深度学习技巧应用3-神经网络中的超参数搜索
大家好,我是微学AI,今天给大家带来深度学习技巧应用3-神经网络中的超参数搜索。
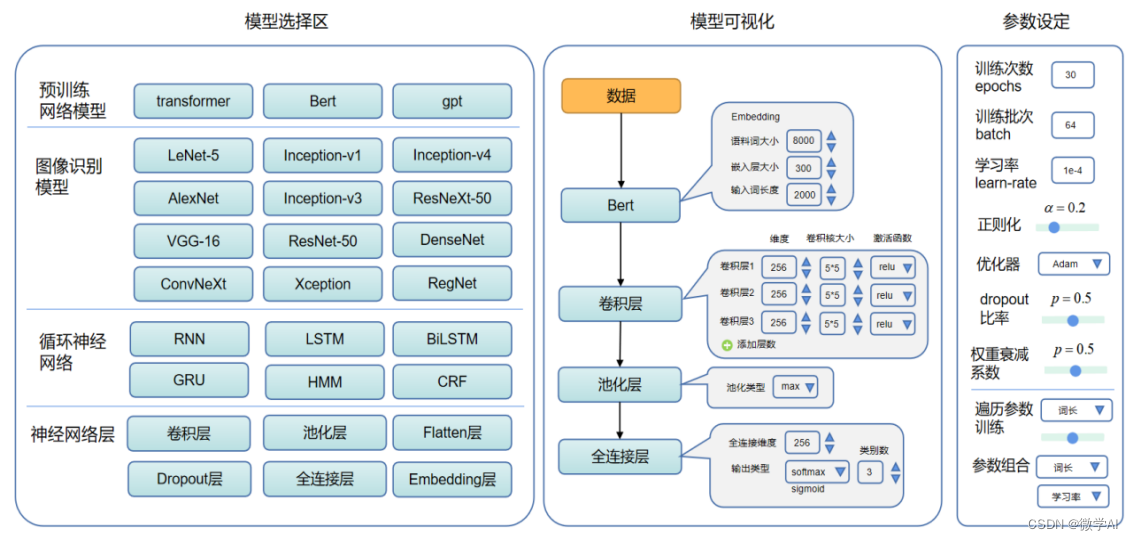
在深度学习任务中,一个算法模型的性能往往受到很多超参数的影响。超参数是指在模型训练之前需要我们手动设定的参数,例如:学习率、正则化强度、网络层级结构、训练批次、训练次数等。为了得到最佳的超参数设置,可以采用超参数搜索的方式,搜索最佳的超参数组合。
超参数搜索是一种通过自动化方法寻找最佳超参数设置的技术。目标是通过系统地搜索超参数空间来最小化模型的误差或最大化模型的表现。超参数搜索是一个非常耗时和繁重的任务,因为可能需要在很广的超参数空间内搜索,而每个超参数组合都需要训练模型并进行评估。
一、常见的超参数搜索方法:
网格搜索:网格搜索是一种通过遍历超参数空间中所有可能的组合来搜索最佳超参数的方法。具体地,将每个超参数的可能取值组成一个网格,然后对所有可能的组合进行训练和评估,从而找到最佳的超参数组合。
随机搜索:随机搜索是一种通过在超参数空间中随机采样来搜索最佳超参数的方法。具体地,随机选择一组超参数进行训练和评估,然后根据评估结果调整下一组超参数的选择。
贝叶斯优化:贝叶斯优化是一种通过构建高斯过程模型来搜索最佳超参数的方法。具体地,通过不断地调整高斯过程模型的参数,来寻找最佳的超参数组合。
群智能优化:群智能优化是一种通过模拟自然界中群体智能行为来搜索最佳超参数的方法。具体地,将超参数的取值看作粒子,利用粒子群算法或其他群体智能算法进行搜索。
二、超参数搜索原理
超参数搜索的原理是在模型训练之前,通过尝试不同的超参数组合来找到最优的超参数配置,从而达到最佳的模型性能。超参数搜索的本质是一个寻优问题,目标是寻找一个最优的超参数组合,使得模型在训练集上的性能最好,并在测试集上具有良好的泛化性能。
超参数搜索的过程可以描述为以下几个步骤:
定义超参数空间:超参数搜索的第一步是定义超参数空间,即确定每个超参数的可能取值范围。通常使用经验值或者网格搜索来定义超参数空间。
遍历超参数空间:超参数搜索的下一步是遍历超参数空间中的每个可能的超参数组合,即在超参数空间中尝试不同的超参数组合。
训练模型:对于每个超参数组合,需要在训练集上训练模型,通常使用交叉验证来评估模型性能。
选择最优超参数组合:根据模型在训练集上的性能,选择最优的超参数组合。通常使用准确率、损失函数或其他评价指标来衡量模型的性能。
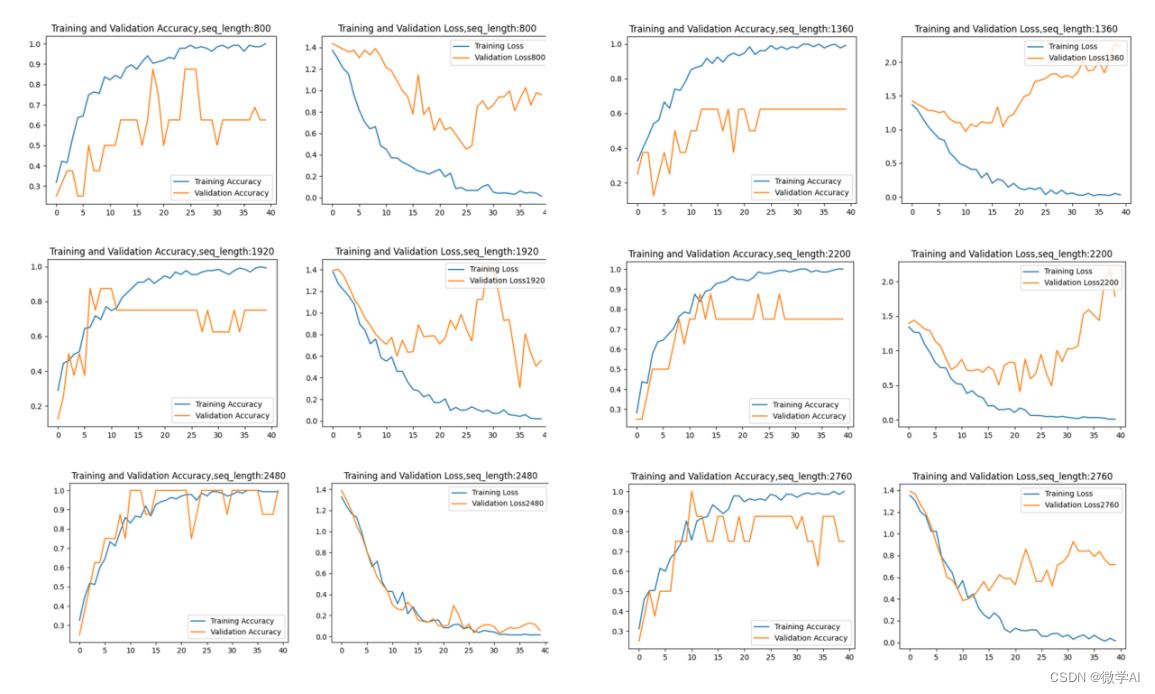
根据以上步骤,在小范围内进行遍历训练操作,可观察到不同值下的训练效果,根据训练效果图选择最优的超参数组合。
三、超参数搜索代码案例
利用使用GridSearchCV进行超参数搜索,首先使用make_classfication函数生成一个包含1000个样本和10个特征的二分类数据集。再将数据集划分为训练集和测试集,其中训练集占80%。
然后定义超参数空间,即待搜索的超参数值列表。代码案例我使用KNeighborsClassifier分类器。
定义GridSearchCV对象,传入模型、超参数空间、交叉验证折数、和并行计算的进程数。训练模型并搜索最佳超参数组合,最后输出最佳的超参数组合和对应的模型性能。、
具体代码如下:
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import make_classification
import numpy as np# 生成二分类数据
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5,n_redundant=0, n_clusters_per_class=2, random_state=42)# 划分训练集和测试集
train_size = 0.8
train_samples = int(X.shape[0] * train_size)
X_train, y_train = X[:train_samples], y[:train_samples]
X_test, y_test = X[train_samples:], y[train_samples:]# 定义超参数空间
param_grid = {'n_neighbors': [3, 5, 7],'weights': ['uniform', 'distance'],'metric': ['euclidean', 'manhattan']
}# 定义模型
model = KNeighborsClassifier()# 定义网格搜索对象
grid_search = GridSearchCV(model, param_grid, cv=5, n_jobs=-1)# 训练模型并搜索最佳超参数组合
grid_search.fit(X_train, y_train)# 输出最佳的超参数组合和对应的模型性能
print("Best parameters: {}".format(grid_search.best_params_))
print("Best cross-validation score: {:.2f}".format(grid_search.best_score_))
print("Test set score: {:.2f}".format(grid_search.score(X_test, y_test)))输出结果:
Best parameters: {'metric': 'manhattan', 'n_neighbors': 3, 'weights': 'uniform'}
Best cross-validation score: 0.93
Test set score: 0.90
有问题需要沟通可私信,可合作。