【多模态检索】Coarse-to-Fine Visual Representation
快手文本视频多模态检索论文
论文:Towards Efficient and Effective Text-to-Video Retrieval with Coarse-to-Fine Visual Representation Learning
链接:https://arxiv.org/abs/2401.00701
摘要
近些年,基于CLIP的text-to-video检索方法广为流行,但大多从视觉文本对齐方法上演进。按照原文:design a heavy fusion block for sentence (words)-video (frames) interaction,而忽视了复杂度和检索效率。
- 升级点
- 本文采用多粒度视觉特征学习,捕获从抽象到具体的视觉内容。Multi-granularity visual feature learning, ensuring the model’s comprehensiveness in capturing visual content features spanning from abstract to detailed levels during the training phase.
- 设计两阶段检索框架,优点在于 balances the coarse and fine granularity of retrieval content.
- 在训练阶段,设计一个parameter-free text-gated interaction block (TIB) 模块用于细粒度视觉表征学习并嵌入一个额外的 Pearson Constraint来优化跨模态表示学习。
- 在检索阶段,使用粗粒度视觉表征快速检索topk结果,然后使用细粒度视觉表示rerank(recall-then-rerank pipeline)。
- 效果:nearly 50 times faster
- 难点:对比原始图像文本匹配任务(包含较少的视觉信息),聚合整个视频表示易导致过度抽象以及误导。在视觉文本检索任务中,一个句子通常只描述一个感兴趣的视频子区域。现有工作很多不够合理与成熟,衍生出很多CLIP的变体,大体分为两个方向。例如CLIP4Clip,仅仅是将预训练的CLIP简单进行MeanPooling就从image-text迁移到video-text领域。
- 设计a heavy fusion block来加强视觉和文本的交互以达到模态间更好地对齐的目的;
- 优化text-driven video representations,keep multi-grained features including video-level and frame-level for brute-force search。
- 近些年方法虽然有效果提升,但却需要巨大的计算成本(text-video similarity calculation)。
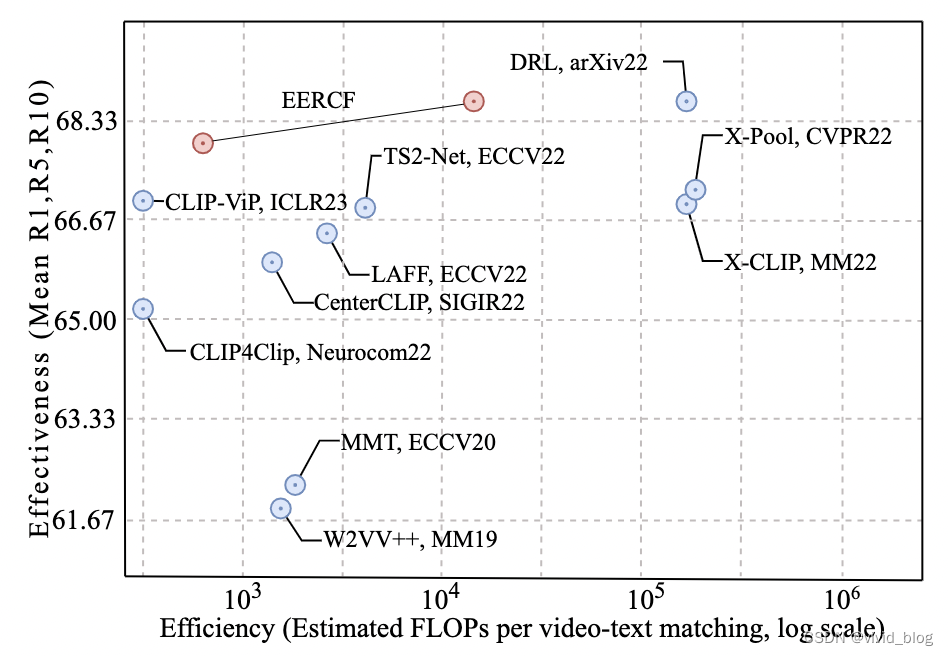
过于细粒度的计算可能会放大视频局部噪声,降低检索效率。需要在有效性和效率上做trade-off。
方法
-
整体架构
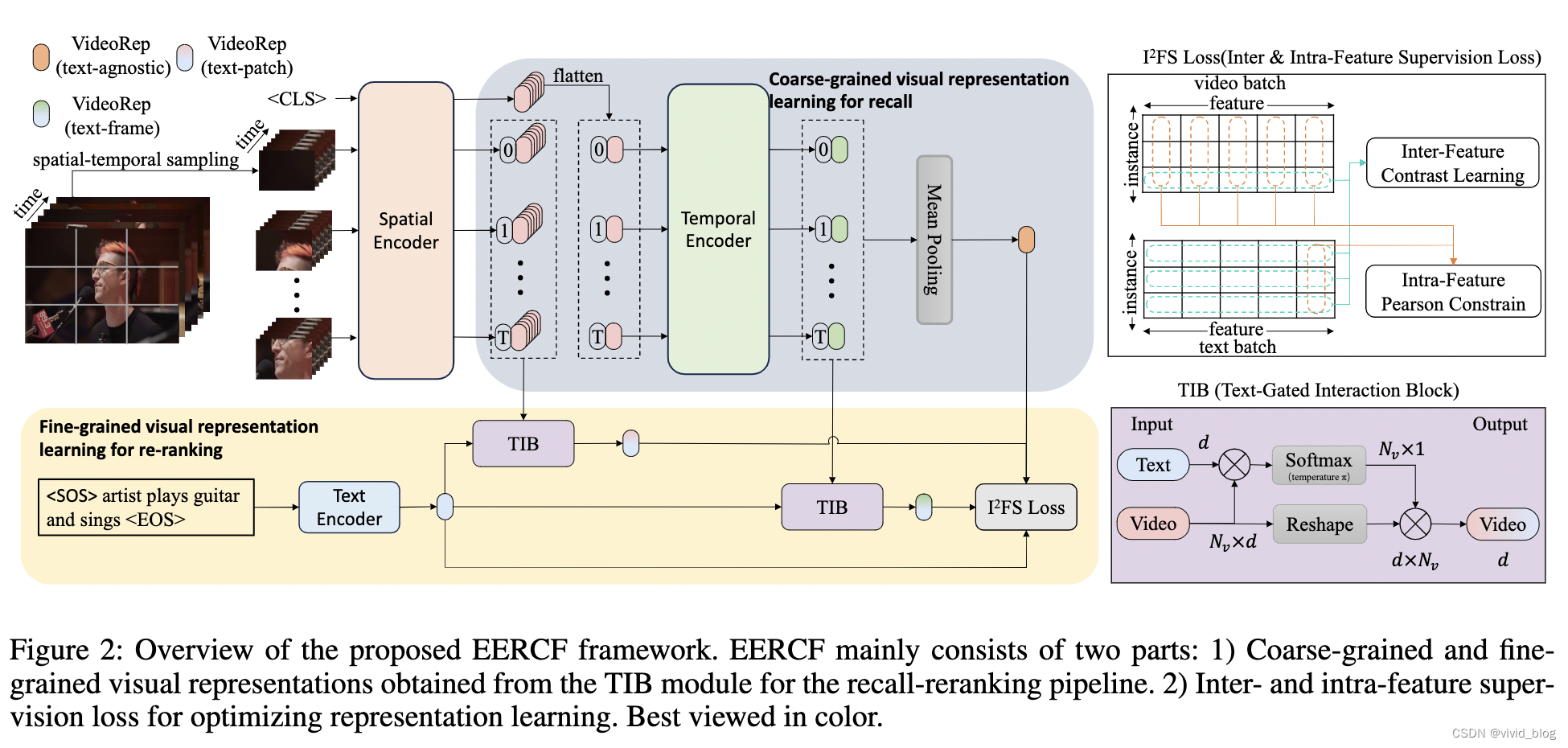
-
特征输入:a video v consists ofT sequential frames {f1, f2, …, fT |fi ∈ RH ×W ×C};each frame is divided into N patches {f 1i , f 2i , …, f N i |f n i ∈RP×P×C} with P × P size;text t。
-
模型结构
-
视觉端
- a spatial encoder (SE) with 12 transformer layers initialized by the public CLIP checkpoints
- a temporal encoder (TE) with 4 transformer layers to model temporal relationship among sequential frames, [CLS] enocde patch to frame(0th patch feature represent frame)
- a MeanPooling layer (MP) to aggregate all frame-level features into a text-agnostic feature vector
注:patch 和 frame都包含位置编码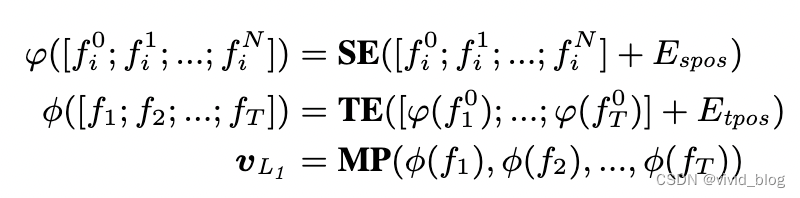
-
视觉文本交互 – Text-Gated Interaction Block
- 简单的attention机制,π is the temperature,决定多少视觉信息被保留(A small value of π only emphasizes those most relevant visual cues, while a large value pays attention to much more visual cues.)
- 未引入任何参数
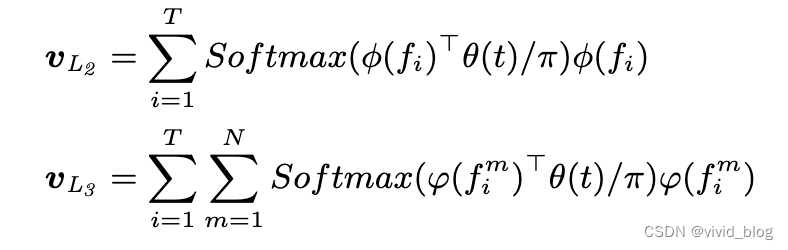
-
-
损失函数(Inter- and Intra-Feature Supervision Loss)
- 数据形式:Each batch of B video-text pairs,in each pair, the text tb is a corresponding description of the video vb
- Contrastive Loss for Inter-Feature Supervision - infoNCE loss,batch内其他为负样本
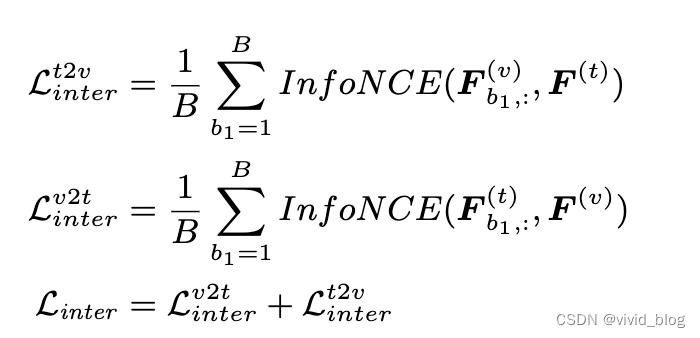
- Pearson Constraint for Intra-Feature Supervision
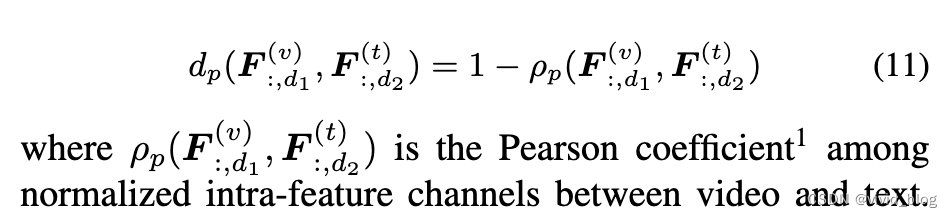

- Total Loss

-
检索中的两阶段策略 - To balance the efficiency and effectiveness
- 使用VL1作为tok召回阶段特征
- rerank这些召回结果用VL2和VL3
- 两阶段的优点:效率提升 & 过于细粒度的特征可能会导致对局部噪声的过度关注。
实验
主实验:
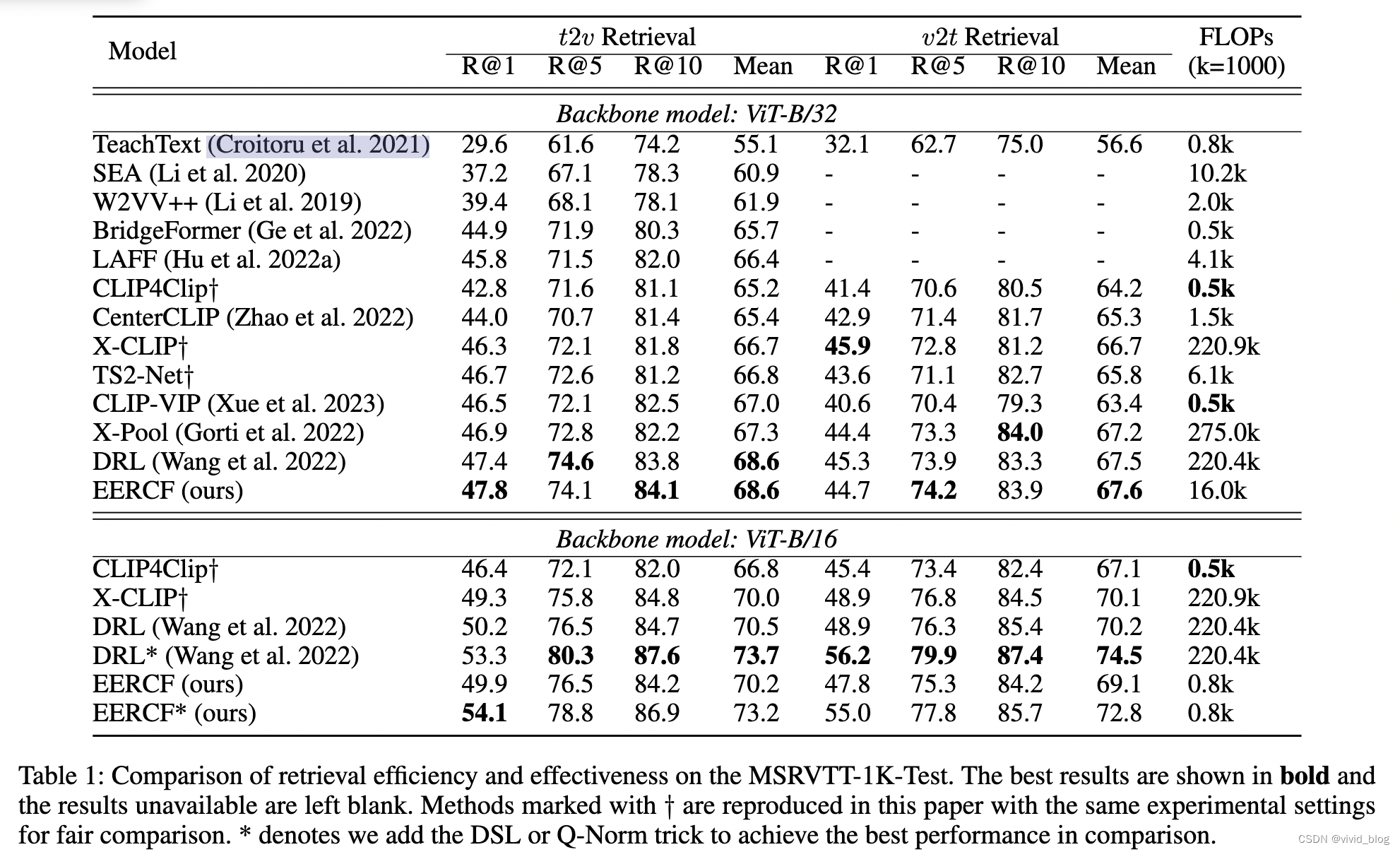
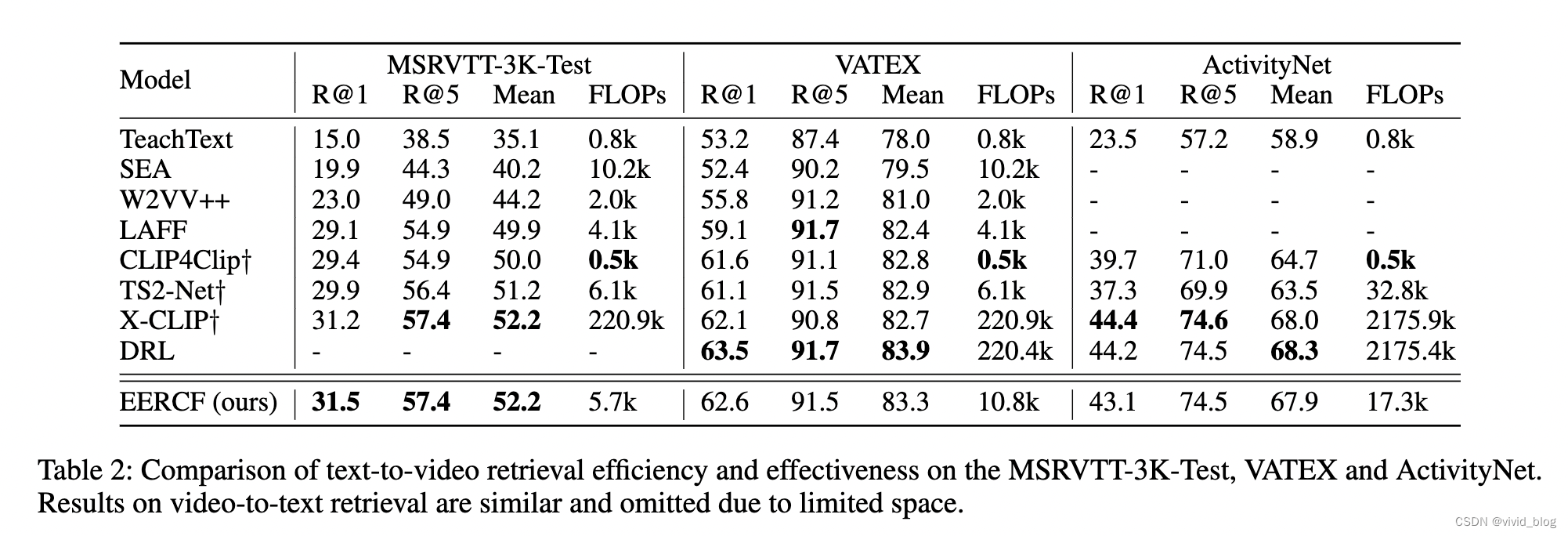
其他数据集:
消融实验:
可以看到去掉帧粒度的文本交互特征指标下降明显。当去掉所有文本交互特征时,只使用视觉特征会引入很多噪声(引入喝多与文本无关的特征),mislead the matching process。
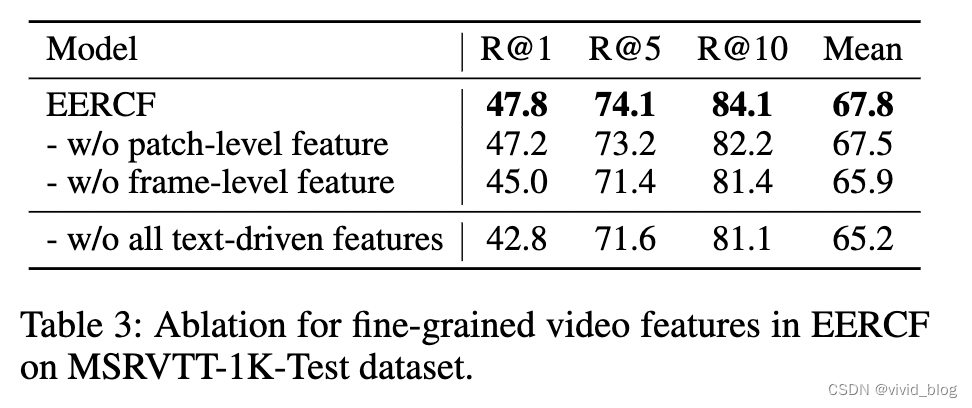
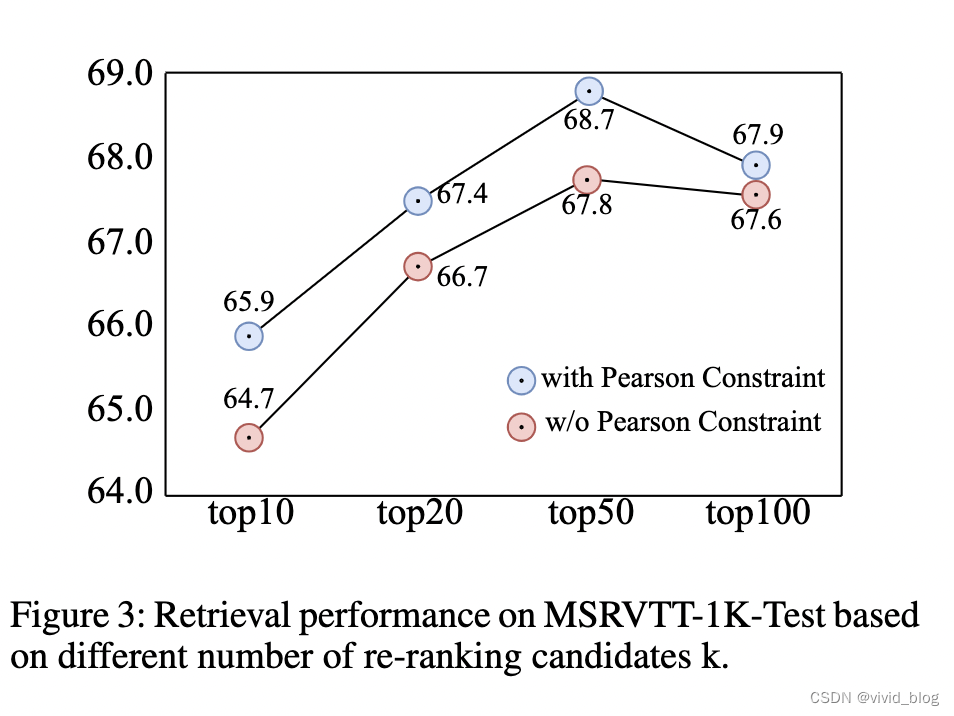
top100的下降可能是由于重新排序阶段过度关注视觉局部细节,增加 top-k 引入的噪声会对重新排序阶段造成更多的干扰
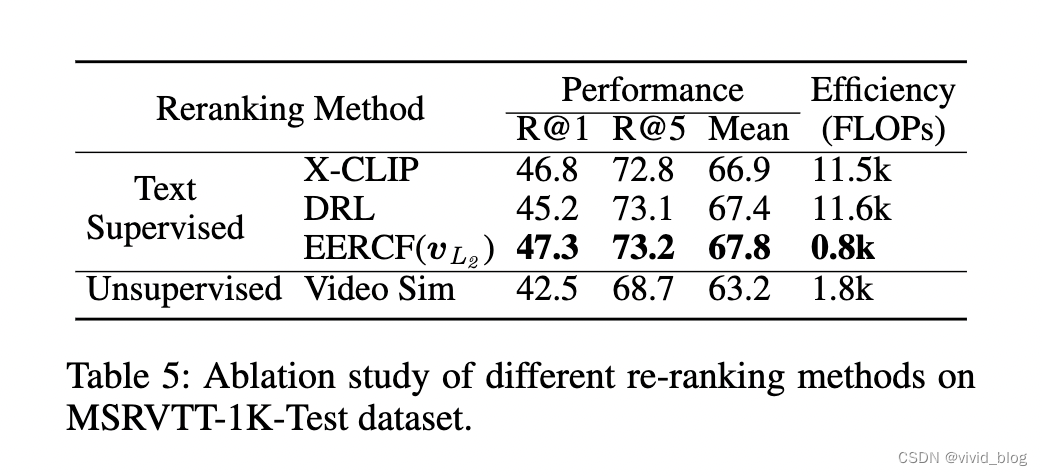
Re-ranking 消融
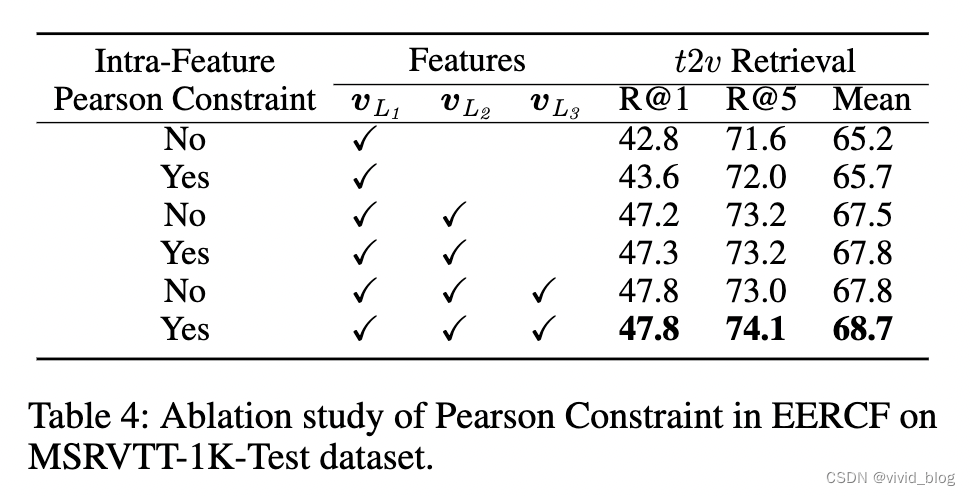
Intra-Feature Pearson Constraint消融
Visualization of Coarse-to-Fine Retrieval
