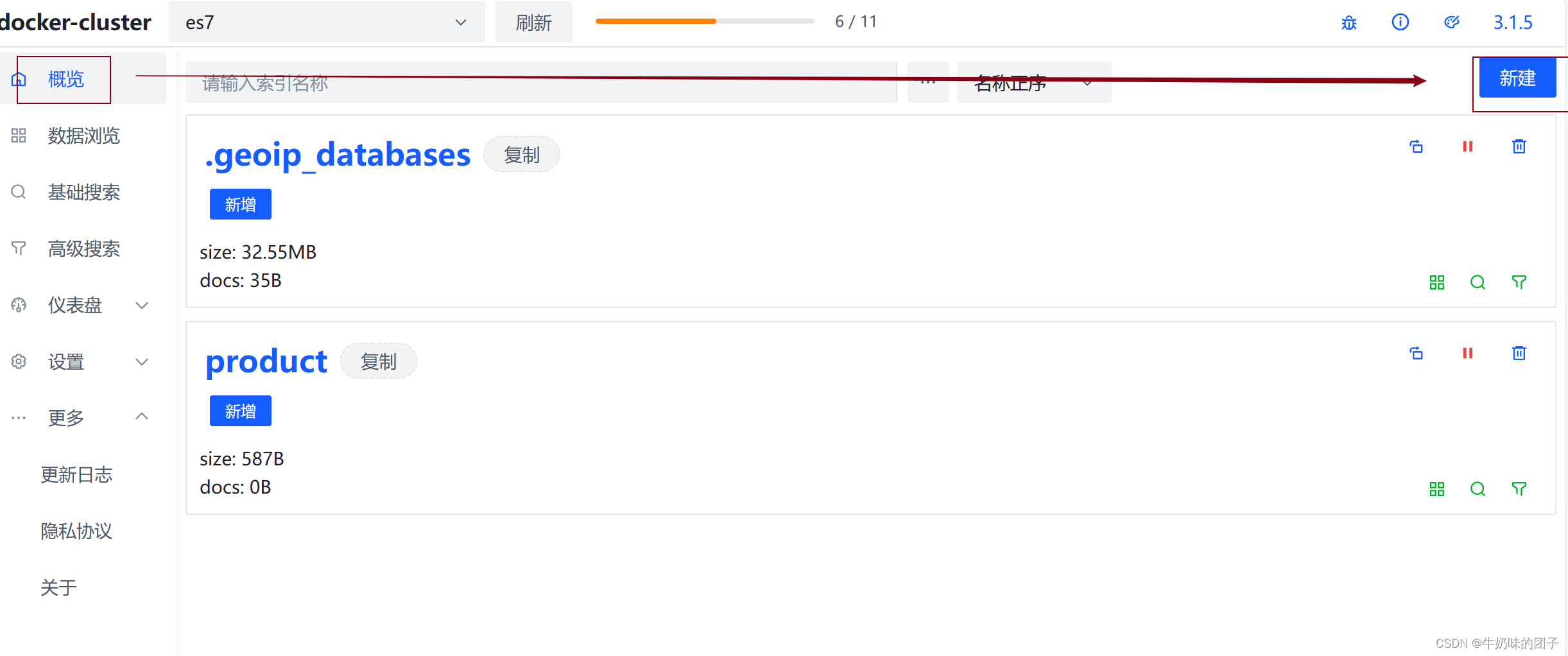
 新增数据索引(类似于数据库中的表)
新增数据索引(类似于数据库中的表)

ES的分词器不支持中文需要我们另外安装分词器
四、分词器安装
参考网址:https://blog.51cto.com/u_15116285/6100979
官方插件下载地址:(下载和使用要用同一版本,多版本可能不兼容)
https://github.com/medcl/elasticsearch-analysis-ik/releases
#第一步 copy 插件到容器
docker cp /opt/es7/elasticsearch-analysis-ik-7.14.0.zip 容器id:/usr/share/elasticsearch#第二步进入你的容器
docker exec -it 容器id /bin/bash#第三步执行如下命令,安装插件,中间会提示 Y or N,直接写 Y ,回车即可
elasticsearch-plugin install file:\/usr/share/elasticsearch/elasticsearch-analysis-ik-7.14.0.zip#第四步退出容器
exit#第五步重启容器
docker restart 容器ID
测试:
post _analyze
{"analyzer": "ik_smart","text": "大学生自习室视频爆火鼻祖"
} 
post _analyze
{"analyzer": "ik_max_word","text": "大学生自习室视频爆火鼻祖"
} 
分词器原理: