R语言数据挖掘-关联规则挖掘(1)
一、分析目的和数据集描述
要分析的数据是美国一区域的保险费支出的历史数据。保险费用数据表的每列分别为年龄、性别、体重指数、孩子数量、是否吸烟、所在区域、保险收费。
本文的主要目的是分析在年龄、性别、体重指数、孩子数量、是否吸烟、所在区域中这些因素中,哪些因素对保险费支出影响最大,这些因素中哪些因素与保险费用的关联最大。
分析影响保险费支出的具体因素,本文用到了R语言的数据挖掘-关联规则挖掘Apriori算法。
具体使用和详细用法如下:
二、导入数据集
df<-read.csv('f:/桌面/insurance.csv')
head(df)
head(df)age sex bmi children smoker region charges 1 19 female 27.90 0 yes southwest 16885 2 18 male 33.77 1 no southeast 1726 3 28 male 33.00 3 no southeast 4449 4 33 male 22.70 0 no northwest 21984 5 32 male 28.88 0 no northwest 3867 6 31 female 25.74 0 no southeast 3757
三、导入关联规则挖掘用到的分析程序包
library(arules) #用于数据关联规则挖掘
library(arulesViz) #关联规则挖掘的可视化程序包
library(dplyr) #用于数据处理的分析包,我们将使用里面的管道函数%>%
library(ggplot2)
四、查看数据集
summary(df)
查看体重指数的分布情况,使用直方图:
ggplot(df,aes(x=bmi))+
geom_histogram(binwidth=5,fill='lightblue',colour='black')
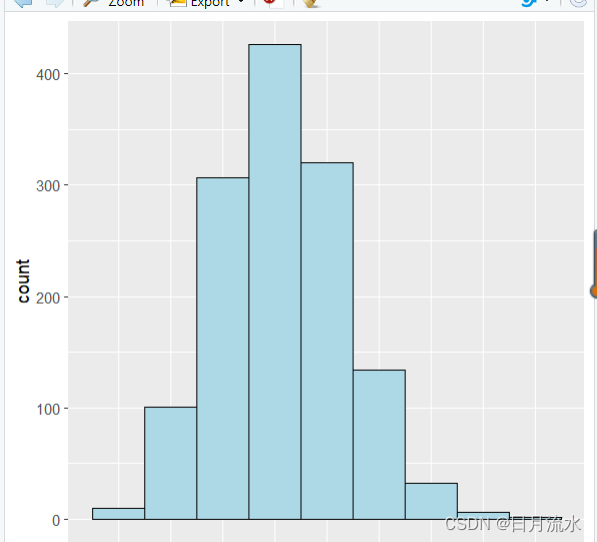
因为要分析的数据集无缺失值,下一步就是要对数据各变量转换为因子型,也是是规则关联函数
apriori()要求的。
五、将数据集的变量转换为因子型
df<-df %>% mutate(age=as.factor(cut(age,breaks = c(0,25,50,75,100)))) %>%
mutate(sex=as.factor(sex)) %>% mutate(bmi=as.factor(cut(bmi,breaks = c(0,15,30,45,60,75)))) %>%
mutate(children=as.factor(children)) %>% mutate(smoker=as.factor(smoker)) %>%
mutate(region=as.factor(region)) %>% mutate(charges=as.factor(cut(charges,breaks = c(0,13000,26000,39000,65000))))
在这里用到了管道函数,对年龄、健康指数、保险费用按区间分组,把年龄分为4组,健康指数分为5组,保险费支出分为了4组,然后对分组后的变量使用as.factor()转换为因子型变量。
六、对保险费用数据集进行关联分析
rules<-apriori(df,parameter = list(supp=0.1,conf=0.8))
summary(rules)

运行得到了各规则的描述性统计量,共生成了80条规则。支持度为0.1,置信度为0.8.
查看关联分析结果:
options(digits=4)
inspect(head(rules,by='lift'))

运行得到了按提升值排序后的6条规则。
例如第一条年龄在0到25岁之间,无小孩,不吸烟的家庭关联最低程度的保险费用支出的支持度为0.1121,置信度94.34%。
关联规则分析可视化

plot(rules)
七、指定后项集的关联挖掘分析
1、后项集指定为保险费用支出charges=(39000,65000],即分析关联最高级别的保险费用支出的影响因素有哪些。
rules_rhs_highrank<-apriori(df,parameter = list(supp=0.02,conf=0.5),
appearance = list(rhs=c('charges=(3.9e+04,6.5e+04]')),control=list(verbose=F))
inspect(head(rules_rhs_highrank,by='lift'))
查看分析结果:
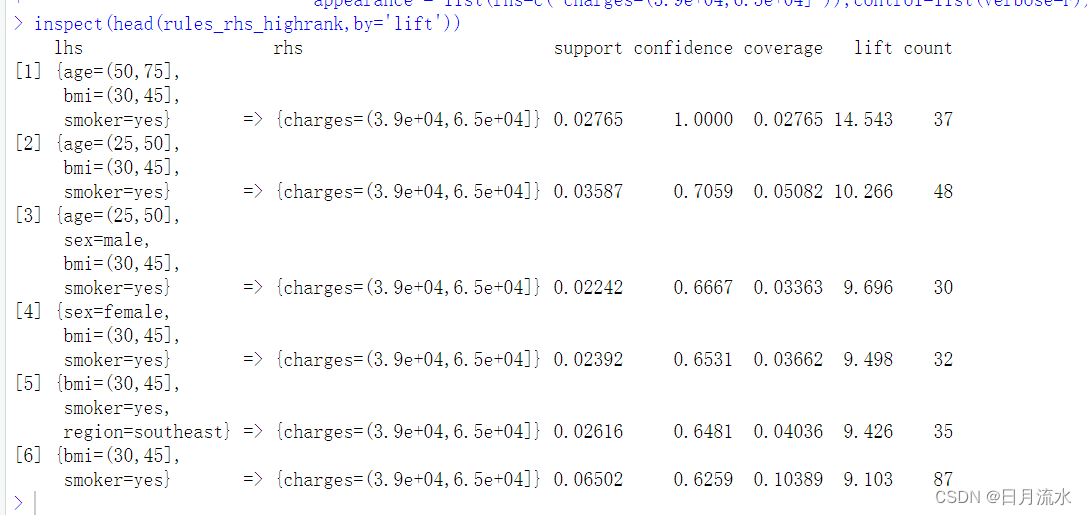
从运行结果可以看到:年龄较大,体重较重,吸烟等因素与保险费用支出较高支持相关联。
inspect(head(rules_rhs_highrank[!is.redundant(rules_rhs_highrank)],by='lift'))
去除规则冗余后的结果如下:

2、后项集指定为保险费用支出charges=(0,13000],即分析关联最低级别的保险费用支出的影响因素有哪些。
rules_rhs_lowrank<-apriori(df,parameter = list(supp=0.1,conf=0.5),
appearance = list(rhs=c('charges=(0,1.3e+04]')),control=list(verbose=F))
inspect(head(rules_rhs_lowrank,by='lift'))
运行得到:

从结果可以看到,年龄较小,无孩子,不吸烟,是女性的保险费用支出较少。