语音转文字——sherpa ncnn语音识别离线部署C++实现
简介
Sherpa是一个中文语音识别的项目,使用了PyTorch 进行语音识别模型的训练,然后训练好的模型导出成 torchscript 格式,以便在 C++ 环境中进行推理。尽管 PyTorch 在 CPU 和 GPU 上有良好的支持,但它可能对资源的要求较高,不太适合嵌入式环境或要求轻量级依赖的场景。
考虑到模型是使用 PyTorch 训练的,则优先选择 ONNX 格式的推理框架。虽然 PyTorch 提供了对 ONNX 的支持,但并不是所有的 PyTorch 算子都可以无缝地转换为 ONNX 格式。为了考虑多平台的支持,这里选择了 ncnn 推理框架。ncnn 提供了 PNNX 模型转换工具,可以将 PyTorch 模型转换为 ncnn 支持的格式。ncnn 和 PNNX 的代码可读性和可扩展性都很好,当遇到不支持的算子时,可以方便地扩展 ncnn 和 PNNX。
此外,尽管 ncnn 开源已有 5 年时间,但其开发者社区仍然非常活跃,并且持续更新和维护。因此,当遇到问题时,可以轻松地获取帮助。
项目地址:https://github.com/k2-fsa
项目流程
-
训练模型:使用 PyTorch 进行语音识别模型的训练。确保模型在训练集上表现良好,并且经过充分的验证和调优。
-
导出模型:将 PyTorch 模型导出为 ONNX 格式。这可以通过 PyTorch 提供的内置函数实现。但要注意,不是所有的 PyTorch 算子都能无缝地转换为 ONNX 格式,因此可能需要一些额外的工作来处理不受支持的算子。
-
转换为 ncnn 格式:使用 PNNX 模型转换工具,将 ONNX 格式的模型转换为 ncnn 支持的格式。确保在转换过程中模型的性能和准确率不受影响。
-
部署到 Sherpa:在 Sherpa 中部署转换后的 ncnn 模型。这可能需要一些 C++ 编程来集成模型并构建语音识别应用程序。确保在部署过程中考虑到性能、内存占用等因素。
-
扩展和优化:如果在转换模型或部署过程中遇到问题,可以利用 ncnn 和 PNNX 的可扩展性和活跃的开发者社区来解决。可能需要扩展 ncnn 或 PNNX 来处理不支持的算子或优化性能。
源码实现
C++调用代码:
#include <stdio.h>
#include <algorithm>
#include <chrono>
#include <iostream>#include <ncnn/net.h>
#include <sherpa-ncnn/csrc/recognizer.h>
#include <sherpa-ncnn/csrc/wave-reader.h>extern std::string WideByteToAcsi(std::wstring &wstrcode)
{int asciisize = ::WideCharToMultiByte(CP_OEMCP, 0, wstrcode.c_str(), -1, NULL,0, NULL, NULL);if (asciisize == ERROR_NO_UNICODE_TRANSLATION) {throw std::exception("Invalid UTF-8 sequence.");}if (asciisize == 0) {throw std::exception("Error in conversion.");}std::vector<char> resultstring(asciisize);int convresult =::WideCharToMultiByte(CP_OEMCP, 0, wstrcode.c_str(), -1, &resultstring[0],asciisize, NULL, NULL);if (convresult != asciisize) {throw std::exception("La falla!");}return std::string(&resultstring[0]);
}extern std::wstring Utf8ToUnicode(const std::string &utf8string)
{int widesize =::MultiByteToWideChar(CP_UTF8, 0, utf8string.c_str(), -1, NULL, 0);if (widesize == ERROR_NO_UNICODE_TRANSLATION) {throw std::exception("Invalid UTF-8 sequence.");}if (widesize == 0) {throw std::exception("Error in conversion.");}std::vector<wchar_t> resultstring(widesize);int convresult = ::MultiByteToWideChar(CP_UTF8, 0, utf8string.c_str(), -1,&resultstring[0], widesize);if (convresult != widesize) {throw std::exception("La falla!");}return std::wstring(&resultstring[0]);
}extern std::string UTF8ToASCII(std::string &strUtf8Code)
{std::string strRet("");std::wstring wstr = Utf8ToUnicode(strUtf8Code);strRet = WideByteToAcsi(wstr);return strRet;
}int main()
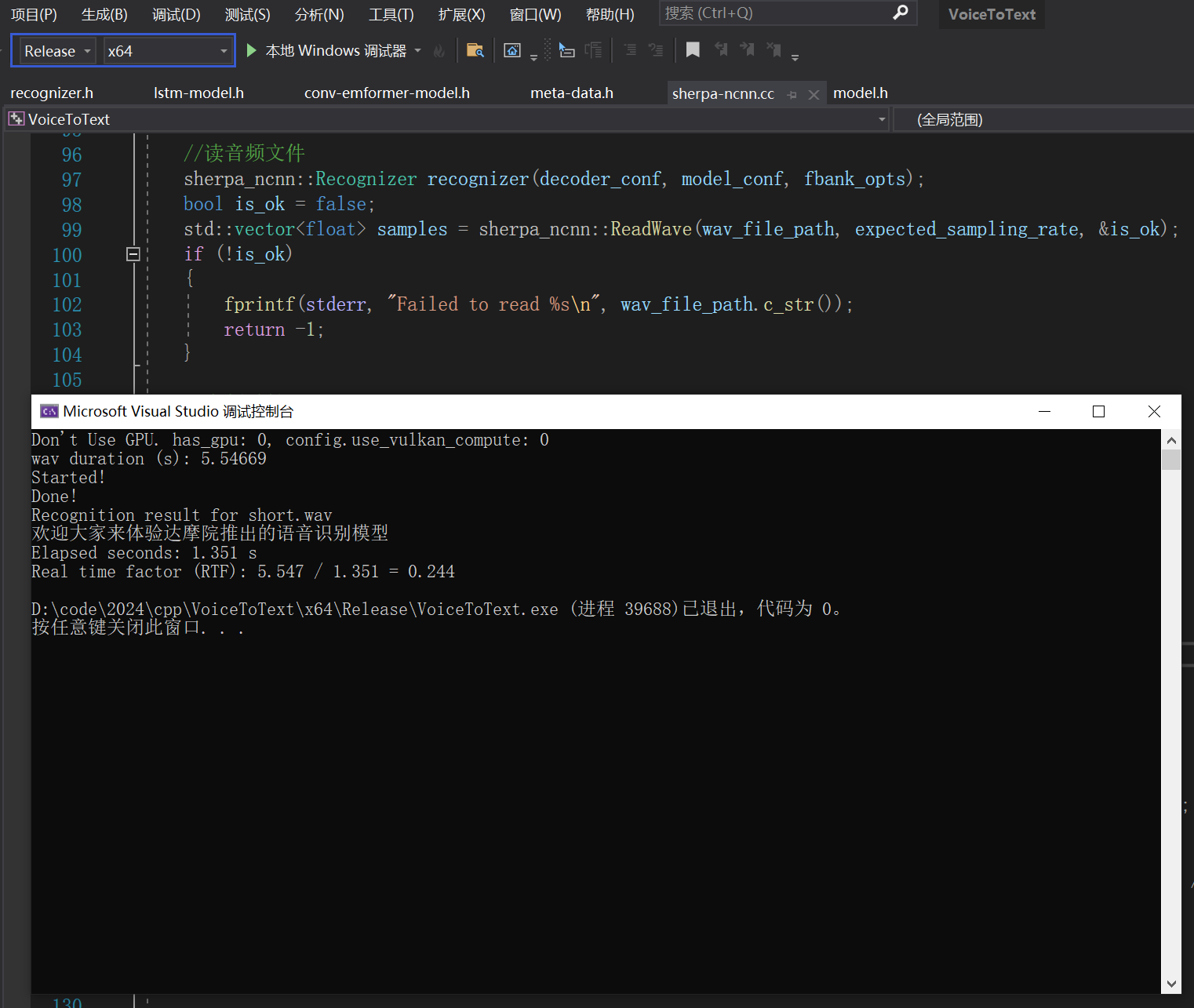
{std::string wav_file_path = "short.wav";//初始化模型sherpa_ncnn::ModelConfig model_conf;model_conf.tokens = "models/tokens.txt";model_conf.encoder_param = "models/encoder_jit_trace.param";model_conf.encoder_bin = "models/encoder_jit_trace.bin";model_conf.decoder_param = "models/decoder_jit_trace.param";model_conf.decoder_bin = "models/decoder_jit_trace.bin";model_conf.joiner_param = "models/joiner_jit_trace.param";model_conf.joiner_bin = "models/joiner_jit_trace.bin";//线程int32_t num_threads = 4;model_conf.encoder_opt.num_threads = num_threads;model_conf.decoder_opt.num_threads = num_threads;model_conf.joiner_opt.num_threads = num_threads;float expected_sampling_rate = 16000;sherpa_ncnn::DecoderConfig decoder_conf;knf::FbankOptions fbank_opts;fbank_opts.frame_opts.dither = 0;fbank_opts.frame_opts.snip_edges = false;fbank_opts.frame_opts.samp_freq = expected_sampling_rate;fbank_opts.mel_opts.num_bins = 80;//读音频文件sherpa_ncnn::Recognizer recognizer(decoder_conf, model_conf, fbank_opts);bool is_ok = false;std::vector<float> samples = sherpa_ncnn::ReadWave(wav_file_path, expected_sampling_rate, &is_ok);if (!is_ok) {fprintf(stderr, "Failed to read %s\n", wav_file_path.c_str());return -1;}//音频时长const float duration = samples.size() / expected_sampling_rate;std::cout << "wav duration (s): " << duration << "\n";//开始推理auto begin = std::chrono::steady_clock::now();std::cout << "Started!\n";recognizer.AcceptWaveform(expected_sampling_rate, samples.data(),samples.size());std::vector<float> tail_paddings(static_cast<int>(0.3 * expected_sampling_rate));recognizer.AcceptWaveform(expected_sampling_rate, tail_paddings.data(),tail_paddings.size());recognizer.Decode();auto result = recognizer.GetResult();std::cout << "Done!\n";std::cout << "Recognition result for " << wav_file_path << "\n"<< UTF8ToASCII(result.text) << "\n";auto end = std::chrono::steady_clock::now();float elapsed_seconds = std::chrono::duration_cast<std::chrono::milliseconds>(end - begin).count() /1000.0;printf("Elapsed seconds: %.3f s\n", elapsed_seconds);float rtf = elapsed_seconds / duration;printf("Real time factor (RTF): %.3f / %.3f = %.3f\n", duration,elapsed_seconds, rtf);return 0;
}源码下载地址:https://download.csdn.net/download/matt45m/89002001?spm=1001.2014.3001.5503
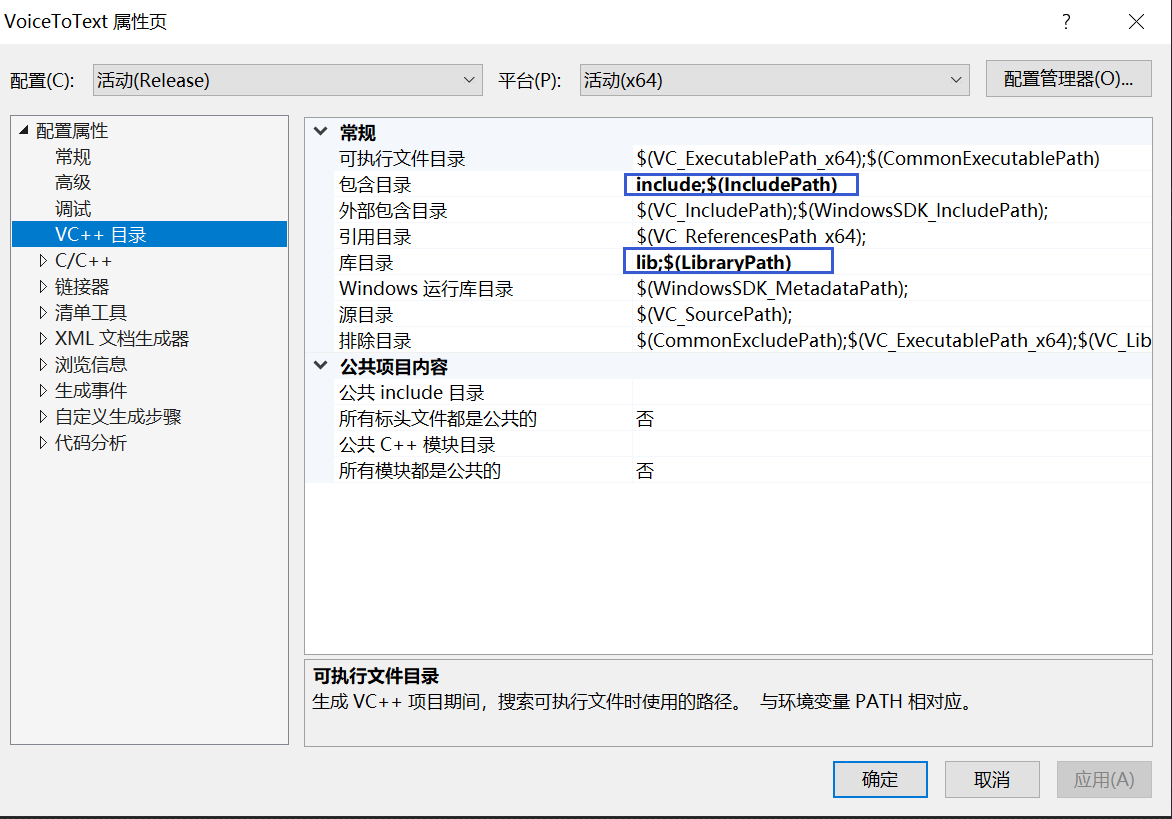
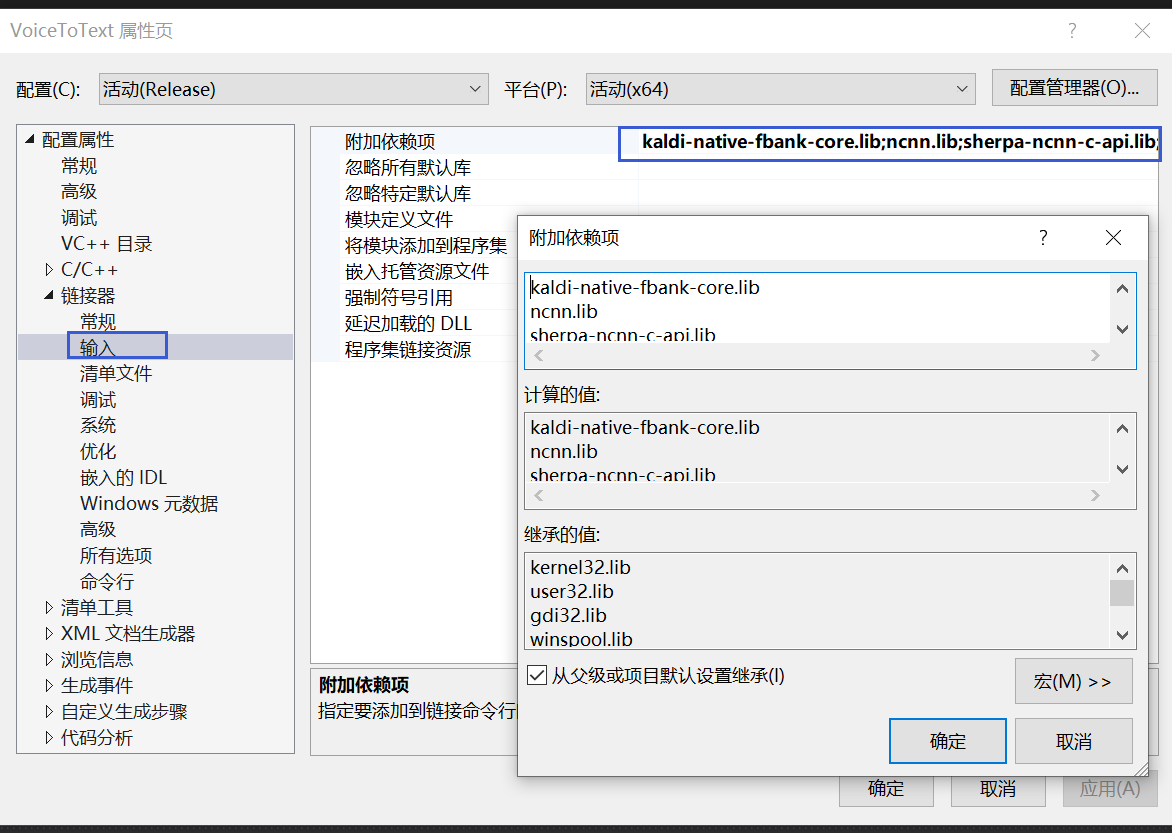
下载之后,配置include和lib路径: