Python+Selenium+Unittest 之Unittest3(TestSuite()和TextTestRunner())
目录
1:addTest()
2、addTests()
3:discover()
上一篇说了Unittest的一个基本的执行顺序,那如果我们想要调整用例的执行先后顺序的话,可以用TestSuite()和TextTestRunner()了,可以这么理解,比如一个班级里有50个学生(50条用例),其中有10个学生获得了评优(10条需要执行),然后需要单独叫出来领奖,然后这10个学生领奖的时候需要按照一定顺序进行排队上台(进行用例的先后顺序排列),TestSunit()的作用就可以把这10个学生叫出来并且排好队,然后这会该上台了,这时候就需要搭配上TextTestRunner()来使用了,可以把TextTestRunner()当成老师,你们用TestSunite()排好队了,然后听TextTestRunner()指挥来按顺序上台(按之前排好的顺序进行运行)。
下面重点说下怎么对学生进行排队(怎么添加需要执行的用例)。
1:addTest()
添加需要执行用例时,可以使用addTest()的方式一个一个的去添加,具体用法在addTest()里写上类和对应用例即可(addTest(类(方法)) )。
import unittest #导入unittest的框架
class Atmunit_case(unittest.TestCase): #定义一个class类的名称,并且继承unittest的框架def setUp(self):print("----用例开始了-----")def test_111(self): #只能以小写test开头,一个def就可以理解成一个测试用例,但是这里的命名必须是以test开头,这个会区分大小写,必须是全部小写的testprint("用例1") #用例内容def test_222(self): #定义第二个测试用例,不是以test开头,这个不会被执行print("用例2") #用例内容def ddd(self): #写一个ddd的方法,看会不会运行print(11111)def tearDown(self): #结束的执行print("-------执行结束了-----")if __name__ == '__main__': #运行unittest框架suite = unittest.TestSuite() #把TestSuite实例化suite.addTest(Atmunit_case('test_222')) #调整执行顺序,优先执行test_222用例,括号里需要填写类名(class后面的名字)和对应的函数名(def后面的名字)suite.addTest(Atmunit_case('test_111')) #然后执行test_11用例suite.addTest(Atmunit_case('ddd')) #写上ddd看会不会执行(结果是会运行的,但是这样不太符合unittest的规范,最好少出现这样的写法)runner = unittest.TextTestRunner() #实例化TextTestRunner()runner.run(suite) #执行上述用例执行结果为:
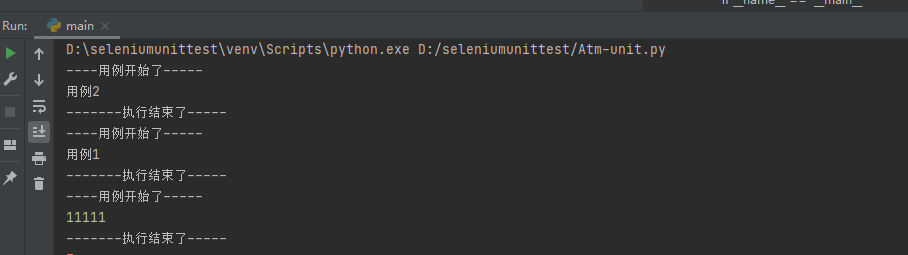
----用例开始了-----
用例2
-------执行结束了-----
----用例开始了-----
用例1
-------执行结束了-----
----用例开始了-----
11111
-------执行结束了-----
执行截图:
2、addTests()
下面说下addTests()的方法,用法和addTest()没啥太大区别,这个可以把需要执行的用例提前定义下,test = (类(方法1),类(方法2),类(方法3)),然后把test传到addTests()里即可。
import unittest #导入unittest的框架
class Atmunit_case(unittest.TestCase): #定义一个class类的名称,并且继承unittest的框架def setUp(self):print("----用例开始了-----")def test_111(self): #只能以小写test开头,一个def就可以理解成一个测试用例,但是这里的命名必须是以test开头,这个会区分大小写,必须是全部小写的testprint("用例1") #用例内容def test_222(self): #定义第二个测试用例,不是以test开头,这个不会被执行print("用例2") #用例内容def ddd(self): #写一个ddd的方法,看会不会运行print(11111)def tearDown(self): #结束的执行print("-------执行结束了-----")if __name__ == '__main__': #运行unittest框架suite = unittest.TestSuite() #把TestSuite实例化testcase = (Atmunit_case('test_222'),Atmunit_case('test_111'),Atmunit_case('ddd')) #把用例传入到testcase中suite.addTests(testcase) #使用addTests()的方法批量添加用例runner = unittest.TextTestRunner() #实例化TextTestRunner()runner.run(suite) #执行上述用例
执行结果为:
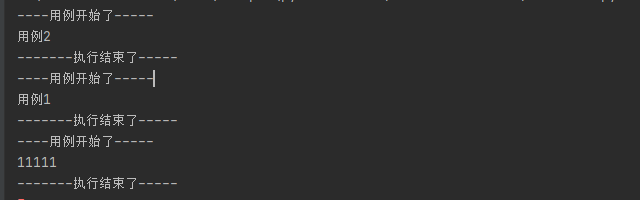
----用例开始了-----
用例2
-------执行结束了-----
----用例开始了-----
用例1
-------执行结束了-----
----用例开始了-----
11111
-------执行结束了-----
执行截图;
3:discover()
当有多个测试文件需要执行时,也可以选择discover()的方式,具体用法为:
unittest.defaultTestLoader.discover(start_dir='.',pattern="test_case*.py",top_level_dir=None)#start_dir 表示要搜索的文件路径,通常设置为 . 表示为当前目录pattern 表示要搜索的文件的名称格式,*为通配符表示任意内容,这个的意思是以test_case开头然后中间有任意内容,最后以.py结尾的文件top_level_dir 表示是否为项目的顶层目录,用于去寻找相对的导入路径,一般默认即可,或者可以不写 比如截图中的目录,我们有test_case_01、test_case_02、test_case_03、test11_case_04这几个目录,这几个里面分别对应不同的用例。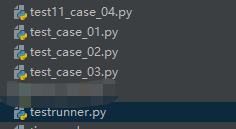
test_case_01.py里面的内容
import unittest #导入unittest的框架
class test_case_01(unittest.TestCase): #定义一个class类的名称,并且继承unittest的框架def test_101(self): #定义test_101的测试方法print('test_case_101')def test_102(self): #定义test_102的测试方法print('test_case_102')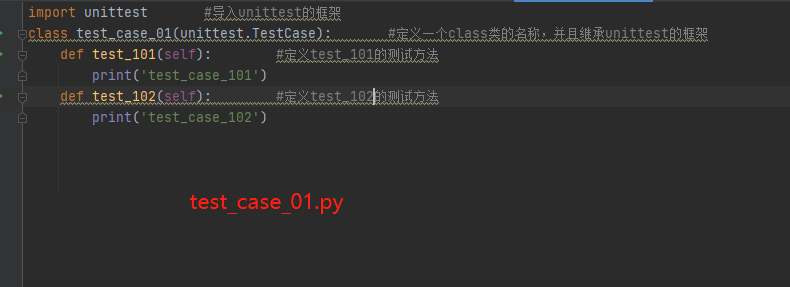
test_case_02.py里面的内容:
import unittest #导入unittest的框架
class test_case_02(unittest.TestCase): #定义一个class类的名称,并且继承unittest的框架def test_201(self): #定义test_201的测试方法print('test_case_201')def test_202(self): #定义test_202的测试方法print('test_case_202')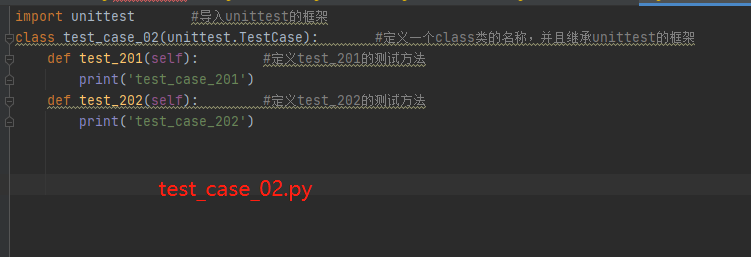
test_case_03.py里面的内容:
import unittest #导入unittest的框架
class test_case_03(unittest.TestCase): #定义一个class类的名称,并且继承unittest的框架def test_301(self): #定义test_301的测试方法print('test_case_301')def test_302(self): #定义test_302的测试方法print('test_case_302')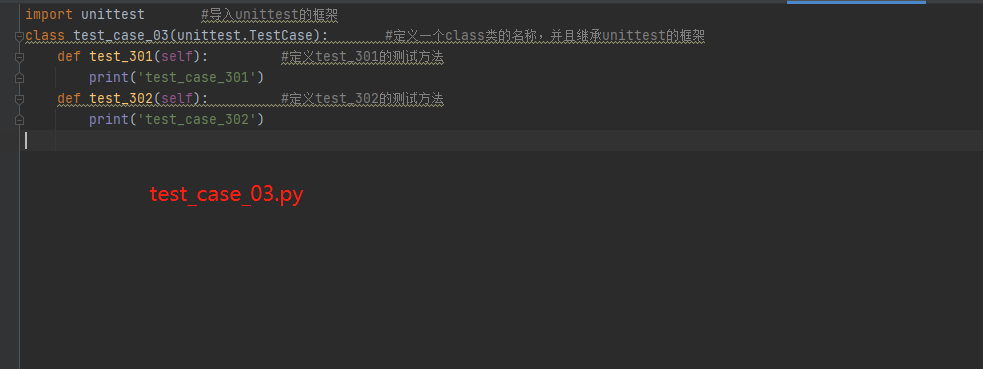
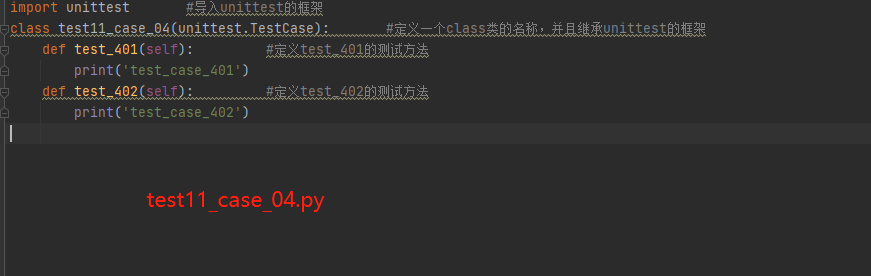
test11_case_04.py里面的内容:
import unittest #导入unittest的框架
class test11_case_04(unittest.TestCase): #定义一个class类的名称,并且继承unittest的框架def test_401(self): #定义test_401的测试方法print('test_case_401')def test_402(self): #定义test_402的测试方法print('test_case_402')
testrunner.py里面的内容:
import unittest#discover = unittest.defaultTestLoader.discover(start_dir='.',pattern="test_case*.py",top_level_dir=None)#设定需要运行的用例范围discover = unittest.defaultTestLoader.discover(start_dir='.',pattern="test_case*.py") #设定需要运行的用例范围
unittest.TextTestRunner().run(discover) #运行测试用例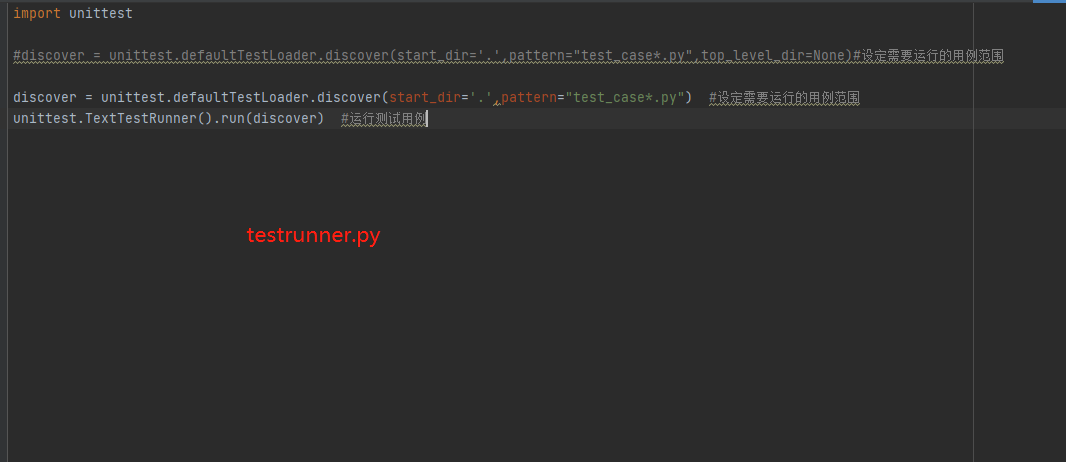
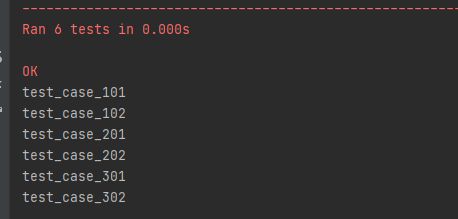
只需要运行testrunner.py即可,他会去找符合的文件,并运行里面的测试用例(test_case开头的方法),因为按着上面的匹配方式来说,test11_case_04.py不符合匹配的条件,所以只运行了test_case_01、test_case_02、test_case_03三个文件里的用例。
运行结果为:
test_case_101
test_case_102
test_case_201
test_case_202
test_case_301
test_case_302
一般来说每个单独的功能写到一个独立的测试文件中,其命名开头最好都用test开头,这样使用discover()的方式运行运行时匹配的比较准确,discover()为最常用的用例条件运行方式。
如果大家在使用过程中遇到了问题,可以在文章下留言,或者关注公众号:刘阿童木的进化记录,进行留言
下图为公众号二维码,内容会同步发出,大家可以关注一起学习!
