Clip算法解读
论文地址:https://arxiv.org/pdf/2103.00020.pdf
代码地址:https://github.com/OpenAI/CLIPz
中文clip代码:https://gitcode.com/OFA-Sys/Chinese-CLIP/overview
一、动机
主要解决的问题:
- 超大规模的文本集合训练出的 NLP 模型性能是足以超越高质量,大量标注数据集训练的结果的。但是,反观 CV 领域,当时大家还在使用高质量,密集标注数据集 (如 ImageNet-1K) 进行预训练。
- 这种ImageNet等数据训练好的模型对训练过程中出现的对象类别有很好的识别效果,但是对训练过程中未出现的类别,识别效果很差。
二、数据集
本文的一个主要特点是想利用互联网上大量公开可用的数据。由于现有的数据集 (MS-COCO 约100,000张,YFCC100M 高质量的仅仅约 15M 张,和 ImageNet-1K 大小相似) 不够大,可能会低估这一研究领域的潜力。
为了解决这个问题,作者构建了一个新的数据集,其中包含4亿对 (图像,文本) 对,这些数据来自互联网上各种公开可用的资源。而且这个数据清理得非常好,质量是非常高的,这也可能是 CLIP 这么强大的主要原因之一。结果数据集的总字数与用于训练 GPT-2 的 WebText 数据集相似,因此作者将此数据集称为 WebImageText (WIT)。
三、预训练方法
本文采取基于对比学习的高效预训练方法。作者的思路是这样的:一开始的方法是联合训练了一个处理图像的 CNN 和一个处理文本的 Transformer 模型,来预测图像的 caption。这个实验结果如下图1的蓝色曲线所示,可以看到其 Scalability 是很差的。橘红色曲线是预测文本的词袋,其效率是蓝色曲线的3倍。这两种方法都有一个关键的相似性,即试图去预测每幅图片对应的文字的确切单词是什么。但我们知道这可不是一件容易的事,因为与同一幅图像对应的描述、注释和相关文本种类繁多。
基于最近的图像对比表征学习方面的研究,可以仅预测整个文本与哪个图像配对,而不是该文本的确切单词。
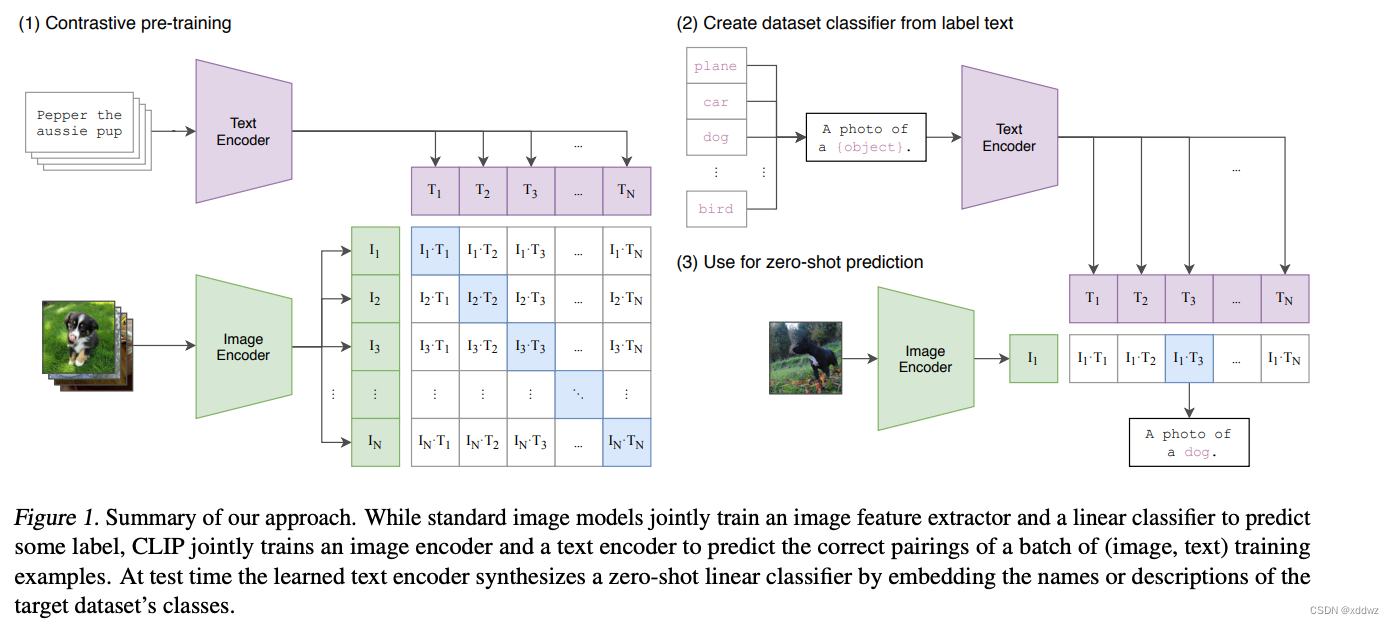
对比学习阶段:如图1左边所示,给定一个 Batch 的 N个 (图片,文本) 对,图片输入给 Image Encoder 得到图像特征 ,文本输入给 Text Encoder 得到文本特征 ,作者认为图像与文本匹配时属于是正样本, 否则属于负样本。最大化N个正样本的 Cosine 相似度,最小化N*N-N个负样本的 Cosine 相似度。
伪代码如图:

上面代码中,分别得到图像和文本的特征,然后从图像的角度判读文本是否与其对应,然后再从文本的角度,判读图像是否与其对应。分别计算损失后相加。
作者从头开始训练 CLIP,不使用 ImageNet-1K 权重初始化 Image Encoder,也不使用预先训练的权重初始化 Text Encoder。同时使用线性投影将每个编码器的表征映射到多模态的嵌入空间。数据增强只使用随机裁剪,温度系数的对数形式随整个模型一起训练。
Zero-Shot Transfer:如图一中右边的图所示,这个阶段是使用 CLIP 的预训练好的 Image Encoder 和 Text Encoder 来做 Zero-Shot Transfer。比如来一张 ImageNet-1K 验证集的图片,我们希望 CLIP 预训练好的模型能完成这个分类的任务。但是你想想看,这个 Image Encoder 是没有分类头 (最后的 Classifier) 的,也就是说它没法直接去做分类任务,所以说呢 CLIP 采用了下面的 Prompt Template 模式:
比如来一张 ImageNet-1K 验证集的图片,作者把它喂入 CLIP 预训练好的 Image Encoder,得到特征 I1 ,接下来把所有类别的词汇 "cat", "dog" 等,做成一个 prompt:"A photo of a {object}",并将这个 prompt 喂入 CLIP 预训练好的 Text Encoder,依次得到特征,最后看哪个的余弦相似度和 I1 最高,就代表该图片是哪个类别的。
那我们就可以注意到貌似这个 prompt 的加入很关键,正好弥补了 Image Encoder 没有分类头的问题,又正好用上了 CLIP 训练好的 Text Encoder。
而且重要的是,CLIP 的这种推理的方法摆脱了类别的限制,比如一张 "三轮车" 的图片,假设 ImageNet 里面没有 "三轮车" 这个类,那么基于 ImageNet 所训练的任何模型都无法正确地讲这个图片分类为 "三轮车" ,但是 CLIP 的范式是可以做到的,只需要去做成一个 prompt:"A photo of a {tricycle}"。