ThreadPool-线程池使用及原理
1. 线程池使用方式
示例代码:
// 一池N线程
Executors.newFixedThreadPool(int)
// 一个任务一个任务执行,一池一线程
Executors.newSingleThreadExecutorO
// 线程池根据需求创建线程,可扩容,遇强则强
Executors.newCachedThreadPool()
// 自定义线程池方式
new ThreadPoolExecutor(...)
注:一般在工作中都是根据业务场景进行自定义线程池,进行使用;
自定义线程池方法;详见后面章节:自定义线程池
2. 线程池底层工作原理
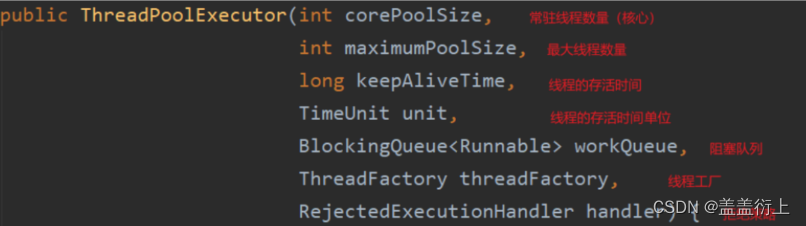
a. 线程池参数:
线程池,具有多个参数:具有各自的含义:
七参数:
- corePoolSize:核心线程数,一直保持活跃状态的线程
- maximumPoolSize:最大线程数,线程池能容纳的最大线程数量
- keepAliveTime:空闲线程存活时间,非核心线程的空闲存活时间
- unit:存活的时间单位,非核心线程的空闲存活时间单位
- workQueue:存放未执行任务的队列
- threadFactory:线程工厂,创建线程的工厂类
- handler:拒绝策略,队列满了和达到最大线程数后的拒绝策略
如图:
b. 线程池的拒绝策略
AbortPolicy:默认,直接抛出RejectedExcutionException异常,阻止系统正常运行
CallerRunsPolicy:该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者
DiscardPolicy:直接丢弃任务,不予任何处理也不抛出异常,如果允许任务丢失,这是一种好方案
DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加入队列中尝试再次提交当前任务
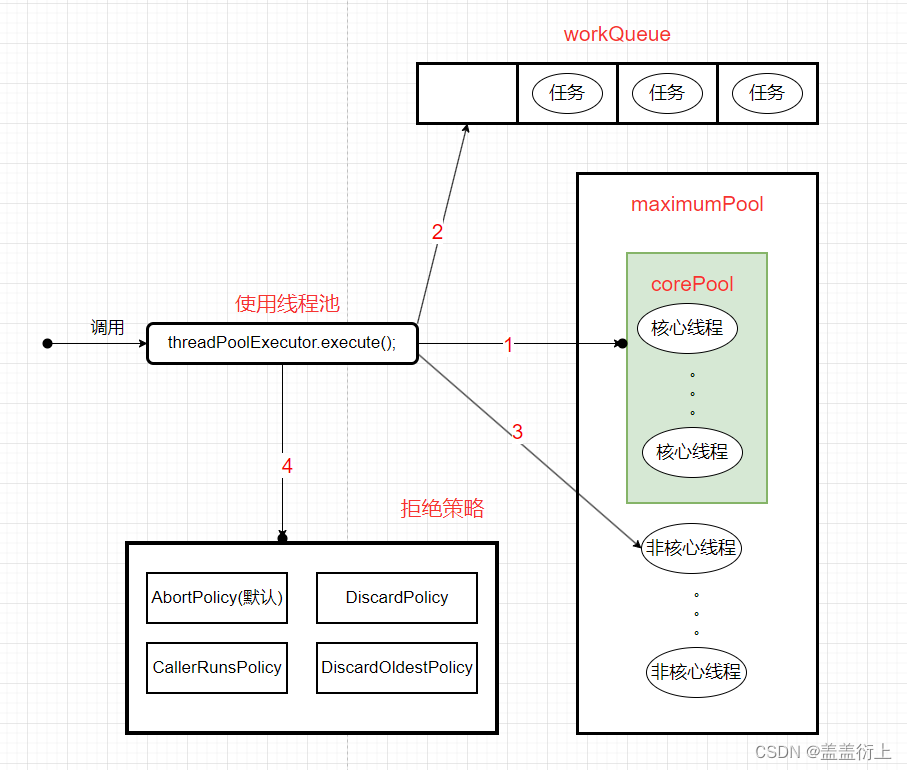
c. 线程池底层工作原理
-
在创建了线程池后,如果设置了核心线程数(corePoolSize),则线程池中的线程数会先创建相应数量的核心线程。如果没有任务到达,这些核心线程会保持活动状态。
-
当调用execute()方法添加一个请求任务时,线程池会根据以下判断来决定任务的执行方式:
- 如果正在运行的线程数量小于核心线程数(corePoolSize),则会立即使用核心线程来执行任务。
- 如果正在运行的线程数量大于或等于核心线程数,但任务队列未满,则任务会被放入队列中等待执行。
- 如果队列已满且正在运行的线程数量小于最大线程数(maximumPoolSize),则会创建非核心线程来执行任务。
- 这里需要注意,是先执行新的任务,队列里的任务不会执行,详见:5. 注意事项
- 如果队列已满且正在运行的线程数量已达到最大线程数,且拒绝策略允许,那么线程池会启动拒绝策略来处理新任务。
-
当一个线程完成任务时,它会从队列中取下一个任务来执行,或者在没有任务的情况下进入等待状态。
-
当一个线程空闲时间超过设定的keepAliveTime时,线程池会根据以下判断来决定线程的命运:
- 如果当前运行的线程数大于核心线程数(corePoolSize),则空闲线程会被终止。
- 线程池的所有任务完成后,它最终会收缩到核心线程数的大小。
-
注意事项:
在Java中java.util.concurrent.ThreadPoolExecutor线程池的默认行为是,当任务队列已满且再来一个新任务时,创建的新线程会被用来执行新来的任务而不是队列里已有的任务。
-
线程工作原理示意图:
3. 自定义线程池
a. 介绍:
前面提到过,一般在工作中都是根据业务场景进行自定义线程池;西面是阿里巴巴开发手册的说明;

b. 实现:
实现代码如下:
import org.jetbrains.annotations.NotNull;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.concurrent.*;/*** @author xxx* @version 1.0* @date xxx*/@Configuration
public class ThreadPoolExecutorConfig {@Beanpublic ThreadPoolExecutor threadPoolExecutor() {// 创建自定义线程池int corePoolSize = 2; // 核心线程数int maxPoolSize = 4; // 最大线程数long keepAliveTime = 10; // 线程空闲时间TimeUnit unit = TimeUnit.SECONDS; // 时间单位BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(10); // 任务队列ThreadFactory threadFactory = Executors.defaultThreadFactory(); // 线程工厂RejectedExecutionHandler handler = new ThreadPoolExecutor.AbortPolicy(); // 拒绝策略// 创建ThreadPoolExecutor对象ThreadPoolExecutor threadPool = new ThreadPoolExecutor(corePoolSize,maxPoolSize,keepAliveTime,unit,workQueue,threadFactory,handler);return threadPool;}
}4. 线程池参数的选择原则
仅供参考:具体的线程池参数,需要根据业务场景,进行合理的测试选择
一般原则:
在使用java.util.concurrent.ThreadPoolExecutor自定义线程池时,参数的设置需要根据具体的业务场景和需求进行调整。以下是一些常用的业务场景和设置原则:
-
短时任务场景:
corePoolSize (n+1):可以设置较小的值,例如CPU核心数加1。
maximumPoolSize (2n):根据系统负载情况和任务的短时性来设置。通常可以设置为核心线程数的两倍或者根据系统资源进行调整。
workQueue:可以选择容量较小的队列,例如SynchronousQueue,以避免任务积压。 -
长时任务场景:
corePoolSize:可以设置为一个相对较大的值,以确保有足够的线程处理任务。
maximumPoolSize:根据系统负载和任务的长时性来设置。如果长时任务较多,可以将最大线程数设置得较大一些。
keepAliveTime 和 TimeUnit:根据任务的处理时长和系统的响应时间来设置空闲线程的存活时间。 -
I/O密集型任务场景:
corePoolSize(2n):可以设置为较大的值,以充分利用系统资源,加速I/O操作。
maximumPoolSize:根据系统负载和I/O操作的并发数来设置,可以设置得比较大以应对高并发的情况。
workQueue:可以选择一个适当大小的队列,以充分缓冲I/O任务,但不至于占用过多内存。 -
CPU密集型任务场景:
corePoolSize:可以根据CPU核心数设置,以充分利用系统的多核处理能力。
maximumPoolSize:可以设置得比较大,以应对突发的CPU密集型任务,但不要超过系统负载的承受范围。
workQueue:选择一个合适大小的队列来缓冲任务,避免因任务积压导致性能下降。
设置原则:
要根据具体的业务需求和系统特点来选择参数。
要根据实际情况进行监控和调优,以确保线程池能够有效地处理任务并保持系统的稳定性和性能。
要平衡资源的利用和系统的响应能力,避免设置过大或过小的参数,导致资源浪费或性能问题。