Spark/Hive
Spark/Hive
- Hive 原理
- Spark with Hive
- SparkSession + Hive Metastore
- spark-sql CLI + Hive Metastore
- Beeline + Spark Thrift Server
- Hive on Spark
- Hive 擅长元数据管理
- Spark 擅长高效的分布式计算
Spark + Hive 集成 :
- Hive on Spark : Hive 用 Spark 作为底层的计算引擎时
- Spark with Hive : Spark 把 Hive 当元信息的管理工具
Hive 原理
Hive架构 , 可插拔的第 三方独立组件 :
- User Interface 提供 SQL 接入服务
- CLI 与 Web Interface 在本地接收 SQL 查询语句
- Hive Server 2 提供 JDBC/ODBC 客户端连接,从远程提交 SQL 查询请求
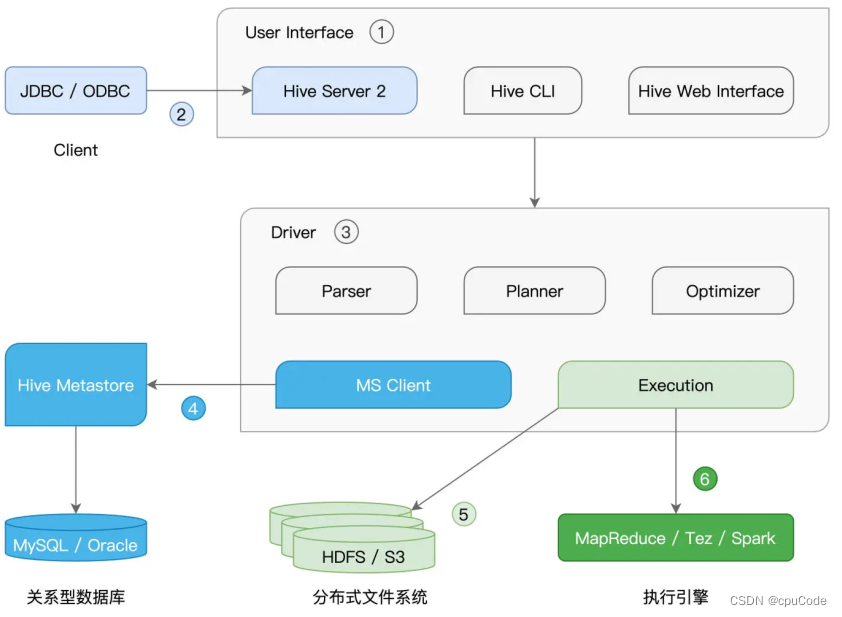
SQL 查询的工作过程 :
- 收到 SQL 后,Driver 先用 Parser ,将查询语句转化为 AST(Abstract Syntax Tree,查询语法树)
- Hive 从 Hive Metastore 拿表的元信息,如 : 表名、列名、字段类型、数据文件存储路径、文件格式
- Planner 根据 AST 生成执行计划
- Optimizer 优化执行计划
- Execution 提交执行计划
Spark with Hive
Spark with Hive 集成方式 :
- 创建 SparkSession,访问 Hive Metastore
- 通过 spark-sql CLI,访问本地 Hive Metastore
- 通过 Beeline,访问 Spark Thrift Server
SparkSession + Hive Metastore
启动 Hive Metastore
hive --service metastore
Spark 拿 Metastore 访问地址的两种办法 :
- 创建 SparkSession 时,通过 config 指定
hive.metastore.uris - 把Hive的
hive-site.xml拷到 Spark 的 conf 下
spark-shell 下写代码 :
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrameval hiveHost: String = _// 创建SparkSession实例
val spark = SparkSession.builder().config("hive.metastore.uris", s"thrift://hiveHost:9083").enableHiveSupport().getOrCreate()// 读取Hive表,创建DataFrame
val df: DataFrame = spark.sql(“select * from salaries”)
df.show/** 结果打印
+---+------+
| id|salary|
+---+------+
| 1| 26000|
| 2| 30000|
| 4| 25000|
| 3| 20000|
+---+------+
*/
SparkSession + Hive Metastore 集成方式 :
- Spark 只涉及 Hive 的 Metastore
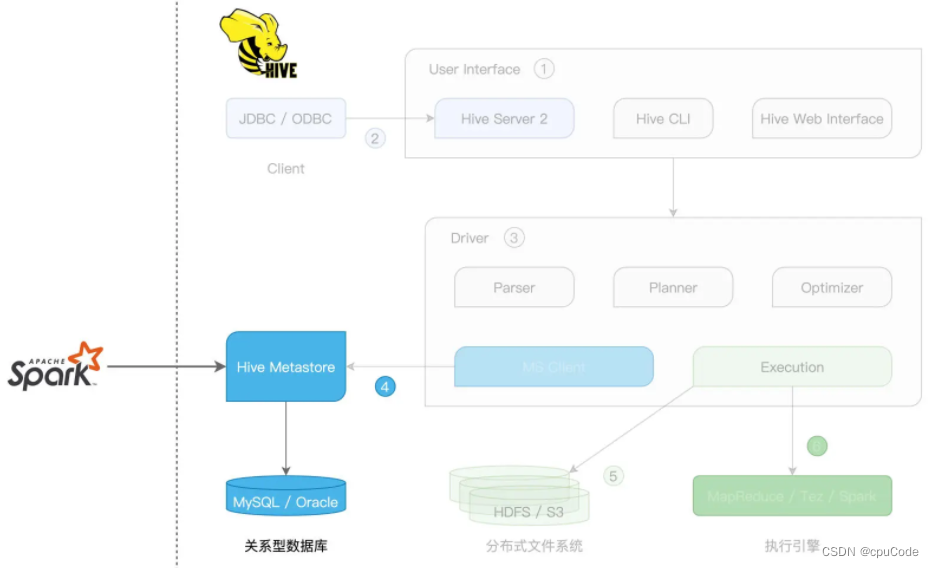
spark-sql CLI + Hive Metastore
spark-sql CLI 与 Hive Metastore 要在同个节点
- spark-sql CLI 只能访问 本地 Hive Metastore
Beeline + Spark Thrift Server
用 Beeline 客户端,连接 Spark Thrift Server,从而完成 Hive 表的访问与处理
Hive Server 2 (Hive Thrift Server 2) 采用 Thrift RPC 协议框架
Beeline + Spark Thrift Server 集成 :
- Spark Thrift Server 与 Hive Server 2 的实现逻辑一样。最大区别:SQL 查询接入后的解析、规划、优化与执行
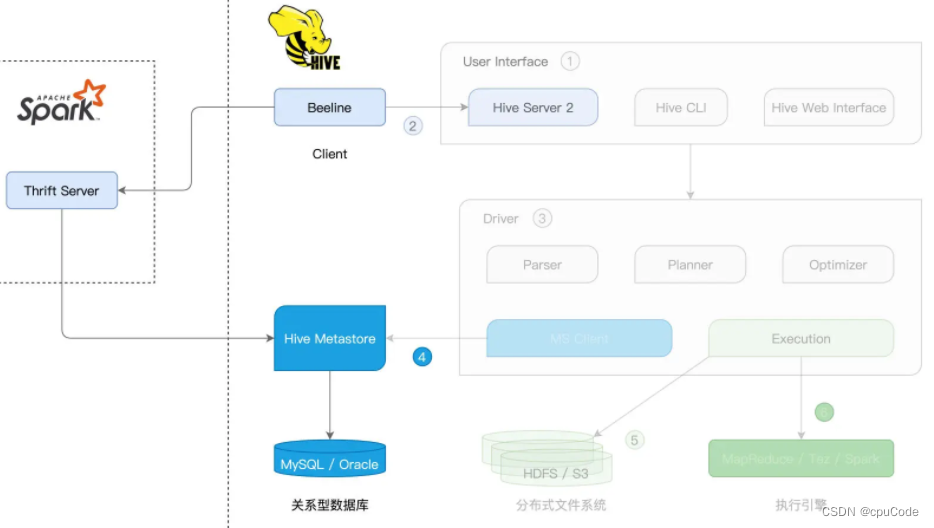
启动 Spark Thrift Server :
$SPARK_HOME/sbin/start-thriftserver.sh
Spark Thrift Server 启动后,在任意节点上通过 Beeline 就能访问该服务
beeline -u "jdbc:hive2://hostname:10000"
Hive on Spark
Hive on Spark :Hive 用 Spark 作为分布式执行引擎
- SQL 语句的解析、规划与优化都由 Hive 的 Driver 完成
- Hive on Spark 衔接的部分是 Spark Core
指定 Spark 执行引擎
set hive.execution.engine=spark