「数据分析」之零基础入门数据挖掘
摘要:对于数据挖掘项目,本文将学习应该从哪些角度分析数据?如何对数据进行整体把握,如何处理异常值与缺失值,从哪些维度进行特征及预测值分析?
探索性数据分析(Exploratory Data Analysis,EDA)是指对已有数据在尽量少的先验假设下通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。
数据及背景
https://tianchi.aliyun.com/competition/entrance/231784/information(阿里天池-零基础入门数据挖掘)
EDA的目标
-
熟悉数据集,了解数据集,对数据集进行验证来确定所获得数据集可以用于接下来的机器学习或者深度学习使用。
-
了解变量间的相互关系以及变量与预测值之间的存在关系。
-
引导数据科学从业者进行数据处理以及特征工程的步骤,使数据集的结构和特征集让接下来的预测问题更加可靠。
数据载入及总览
载入各种数据科学以及可视化库
missingno库用于可视化缺失值分布,是基于matplotlib的,接受pandas数据源
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport missingno as msno # 用于可视化缺失值分布import scipy.stats as st载入数据
path = './data/'Train_data = pd.read_csv(path+'used_car_train_20200313.csv', sep=' ')Test_data = pd.read_csv(path+'used_car_testA_20200313.csv', sep=' ')所有特征集均脱敏处理,脱敏处理后均为label encoding形式,即数字形式

总览数据
简略观察数据head()+shape
Train_data.head().append(Train_data.tail())Test_data.head().append(Test_data.tail())Train_data.shapeTest_data.shapedescribe()熟悉相关统计量
describe()中包含每列的统计量,个数(count)、平均值(mean)、方差(std)、最小值(min)、中位数(25% 50% 75%)、最大值(max)等。通过观察以上指标,可以瞬间掌握数据的大概范围和每个值的异常值的判断 ,例如有时候会发现999 9999、 -1 等值这些其实都是nan的另外一种表达方式。
Train_data.describe()
info()熟悉数据类型
通过info()来了解数据每列的type,有助于了解是否存在除了nan以外的特殊符号异常。
Train_data.info()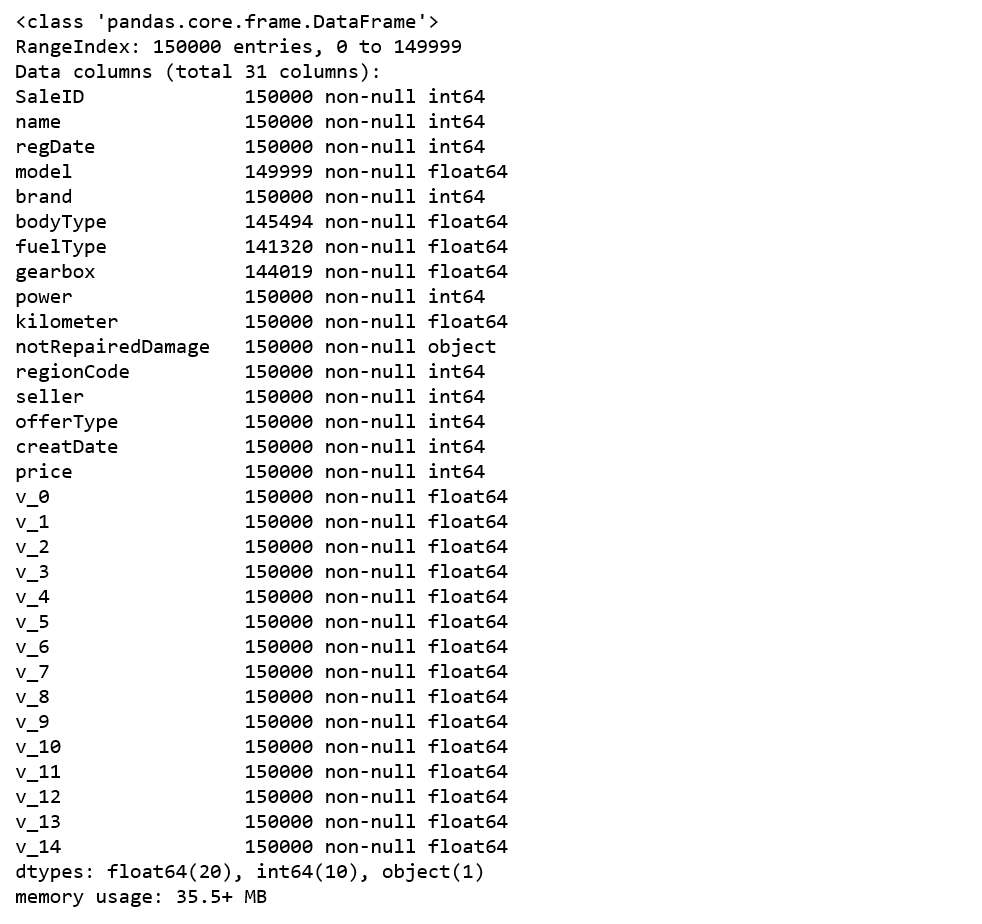
缺失值和异常值
缺失值
查看每列的存在nan情况
Train_data.isnull().sum()Test_data.isnull().sum()
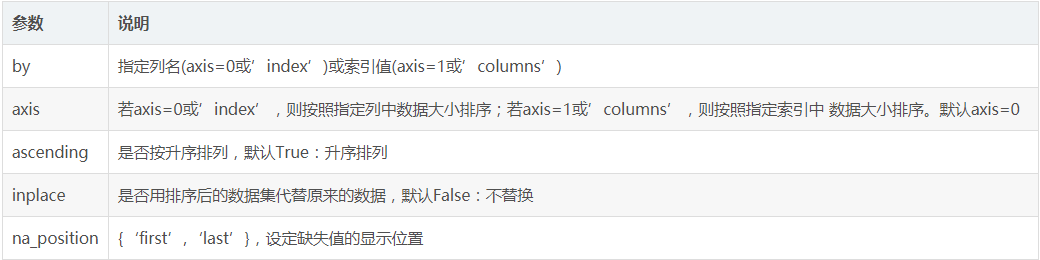
排序函数sort_values()
可以将数据集依照某个字段中的数据进行排序,该函数即可根据指定列数据也可根据指定行的
通过以下两句可以很直观的了解哪些列存在 “nan”, 并可以把nan的个数打印。主要的目的在于 nan存在的个数是否真的很大,如果很小一般选择填充,如果使用lgb等树模型可以直接空缺,让树自己去优化,但如果nan存在的过多、可以考虑删掉。
# nan可视化missing = Train_data.isnull().sum()missing = missing[missing > 0]missing.sort_values(inplace=True)missing.plot.bar()
# 可视化缺省值msno.matrix(Train_data.sample(250))msno.bar(Train_data.sample(1000))msno.matrix(Test_data.sample(250))msno.bar(Test_data.sample(1000))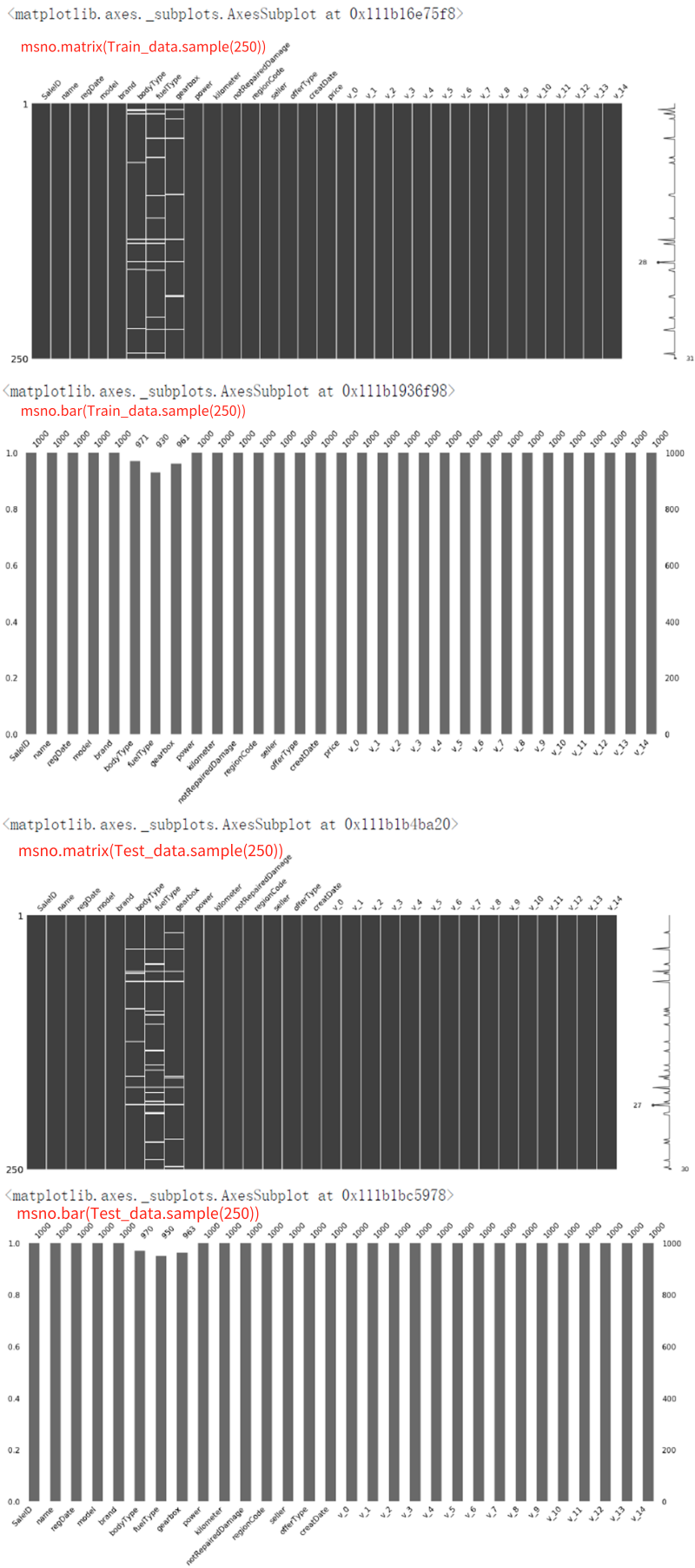
从上文Train_data.info()的统计信息可以发现,除了notRepairedDamage 为object类型其他都为数字。接下来将notRepairedDamage中几个不同的值都进行显示如下:
Train_data['notRepairedDamage'].value_counts()
可以看出‘ - ’也为空缺值,因为很多模型对nan有直接的处理,这里我们先不做处理,先替换成nan。
Train_data['notRepairedDamage'].replace('-', np.nan, inplace=True)Train_data['notRepairedDamage'].value_counts()
Train_data.isnull().sum()