from_pretrained 做了啥
transformers的三个核心抽象类是Config, Tokenizer和Model,这些类根据模型种类的不同,派生出一系列的子类。构造这些派生类的对象也很简单,transformers为这三个类都提供了自动类型,即AutoConfig, AutoTokenizer和AutoModel。三个AutoClass都提供了from_pretrained方法,这个方法则一气完成了模型类别推理、模型文件列表映射、模型文件下载及缓存、类对象构建等一系列操作。
from_pretrained这个类方法,最重要的一个参数叫做pretrained_model_name_or_path。顾名思义,我们可以给出一个模型的短名,也可以给出一个路径。如果给的是模型短名,则它会想办法映射出要下载的文件的URL位置,并将文件下载到本地一个固定的cache目录。第二次再调用的时候,它会检查cache中是否已经存在同样的文件,如果有则直接从cache载入,不再走网络下载。如果给的是路径名,那么它假设该路径之下已经存在自行训练/预下载/经过微调的模型文件,直接载入。
from_pretrained方法实际上提供了丰富的下载辅助功能,
- cache_dir:自定义的cache路径
- force_download:强制重新下载
- resume_download:断点续传
- proxies:字典形式指定代理
- ……
AutoConfig.from_pretrained
Config的初次构造相对简单,主要是通过hf_bucket_url函数将函数短名映射成为网络URL,形如'https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-config.json'的一个json文件。下载它到cache目录,再读取构造对象即可。
AutoTokenizer.from_pretrained
Tokenizer初次构造要复杂一点。
- 首先它需要先构造Config对象,然后查一张预定义好的表TOKENIZER_MAPPING。这张映射表中,描述了什么样的Config Class对应什么样的Tokenizer Class。
- 每个Tokenizer Class都定义了一个类变量vocab_files_names,指定了它所用到的词汇文件名有哪些。
- 另外Tokenizer Class可能还会产生若干附加文件,可能有也可能没有,但这些附加文件名列表是有限的,存在additional_files当中,包括ADDED_TOKENS_FILE, SPECIAL_TOKENS_MAP_FILE, TOKENIZER_CONFIG_FILE, FULL_TOKENIZER_FILE等,后续下载时需要逐一探测一下。
- 以上所有的文件名,都需要用hf_bucket_url函数转成相应的URL。
AutoModel.from_pretrained
Model的构造也相对简单。
- 和Tokenizer类似,它也需要先得到Config对象,然后查MODEL_MAPPING映射表,得到实际的Model Class。
- Model Class定义了类方法from_pretrained。这个方法会根据模型短名以及该模型是从TF还是PT训练的,利用hf_bucket_url函数转成相应的URL。TF2对应的模型文件名为tf_model.h5,PT对应的模型文件名为pytorch_model.bin。由于模型文件一般比较大,转换时采用了CDN域名,下载时采用了分块下载stream的方式。
以 vicuna-7b-v1.5为例
https://huggingface.co/lmsys/vicuna-7b-v1.5/tree/main
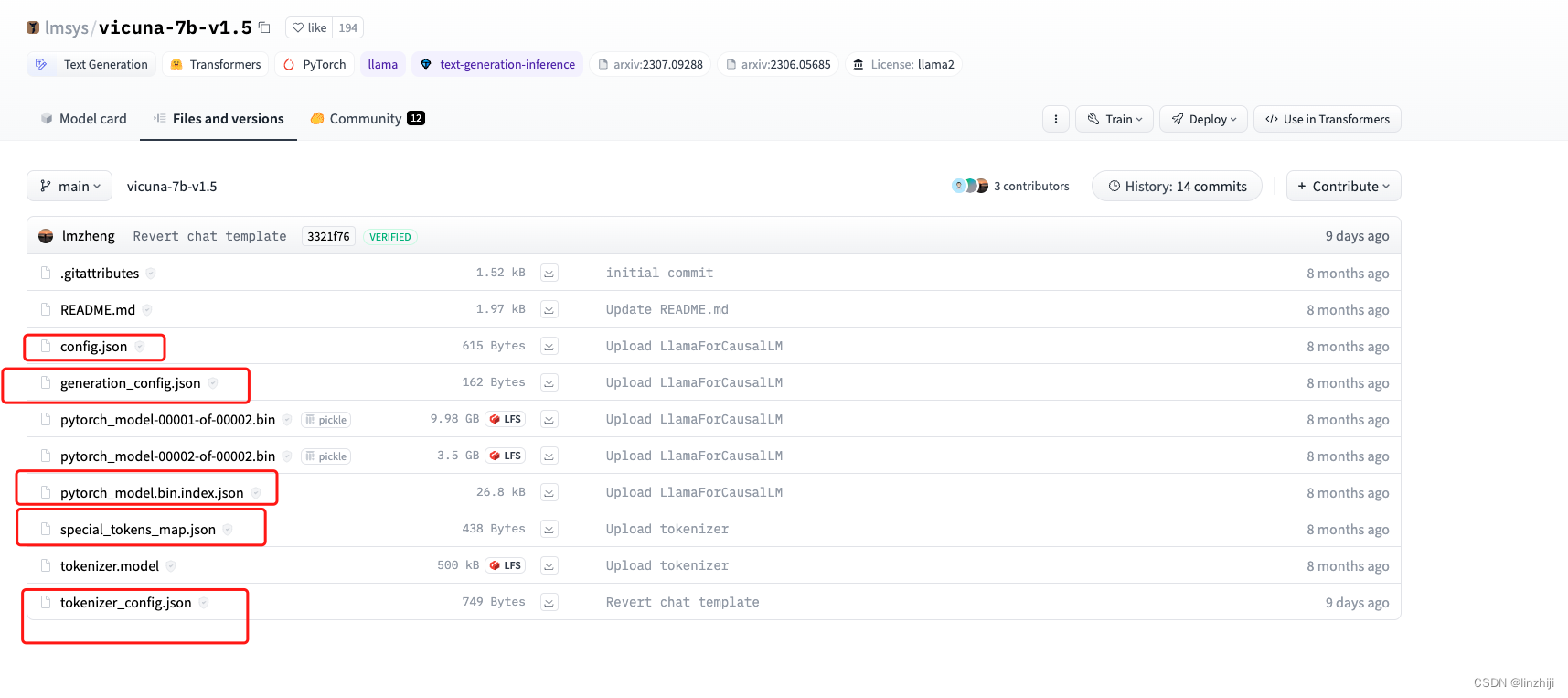
其中 config.json
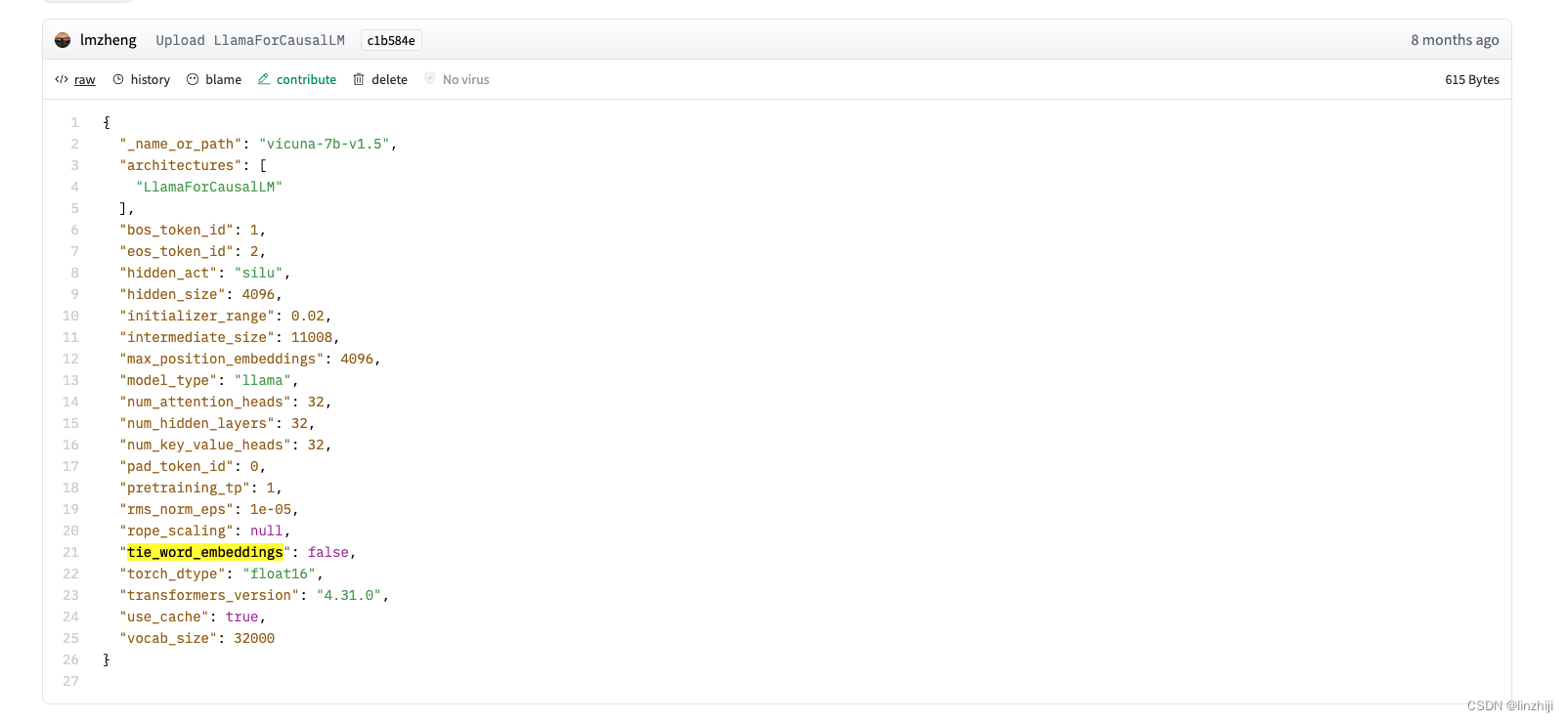
是模型model的 Configuration ,文档https://huggingface.co/transformers/v3.3.1/main_classes/configuration.html
其他
a config.json file, which saves the configuration of your model ;
a pytorch_model.bin file, which is the PyTorch checkpoint (unless you can’t have it for some reason) ;
a tf_model.h5 file, which is the TensorFlow checkpoint (unless you can’t have it for some reason) ;
a special_tokens_map.json, which is part of your tokenizer save;
a tokenizer_config.json, which is part of your tokenizer save;
files named vocab.json, vocab.txt, merges.txt, or similar, which contain the vocabulary of your tokenizer, part of your tokenizer save;
maybe a added_tokens.json, which is part of your tokenizer save.
https://huggingface.co/transformers/v3.3.1/model_sharing.html
参考
【HugBert05】照猫画虎:理解from_pretrained,攒个模型下载器 - 知乎