Spark 配置项
Spark 配置项
- 硬件资源类
- CPU
- 内存
- 堆外内
- User Memory/Spark 可用内存
- Execution/Storage Memory
- 磁盘
- Shuffle
- Spark SQL
- Join 策略调整
- 自动分区合并
- 自动倾斜处理
配置项分为 3 类:
- 硬件资源类 : 与 CPU、内存、磁盘有关的配置项
- Shuffle 类 : Shuffle 计算过程的配置项
- Spark SQL : Spark SQL 优化配置项
读取配置项顺序 :SparkConf 对象 -> 命令行参数 -> 配置文件
硬件资源类
| 资源类别 | 配置项 | 含义 |
|---|---|---|
| CPU | spark.cores.max | 集群满 CPU 核 |
spark.executor.cores | 每个 Executors 可用的 CPU Cores | |
spark.default.parallelism | 默认并行度 | |
spark.sql.shuffle.partitions | Reduce 的默认并行度 | |
spark.task.cpus | 每个任务可用的 CPU 核 | |
spark.executor.instances | 集群内 Executors 的个数 | |
| 内存 | spark.executor.memory | 单个 Executor 的堆内内存总大小 |
| spark.memory.offHeap.enabled | 是否启动堆外内存 | |
| spark.memory.offHeap.size | 单个 Executorp 的堆外内存总大小 | |
| spark.memory.fraction | 除 User Memory 外的内存空间占比 | |
| spark.memory.storageFraction | 缓存RDD的内存占比,执行内存占比= 1 - spark.memory.storageFraction | |
| spark.rdd.compress | RDD缓存是否压缩,默认不压缩 | |
| 磁盘 | spark.local.dir | 存储 Shuffle 中间文件/RDD Cache 的磁盘目录 |
CPU
配置项:
spark.cores.max | 集群满 CPU 核 |
|---|---|
spark.executor.cores | 每个 Executors 可用的 CPU 核 |
spark.task.cpus | 每个任务可用的 CPU 核 |
spark.executor.instances | 集群内 Executors 的个数 |
并行度 : 定义分布式数据集划分的份数/粒度,决定了分布式任务的计算负载。并行度越高,数据的粒度越细,数据分片越多,数据越分散
并行度的配置项 :
spark.default.parallelism | 默认并行度 |
|---|---|
spark.sql.shuffle.partitions | Reduce 的默认并行度 |
并行计算任务:在任一时刻整个集群能够同时计算的任务数量
- 整个集群的并行计算任务数 =
spark.executor.instances*spark.executor.cores
达到 CPU、内存、数据之间的平衡的约定 :
spark.executor.cores指定 CPU Cores ,记为 cExecution Memory内存大小 ,记为 m- 分布式数据集的大小记为 D ,并行度记为 P,D/P = 每个数据分片大小
- 一个数据分片对应着一个 Task(分布式任务),而一个 Task 又对应着一个 CPU Core
公式量化 :
# D/P = 数据分片大小,m/c = 每个 Task 分到的可用内存
D/P ~ m/c
内存
内存配置项 :
| spark.executor.memory | 单个 Executor 的堆内内存总大小 |
|---|---|
| spark.memory.offHeap.size | 单个 Executorp 的堆外内存总大小 |
(spark.memory.offHeap.enabled=true) | |
| spark.memory.fraction | 堆内内存中,用于缓存RDD和执行计算的内存比例 |
| spark.memory.storageFraction | 缓存RDD的内存占比,执行内存占比= 1 - spark.memory.storageFraction |
| spark.rdd.compress | RDD缓存是否压缩,默认不压缩 |

- Reserved Memory 大小固定为 300MB
- M 指定了 Executor 进程的 JVM Heap 大小 ( Executor Memory )
- Execution Memory 的组成: Execution Memory、Storage Memory 、UserMemory
- User Memory : 存储用户自定义的数据结构,如 : RDD 的各类实例化对象或集合类型(如: 数组、列表等)
- Spark 1.6 后,推出了动态内存管理模式,Execution Memory/Storage Memory 能互相抢占
堆外内
堆外存储:
- int 的用户 ID、String 的姓名、int的年龄、Char 的性别
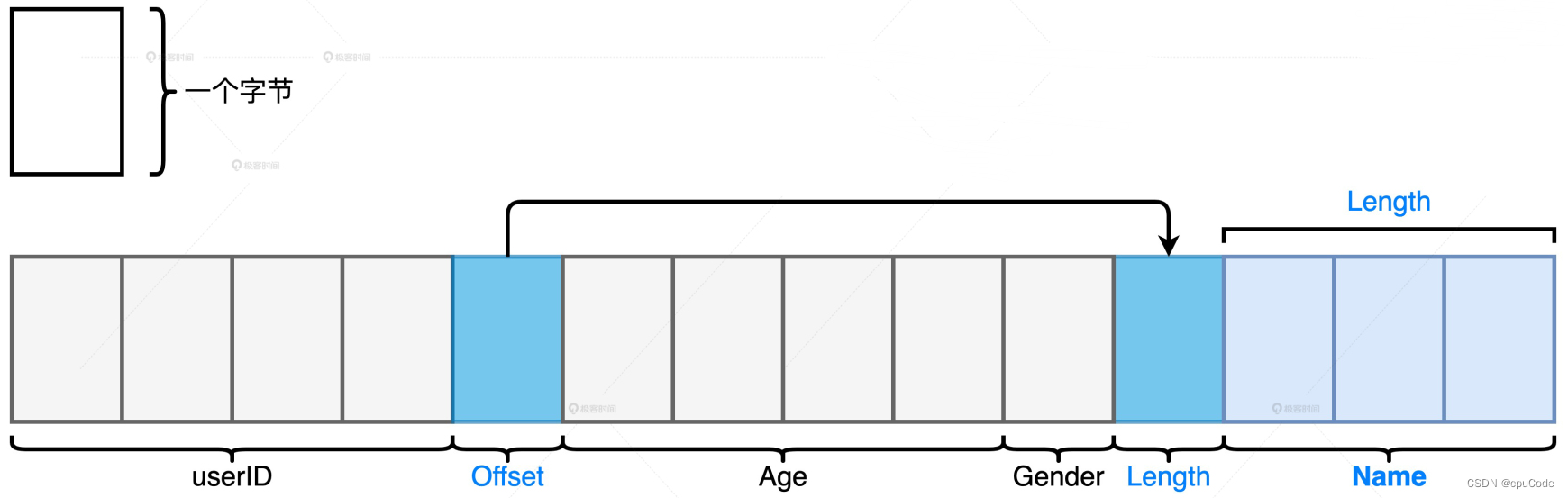
处理数据集:
- 数据模式比较扁平,而且字段多是定长数据类型,就更多使用堆外内存
- 数据模式很复杂,嵌套结构/变长字段很多,就更多使用 JVM 堆内内存
User Memory/Spark 可用内存
User Memory :存储开发者自定义的数据结构,这些数据结构需要协助分布式数据集的处理
spark.memory.fraction : 明确 Spark 可支配内存占比,即 :User Memory 堆内占比 = 1 - spark.memory.fraction
spark.memory.fraction:系数越大,Spark 可支配的内存越多,User Memory 占比越小spark.memory.fraction默认值是 0.6,JVM 堆内的 60% 给 Spark支配,40% 给 User Memory
调整内存相对占比:
- 自定义数据结构多,
spark.memory.fraction调低,用于分布式计算和缓存分布式数据集 - 自定义数据结构少,
spark.memory.fraction调高,用于分布式计算和缓存分布式数据集
Execution/Storage Memory
sf 的设置情况:
- ETL :RDD Cache 使用少。就能将 sf 设低点,让 Execution Memory 大点
- 缓存密集型 :机器学习:RDD Cache 使用较多,就能把 sf 设高点,让 Storage Memory 大点
- 过多的缓存会引发 GC(Garbage Collection,垃圾回收)
JVM 把 Heap 堆内内存分为:
- 年轻代:存储生命周期较短、引用次数较低的对象,会引发 Young GC
- 老年代:存储生命周期较长、引用次数高的对象,会引发 Full GC
- RDDcache 会存在老年代
Full GC时,会引发 STW:
- 抢占应用程序执行线程,把所有 CPU 线程都做垃圾回收,应用程序的暂时不执行(Stop the world)
- 等 Full GC 完事后,才把 CPU 线程释放,应用程序才能继续执行
- Full GC 弊端远大于 Young GC
为了 RDD cache 访问效率,用 RDD/DataFrame/Dataset.cache ,以对象值形式缓存到内存 (避免序列化消耗)
- 用对象值形式缓存数据,每条数据都要构成一个对象 (自定义Case class, Row 对象)
- 当大量的 RDD cache 时,会引发 Full GC
- 当应用是缓存密集型,需要大量缓存,为了执行效率,可以改用序列化
spark.rdd.compress :RDD 缓存默认不压缩
- 启用压缩后,能节省缓存内存的占用,把更多的内存空间留给分布式任务执行
- 启用压缩后,会引入额外的计算开销、牺牲 CPU
磁盘
磁盘的配置项:
- spark.local.dir :任意的本地文件系统目录,默认值是 /tmp 。 用于存储各种各样的临时数据,如: Shuffle 中间文件、RDD Cache。
有条件可以设置个大而性能好的文件系统,如:空间足够大的 SSD 文件系统目录
Shuffle
| spark.shuffle.file.buffer | Map 输出端的写缓冲区的大小 |
|---|---|
| spark.reducer.maxSizeInFlight | Reduce 输入端的读缓冲区的大小 |
| spark.shuffle.sort.bypassMergeThreshold | Map 阶段不进行排序的分区阈值 |
Shuffle 的计算的两个阶段:
- Map 阶段:执行映射逻辑,并按 Reducer 的分区规则,将中间数据写入到本地磁盘
- Reduce 阶段:从各个节点下载数据分片,并根据需要实现聚合计算
- Map 阶段的计算结果(中间文件),会存储到写缓冲区(Write Buffer),满后再写入到磁盘文件系统
- Reduce 阶段,通过网络从不同节点的磁盘中拉取中间文件,以数据块暂存到计算节点的读缓冲区(Read Buffer),满后再写入到磁盘文件系统
自 Spark 1.6 后,全用 Sort shuffle manager 管理 Shuffle
- Sort shuffle manager 会把 Map/Reduce 都引入排序
repartition、groupBy 就没有排序的需求,引入的排序就是额外的计算开销
- 不需要聚合/排序时,调整
spark.shuffle.sort.bypassMergeThreshold改变 Reduce 端的并行度(默认值 200)。当 Reduce 的分区数 < 该值时,Shuffle 就不会引入排序
Spark SQL
| 作用 | 配置项 | 含义 |
|---|---|---|
| AQE | spark.sql.adaptive.enabled | 是否启用 AQE |
| Join 策略 | spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin | 非空分区比例 < 该值,调整Join策略 |
| spark.sql.autoBroadcastJoinThreshold | 基表 < 该值, 触发Broadcast Join | |
| 自动分区合并 | spark.sql.adaptive.coalescePartitions.enabled | 是否启用合并分区 |
| spark.sql.adaptive.advisoryPartitionSizelnBytes | 合并后的目标分区大小 | |
| spark.sql.adaptive.coalescePartitions.minPartitionNum | 分区合并后,并行度 > 该值 | |
| 自动倾斜处理 | spark.sql.adaptive.skewJoin.enabled | 是否自动处理数据倾斜 |
| spark.sql.adaptive.skewJoin.skewedPartitionFactor | 倾斜分区的比例系数 | |
| spark.sql.adaptive.skewJoin.skewedPartitionThresholdlnBytes | 倾斜分区的最低阀值 | |
| spark.sql.adaptive.advisoryPartitionSizeInBytes | 拆分倾斜分区粒度 (字节) |
Spark 3.0 推出 AQE (Adaptive Query Execution, 自适应查询执行) 的 3 个动态优化特性: Join 策略调整、自动分区合并、自动倾斜处理
# 启用 AQE
spark.sql.adaptive.enabled true
Join 策略调整
Join 策略调整 : Spark SQL 在运行时动态调整为 Broadcast Join
- 每当 DAG 中的 Map 阶段执行完毕,会结合 Shuffle 中间文件的统计信息,重新计算 Reduce 数据表的存储大小。当基表 <
autoBroadcastJoinThreshold时,下个阶段就可能变为 Broadcast Join
动态 Join 策略的条件二 :大表过滤后,非空分区比例 < nonEmptyPartitionRatioForBroadcastJoin,才能成功触发 Broadcast Join 降级
- 例子 :大表有 100 个分区,过滤后只有 15 个分区有数据
- 非空分区比例 : 15 / 100 = 15% < 20% , 就触发 Broadcast Join 降级
配置项:
# AQE前,基表 < 该值,就会触发 Broadcast Join
spark.sql.autoBroadcastJoinThreshold 10m# AQE后,非空分区比例 < 该值,就调整动态 Join 策略
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin 0.5
Spark SQL 的广播阈值对比的两种情况:
- 基表来自文件系统,用基表在磁盘的存储大小与广播阈值对比
- 基表来自 DAG 的中间文件,用 DataFrame 执行计划中的统计值与广播阈值对比
DataFrame 执行计划中的统计值 :
val df: DataFrame = _
// 先对分布式数据集加Cache
df.cache.count// 获取执行计划
val plan = df.queryExecution.logical// 获取执行计划对于数据集大小的精确预估
val estimated: BigInt = spark.sessionState.executePlan(plan).optimizedPlan.stats.sizeInBytes
自动分区合并
自动分区合并 :解决 Reduce 过小的分区,而导致的数据的不均衡问题
分区合并示意图 :
- 依序扫描数据分区,当相邻分区的尺寸之和 > 实际大小时,就把扫描过的分区做一次合并
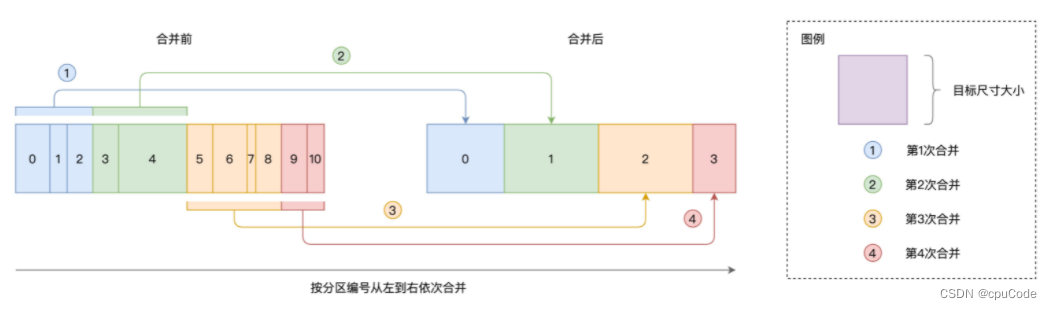
# 是否启用自动分区合并,默认启用
spark.sql.adaptive.coalescePartitions.enabled true# 合并后的目标分区大小
spark.sql.adaptive.advisoryPartitionSizelnBytes 256MB# 分区合并后,并行度 > 该值
spark.sql.adaptive.coalescePartitions.minPartitionNum 1
- 每个分区的平均大小 = 数据集大小/最低并行度
- 实际大小 = min(advisoryPartitionSizeInBytes , 分区的平均大小)
例子 :Shuffle 中间文件 = 20GB,minPartitionNum = 200,
- 每个分区的尺寸= 20GB / 200 =100MB
- 设 advisoryPartitionSizeInBytes = 200MB,最终分区 = min(100MB,200MB) = 100MB
自动倾斜处理
自动倾斜处理:把倾斜的数据分区拆分成小分区
- 对所有数据分区按大小做排序,取中位数。将
中位数 * skewedPartitionFactor,得到判定阈值。凡是 > 阈值的数据分区,就可能认为倾斜分区 - 当可能倾斜分区 >
skewedPartitionThresholdInBytes,就会判定为倾斜分区
配置项 :
# 开启自动倾斜处理
spark.sql.adaptive.skewJoin.enabled true# 判断大分区,倾斜分区的比例系数
spark.sql.adaptive.skewJoin.skewedPartitionFactor 5# 判断大分区,倾斜分区的最低阔值
spark.sql.adaptive.skewJoin.skewedPartitionThresholdinBytes 256MB# 拆分大分区 , 倾斜分区的拆分单位
spark.sql.adaptive.advisoryPartitionSizelnBytes 256MB
例子:数据表有 3 个分区:90MB、100MB 、512MB。中位数是 100MB
- 判定阈值 = 中位数 * skewedPartitionFactor = 100MB * 5 = 500MB
- 512MB 为候选分区
- 512MB > skewedPartitionThresholdInBytes(256MB) ,就认为该分区是倾斜分区
- 512MB < skewedPartitionThresholdInBytes(1GB) ,就不是倾斜分区
- 再根据 advisoryPartitionSizeInBytes(256MB) , 对大分区进行拆分
- 512MB 被拆成两个小分区(512MB / 2 = 256MB)