基础篇3 浅试Python爬虫爬取视频,m3u8标准的切片视频
浅试Python爬取视频
1.页面分析
- 使用虾米视频在线解析
- 使用方式:https://jx.xmflv.cc/?url=目标网站视频链接
- 例如某艺的视频 原视频链接
解析结果:
1.1 F12查看页面结构
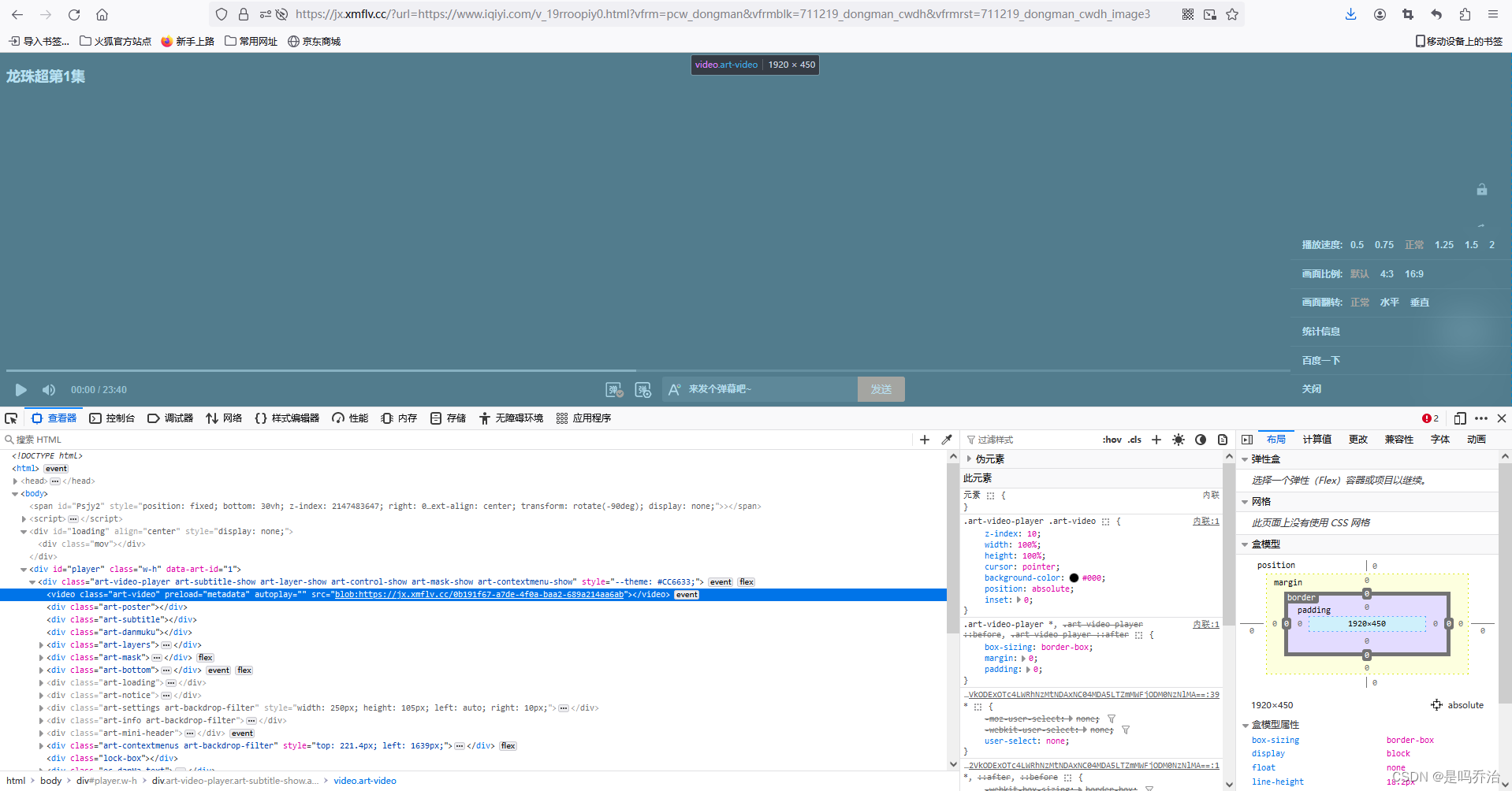
我们发现页面内容中什么都没有,video标签中的src路径也不是视频的数据。
1.2 老规矩看网络请求中的过滤的XHR
发现一堆没卵用的数据返回,直到我们看到这个mixed.m3u3结尾的返回结果,及后续高度相似的请求数据
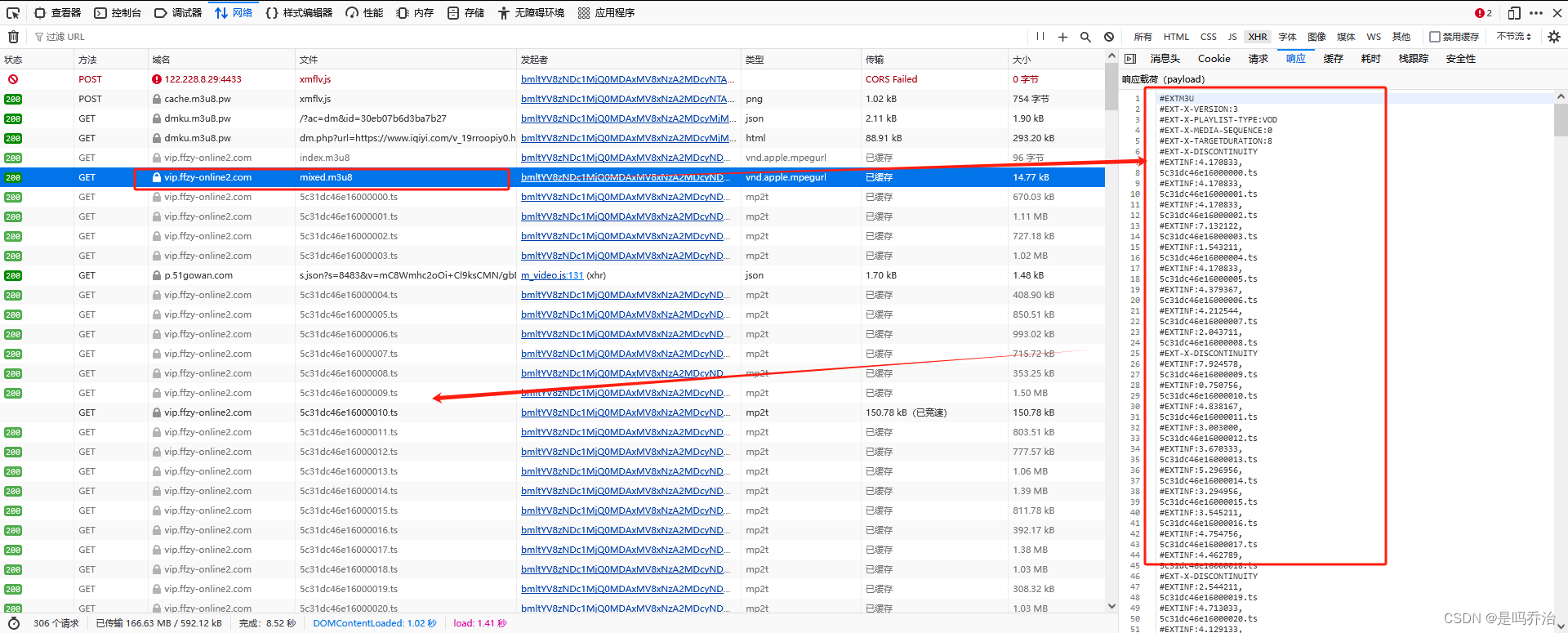
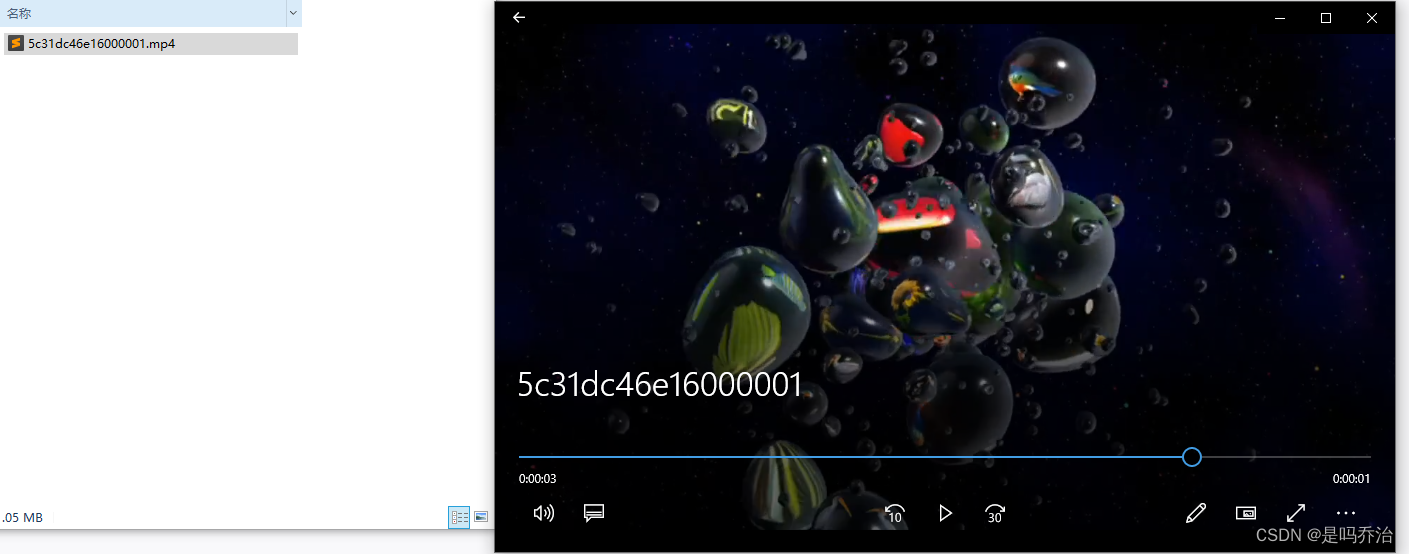
1.3解析mp2t媒体文件
将上一步中的mp2t媒体文件随机挑选一个下载下来。打开后就是我们的目标视频。ok目的达到。
 接下来我们要做的就是将返回的mixed.m3u8解析出来
接下来我们要做的就是将返回的mixed.m3u8解析出来
2.功能实现
2.1 拿到m3u8的文件
#-*- coding:UTF-8 -*-import requests
import os
import sysres = requests.get('https://vip.ffzy-online2.com/20221231/3848_0533f6da/2000k/hls/mixed.m3u8')
m3u8_obj = res.text
print(m3u8_obj)
可以看到打印结果
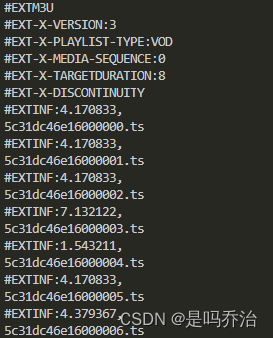
到这里我们就需要拿到ts结尾的字符串,然后筛选出以ts结尾的字符串。
2.2 解析m3u8的信息
m3u8 = m3u8_obj.split('\n')
# 匹配*.ts结尾的字符串
rst = [s for s in m3u8 if s.endswith('.ts')]
print(rst)
我们可以看到打印结果
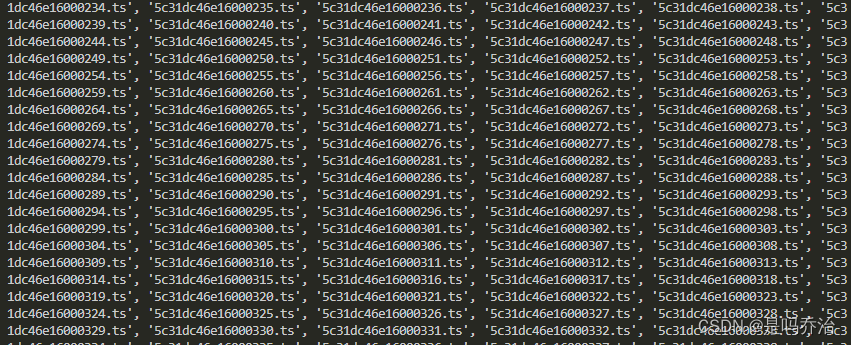
接下来就需要拼接字符串获取到视频的路径,下载下来之后再进行拼接。
2.3 下载视频
baseurl= 'https://vip.ffzy-online2.com/20221231/3848_0533f6da/2000k/hls/'
# 下载并保存TS分片
for i, url in enumerate(rst):response = requests.get(baseurl+url, stream=True)with open(f'segment{i + 1}.ts', 'wb') as out_file:out_file.write(response.content)
于是我们可以看到
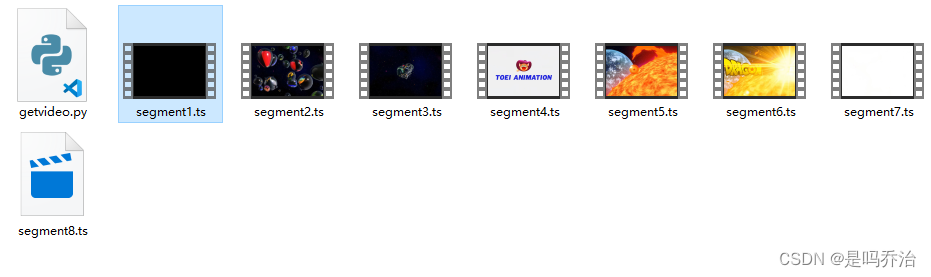
现在切片视频正确拿到了
- 可以利用第三方软件进行视频合并
- 可以先创建一个.MP4格式的文件使用python写入文件的方法进行合并
2.4 合并
# 将下载的视频合并起来
# 拿到文件名
file_names = os.listdir('./video')
# 最终视频路径
target_video = open('./output.mp4','ab')
# 遍历全部视频集合
for file in file_names:with open('./video/'+file,"rb") as f:target_video.write(f.read())f.close()
target_video.close()
我只是下载的部分视频,成功合成看结果:
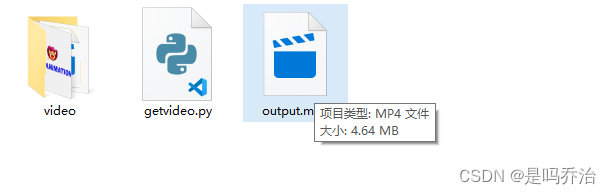
3.整合一下
# -*- coding:utf-8 -*-import requests
import os
import sysclass getvideo(object):def __init__(self) -> None:self.baseurl = 'https://vip.ffzy-online2.com/20221231/3848_0533f6da/2000k/hls/' # ts视频的路径self.m3u8url = 'https://vip.ffzy-online2.com/20221231/3848_0533f6da/2000k/hls/mixed.m3u8' # m3u8文件的路径self.ts_video = [] # 存放解析后的ts视频信息def geturlbyts(self):res = requests.get(self.m3u8url)m3u8_obj = res.text m3u8 = m3u8_obj.split('\n') # 按照换行分割# 匹配*.ts结尾的字符串self.ts_video = [s for s in m3u8 if s.endswith('.ts')]# 下载并保存TS分片def downloadvideobyts(self):for i, url in enumerate(self.ts_video):response = requests.get(self.baseurl+url, stream=True)with open(f'.\\video\\'+self.ts_video[i], 'wb') as out_file:sys.stdout.write("下载进度:{0:.2f}%" .format(float((i+1)/len(self.ts_video))*100) + '\r')sys.stdout.flush()out_file.write(response.content)def mergevideo(self):# 将下载的视频合并起来# 拿到文件名file_names = os.listdir('./video')# 最终视频路径target_video = open('./output.mp4','ab')# 遍历全部视频集合for file in file_names:with open('./video/'+file,"rb") as f:print("当前合并到{}".format(file))target_video.write(f.read())f.close()target_video.close()dlvideo = getvideo()
dlvideo.geturlbyts()
# 当前目录创建一个video文件夹 用来存储ts分片视频
# 创建个文件夹存储视频
os.makedirs('video',exist_ok=True)
dlvideo.downloadvideobyts()
dlvideo.mergevideo()
print("合并完成")
单线程着实慢,后续继续更新学习。
以上仅供学习使用,下载后请于24小时内删除。