Python基础之pandas:文件读取与数据处理
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、文件读取
- 1.以pd.read_csv()为例:
- 2.数据查看
- 二、数据离散化、排序
- 1.pd.cut()离散化,以按范围加标签为例
- 2. pd.qcut()实现离散化
- 3.排序
- 4.Series.map()&Series.apply()
- 三、数据处理
- 1.发现缺失值
- 2.剔除缺失值
- 3.填充缺失值
- 1)固定值填充
- 2)前向填充&后向填充
- 4.df.replace()
- 5.重复值处理
- 6.四分位法识别异常值
- 四、分组、索引及聚合
- 1.分组函数
- 2.索引设置与重置
- 1)重置索引
- 2)设置索引
- 3)索引排序
- 3.分组后常见操作
- 1)分组后聚合
- 2)分组后过滤filter
- 3)分组后过滤transform
- 4)分组后过滤apply
一、文件读取
方法:
- pd.read_csv()
- pd.read_excel()
- pd.read_json()
- pd.read_sql()
- pd.read_xml()
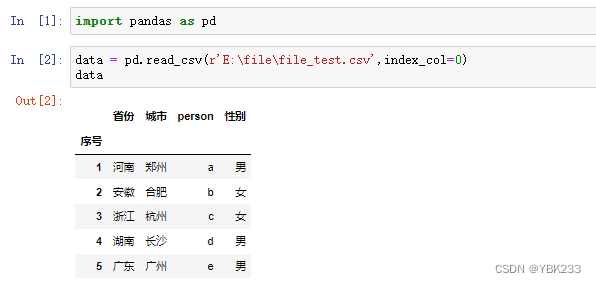
1.以pd.read_csv()为例:
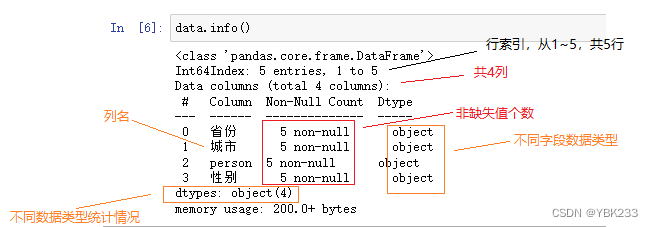
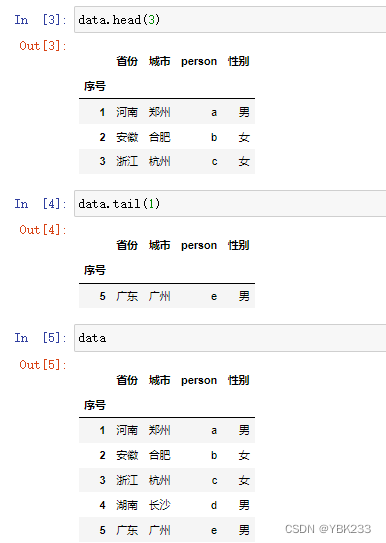
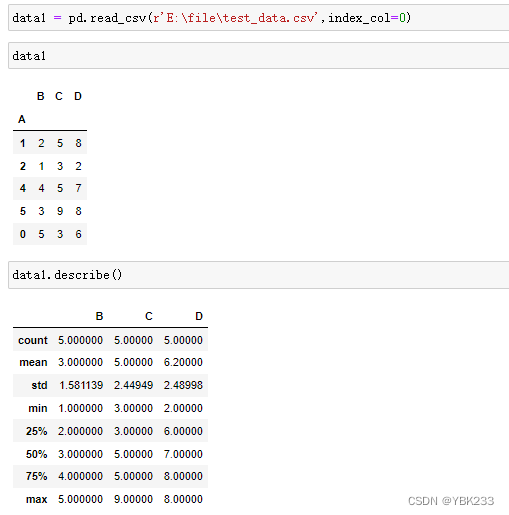
2.数据查看
df.describe()方法只针对数值列的描述性统计
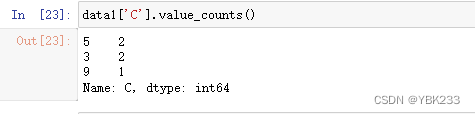
统计出现次数
二、数据离散化、排序
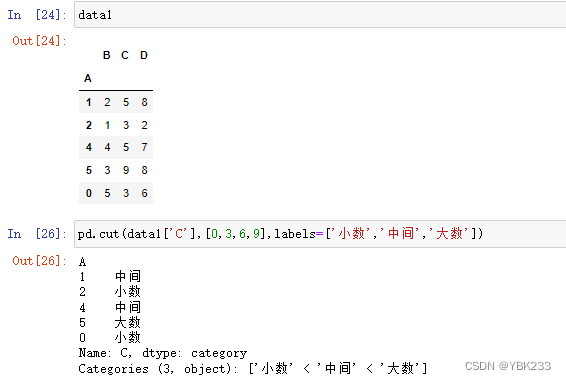
1.pd.cut()离散化,以按范围加标签为例
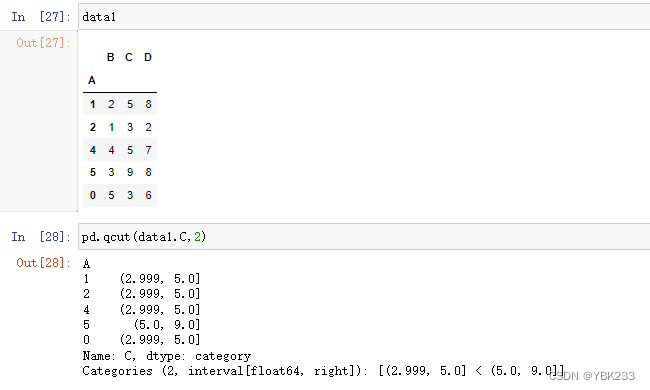
2. pd.qcut()实现离散化
cut是根据每个值进行离散化,qcut是根据每个值出现的次数进行离散,也就是基于分位数的离散化功能
3.排序
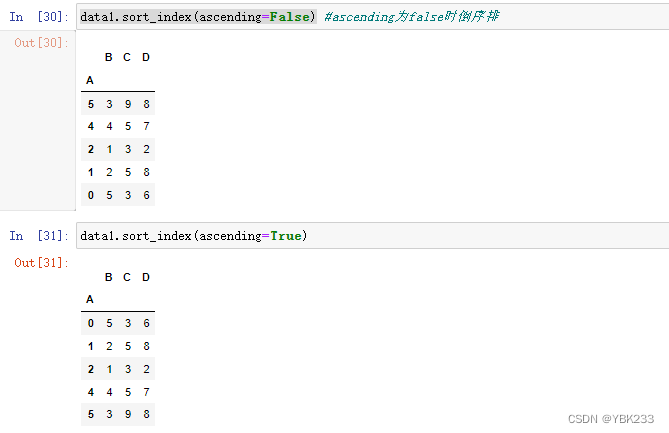
- df.sort_index():按照默认索引按正序排序
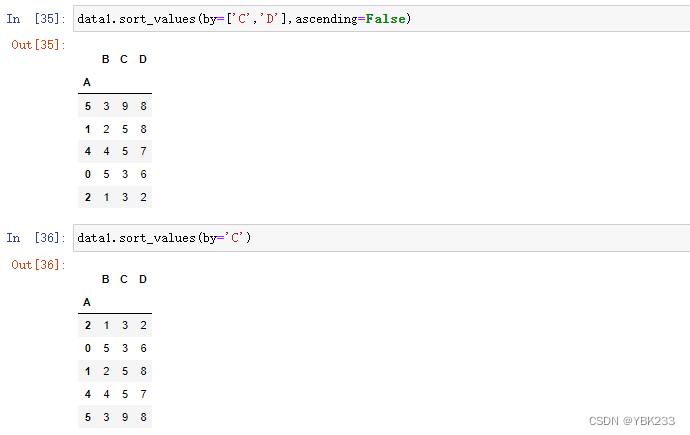
- data1.sort_values()按照实际值排序
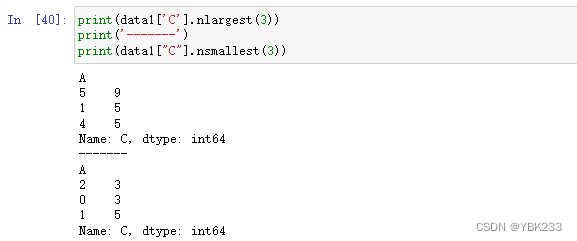
- Series.nlargest()获取前N个最大值,与之相对于的为Series.nsmallest()
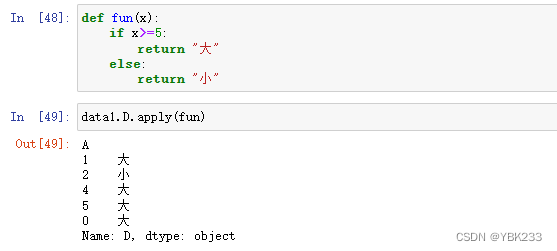
4.Series.map()&Series.apply()
-
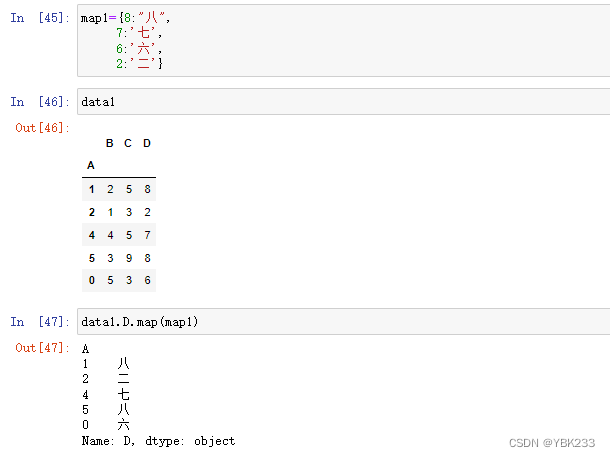
Series.map()
map()是Series中特有方法,通过它实现对Series每个元素互换
-
Series.apply()和df.apply()
apply()在对Series操作时,会作用到每个值上,在对DataFrame操作时,会作用到所有行或列(通过axis控制)
-
df.applymap()
applymap方法针对与DataFrame,其效果类似于apply对series的效果 -
pandas中map()、apply()、applymap()的区别:
1、map()方法适用于Series对象,作用于Series里的一个个元素,可以通过字典或函数类对象来构建映射关系对Series对象进行转换;
2、apply()方法适用于Series对象、DataFrame对象、Groupby对象Series.apply()作用于Series里的一个个元素df.apply()处理的是行或列数据(本质上处理的是单个Series),用函数类对象来构建映射关系对Series对象进行转换;
3、applymap()方法用来处理DataFrame对象的单个元素值,作用于df中的一个个元素,也是使用函数类对象映射转换;
三、数据处理
1.发现缺失值
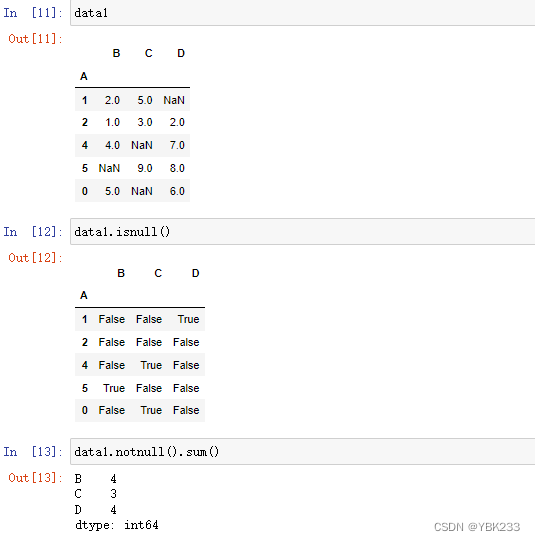
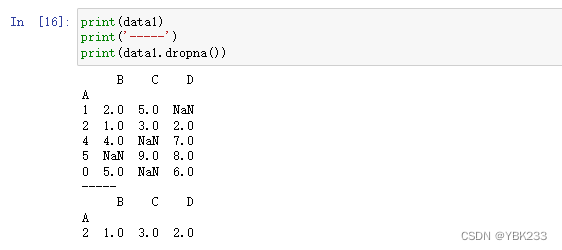
2.剔除缺失值
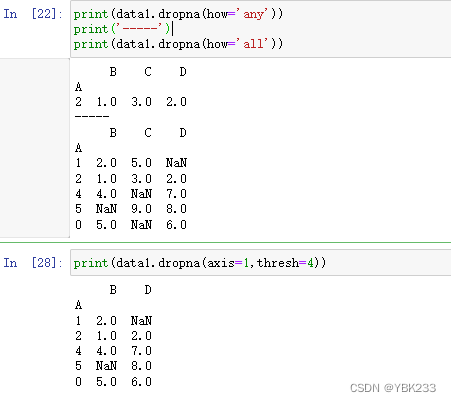
df.dropna():
- how:how为all时,只有当该列(或行)全部缺失时,才会将该列删除;为any时,当该列(或行)有缺失时,会将该列删除
- thresh:设置非缺失值个数,axis=1当该列非缺失值个数大于等于设置的值时,该列保留,否则删除

3.填充缺失值
df.fillna()
填充思路
- 根据业务知识填充
- 连续性变量缺失值的填充(均值、众数)
- 分类型变量缺失值的填充(众数)
- 预测值填充
1)固定值填充
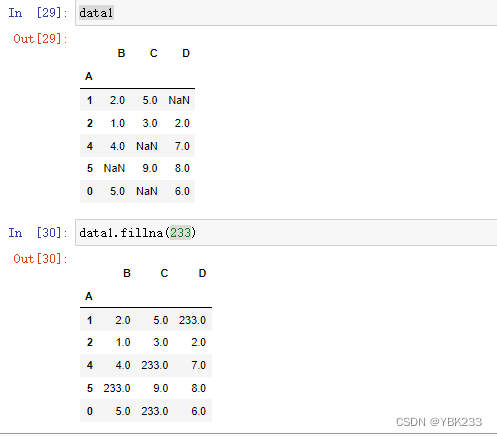
2)前向填充&后向填充
- 前向填充:取前一个值填充
- 后向填充:取后一个值填充

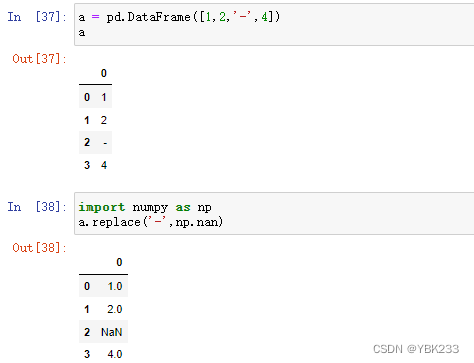
4.df.replace()
有些异常值“-”,不是缺失值,但程序无法处理,需要换成程序可失败的缺失值
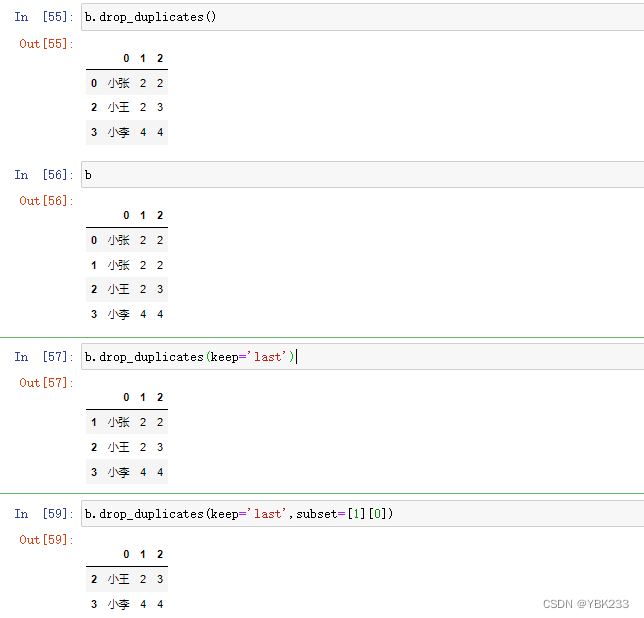
5.重复值处理
df.drop_duplicates()
- 不传参时,删除一模一样的数据,并保留出现的第一条
- keep:first、last、false数据保留原则
- subset用作字段判断依据
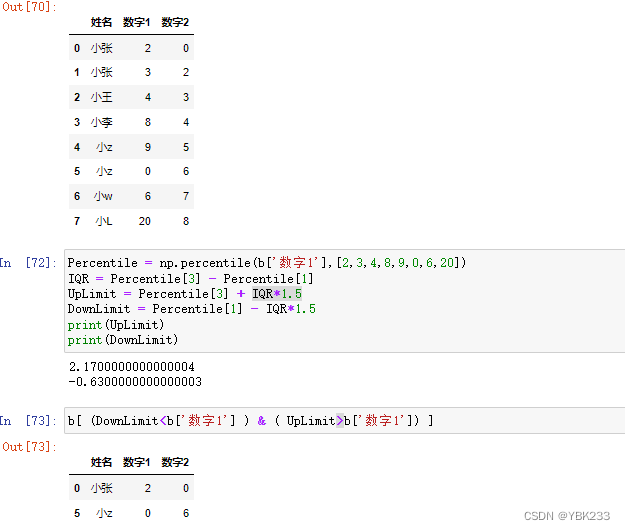
6.四分位法识别异常值
四、分组、索引及聚合
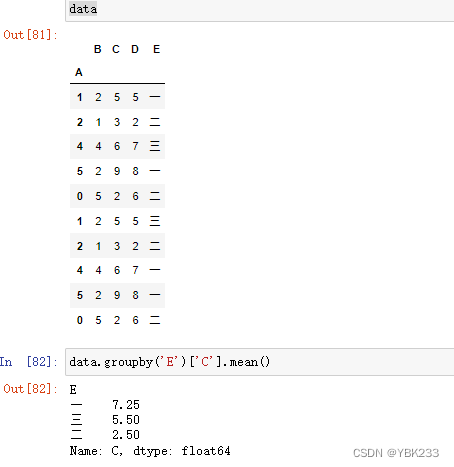
1.分组函数
groupby函数之间按组进行迭代,每一组都是Series或DataFrame
2.索引设置与重置
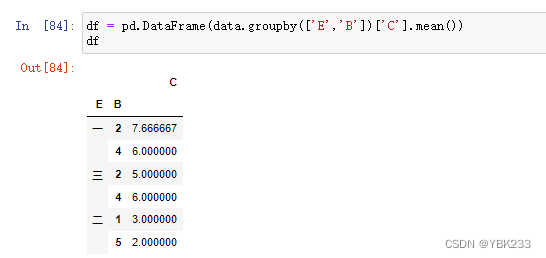
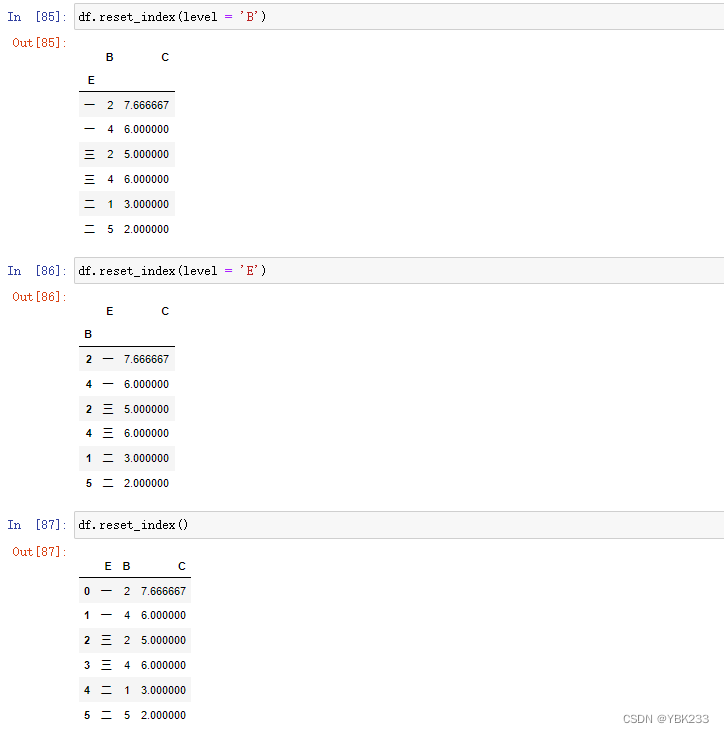
1)重置索引
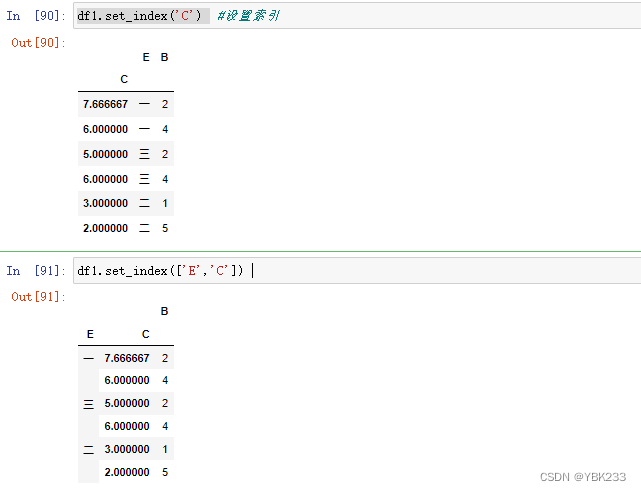
2)设置索引
3)索引排序
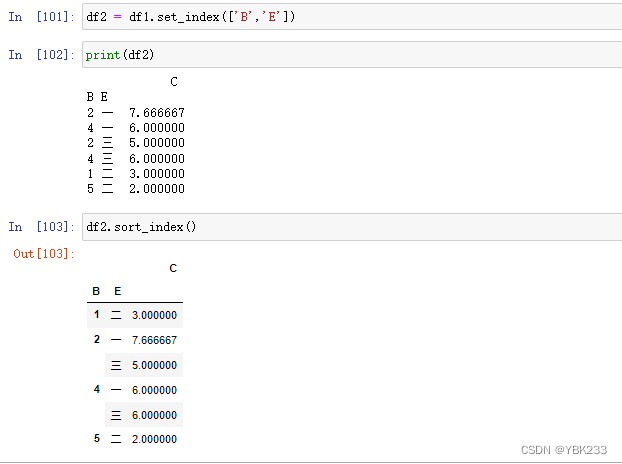
3.分组后常见操作
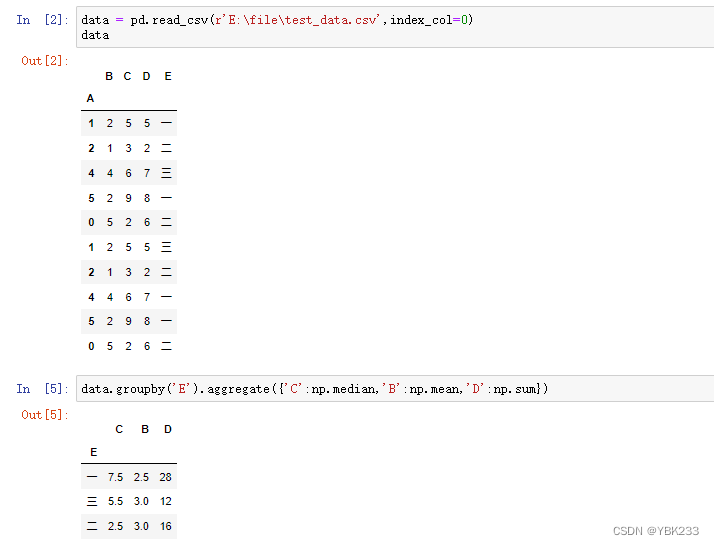
1)分组后聚合
groupby().aggregate()方法,填入对应字典映射,即可查看数据中位数、均值,合计
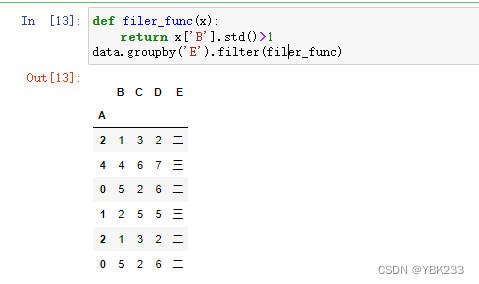
2)分组后过滤filter
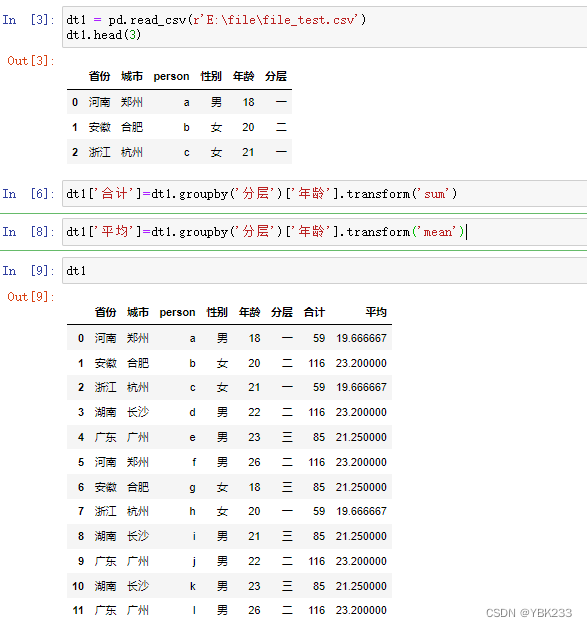
3)分组后过滤transform
groupby().transform()方法,在数据转换之后的形状和原来是一样的,但并不是单纯的将一列数据转换,而是对分组之后的小组数据内部按照相同的逻辑和组内指标进行转换,常见的例子是实现组内数据标准化
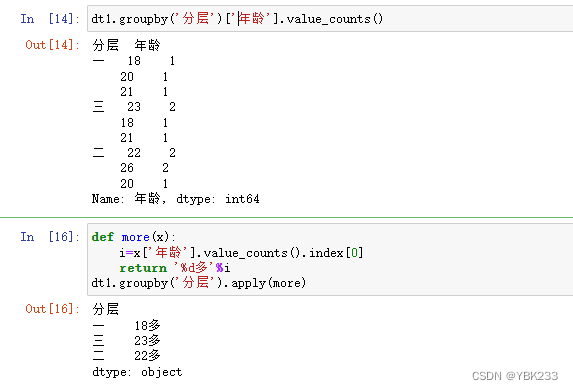
4)分组后过滤apply
输入一个分组的DataFrame进行apply(),可以返回一个DataFrame或Series或一个标量。
group和apply的组合操作可以适应apply()返回的结果类型