[数据结构与算法(严蔚敏 C语言第二版)]第1章 绪论(学习复习笔记)
1.1 数据结构的研究内容
- 计算机解决问题的步骤
- 从具体问题抽象出数学模型
- 设计一个解此数学模型的算法
- 编写程序,进行测试、调试,直到解决问题
- 计算机解决问题的过程中寻求数学模型的实质是
- 分析问题,从中提取操作的对象,并找出这些操作对象之间的关系
- 操作对象与操作对象之间的关系,就是数据结构
- 用数学语言加以描述,即建立相应的数学方程
- 分析问题,从中提取操作的对象,并找出这些操作对象之间的关系
- 数据结构主要研究非数值计算问题,非数值计算问题无法用数学方程建立数学模型
- 数据结构是一门研究非数值计算程序设计中的操作对象(如表、树、图),以及这些对象之间的关系和操作的学科
1.2 基本概念和术语
1.2.1 数据、数据元素、数据项和数据对象
- 数据(Data)
- 是客观事物的符号表示,是所有能输人到计算机中并被计算机程序处理的符号的总称。
- 数据是信息的载体,能够被计算机识别、存储和加工
- 数据包括数值型数据(如整数、实数)和非数值型数据(如文字、图)
- 数据元素(Data Element)
- 是数据的基本单位,在计算机中通常作为一个整体进行考虑和处理。
- 某些情况下,数据元素也称为元素、记录、节点、顶点。
- 数据元素用于完整地描述一个对象,如学生表中的一名学生记录
- 一个数据元素由若干个数据项组成
- 数据项(Data ltem)
- 是组成数据元素的、有独立含义的、不可分割的最小单位。
- 例如,学生基本信息中的学号、姓名、性别等都是数据项。
- 数据对象(Data Object)
- 是性质相同的数据元素的集合,是数据的一个子集。
- 例如,学生基本信息表中的一些学生记录是一个数据对象。
- 数据、数据元素、数据项之间的关系
- 数据 > 数据元素 > 数据项
- 数据元素与数据对象
- 数据元素
- 组成数据的基本单位
- 与数据的关系:集合的个体
- 数据对象
- 性质相同的数据元素的集合
- 与数据的关系:集合的子集
- 数据元素
1.2.2 数据结构
- 数据结构是相互之间存在一种或多种特定关系的数据元素的集合
- 数据结构是带“结构”的数据元素的集合
- “结构”是指数据元素之间存在的关系
- 数据结构包括逻辑结构和存储结构
- 逻辑结构
- 数据元素之间的逻辑关系
- 数据的逻辑结构是从逻辑关系上描述数据,与数据的存储无关,是独立于计算机的,是从具体问题抽象出来的数学模型
- 存储结构
- 数据元素及其关系在计算机内存中的表示(又称映像、存储方式)
- 数据对象在计算机中的存储表示称为数据的存储结构,也称为物理结构
- 既要存储各数据元素的数据,又要存储数据元素之间的逻辑关系
- 逻辑结构
- 逻辑结构种类的划分
- 将逻辑结构划分为线性结构和非线性结构
- 线性结构:有且仅有一个开始和一个终端节点,并且所有节点都最多只有一个直接前趋和一个直接后继
- 如:线性表、栈、队列
- 非线性结构:一个节点可能有多个直接前趋或多个直接后继
- 如:树、图
- 线性结构:有且仅有一个开始和一个终端节点,并且所有节点都最多只有一个直接前趋和一个直接后继
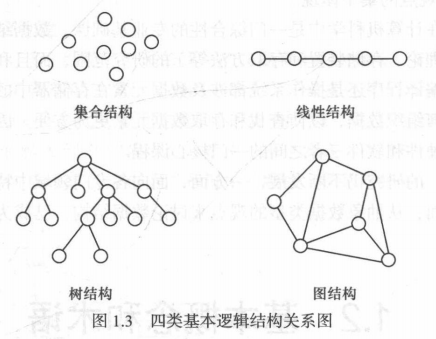
- 将逻辑结构划分为四种基本的逻辑结构
- 集合结构:数据元素之间除了“属于同一个集合”的关系外,别无其他关系
- 线性结构:数据元素之间存在一对一的关系
- 树结构:数据元素之间存在一对多的关系
- 图结构或网状结构:数据元素之间存在多对多的关系
- 其中集合结构、树结构、图结构数据非线性结构
- 将逻辑结构划分为线性结构和非线性结构
- 逻辑结构种类的划分
- 顺序存储结构
- 顺序存储结构是借助元素在存储器种的相对位置来表示数据元素之间的逻辑关系,通常借助程序设计语言的数组类型来描述
- 顺序存储结构要求所有的元素依次存放在一片连续的存储空间中
- 链式存储结构
- 用一组任意的存储单元存储数据元素,数据元素之间的逻辑关系使用指针来表示
- 链式存储结构通常借助于程序设计语言的指针类型来描述
- 索引存储结构
- 在存储节点信息的同时,建立附加的索引表(可以加快查询速度)
- 散列存储结构
- 根据节点的关键字直接计算出该节点的存储地址
- 顺序存储结构
- 逻辑结构和存储结构的关系
- 存储结构是逻辑关系的映像于元素本身的映像
- 逻辑结构是数据结构的抽象,存储结构是数据结构的实现
- 逻辑结构与存储结构综合起来建立了数据元素之间的结构关系
1.2.3 数据类型和抽象数据类型
- 数据类型
- 是一组性质相同的值的集合和定义在这个值集上的一组操作的总称
- 数据类型隐含地规定了数据的取值范围、存储方式以及允许进行的运算
- 数据类型 = 值得集合 + 值集合上得一组操作
- 抽象数据类型
- 抽象就是抽取出实际问题得本质
- 抽象数据类型是指一个数学模型以及定义在此数学模型上得一组操作的总称,不考虑计算机内的具体存储结构和运算的具体实现算法
- 数学模型:由用户定义的、表示应用问题的数学模型
- 抽象数据类型具体包括:数据对象、数据对象上关系的集合、数据对象的基本操作的集合
- 抽象数据类型的形式化定义
- 抽象数据类型可用(D,S,P)三元组表示
- D:数据对象
- S:数据对象上的关系集
- P:对数据对象的基本操作集
- 抽象数据类型可用(D,S,P)三元组表示
- 抽象数据类型的定义格式
-
ADT 抽象数据类型名 {数据对象:<数据对象的定义>数据关系:<数据关系的定义>基本操作:<基本操作的定义> } ADT 抽象数据类型名 - 数据对象和数据关系的定义采用数学符号和自然语言描述
- 基本操作的定义格式
-
基本操作名(参数表)初始条件:<初始条件描述>操作结果:<操作结果描述> - 操作结果的两种参数
- 赋值参数:为操作提供输入值
- 引用参数:以
&开头,除了可以提供输入值外,还可返回操作结果
- 初始条件:描述了操作执行之前数据结构和参数应该满足的条件,若不满足,则操作失败,并返回相应出错信息,若初始条件为空则省略
- 操作结果:说明了操作正常完成之后,数据结构的变化状况和应该返回的结果
-
-
- 抽象数据类型的定义举例
- Circle的定义
-
ADT Circle {数据对象:D = {r,x,y | r,x,y 均为实数}数据关系:R = {<r,x,y> | r 是半径,<x,y> 是圆心坐标}基本操作:Circle(&C,r,x,y)操作结果:构造一个圆double Area(C)初始条件:圆存在操作结果:计算面积double Circumference(C)初始条件:圆存在操作结果:计算周长 } ADT Circle
1.3 抽象数据类型的表示与实现
- 抽象数据类型可以通过固有的数据类型来表示实现,即利用处理器中已经存在的数据类型来说明新的结构,用已经实现的操作来组合新的操作
- 使用类C语言作为抽象数据类型的表示与实现的描述工具
- 以复数为例
- 抽象数据类型的定义
-
ADT Complex {数据对象:D={e1,e2| e1,e2∈R,R是实数集}数据关系:S={<e1,e2>le1是复数的实部,e2是复数的虚部}基本操作:Creat ( &C, x, y )操作结果:构造复数C,其实部和虚部分别被赋以参数x和y的值。GetReal(C)初始条件:复数C已存在。操作结果:返回复数C的实部值。GetImag(C)初始条件:复数C已存在。操作结果:返回复数C的虚部值。Add(c1,c2)初始条件:c1,c2是复数。操作结果:返回两个复数c1和C2的和。Sub(c1,c2)初始条件:c1,c2是复数。操作结果:返回两个复数c1和 c2的差。 }ADT Complex
-
- 抽象数据类型的表示部分(类C语言)
-
typedef struct // 复数类型 {float Realpart // 实部float Imagepart // 虚部 }Complex;
-
- 抽象数据类型的实现部分(类C语言)
-
void Create( &Complex C,float x,float y){ //构造一个复数C.Realpart=x;C.Imagepart=y;}float GetReal (Complex C){ //取复数C=x+yi的实部return C.Realpart;}float GetImag (Complex C){ //取复数C=x+yi的虚部return C.Imagepart ;}Complex Add (Complex C1,Complex C2){ //求两个复数C1和C2的和sumComplex sum;sum.Realpart=C1.Realpart +C2.Realpart ;sum.Imagepart=C1.Imagepart +C2.Imagepart;return sum;}Complex Sub (Complex C1, Complex C2){ //求两个复数C1和C2的差differenceComplex difference;difference.Realpart=C1.Realpart-C2.Realpart;difference.Imagepart=C1.Imagepart-C2.Imagepart;return difference;}
-
- 抽象数据类型的定义
1.4 算法和算法分析
1.4.1 算法的定义及特性
- 算法:
- 对特定问题求解方法和步骤的一种描述,它是指令的有限序列,其中每个指令表示一个或多个操作
- 算法就是解决问题的方法和步骤
- 算法的描述方法:
- 自然语言描述
- 流程图
- 伪代码、类语言
- 程序代码
- 算法与程序
- 算法
- 是解决问题的一种方法或一个过程,考虑如何将输入转换为输出,一个问题可以有多种算法
- 程序
- 是用某种程序设计语言对算法的具体实现
- 程序 = 数据结构 + 算法
- 数据结构通过算法实现操作
- 算法根据数据结构设计程序
- 算法
- 算法的五个重要特性
- 有穷性:算法在执行有穷步之后结束,且每一步都必须在有穷步时间内完成
- 确定性:对于每种情况下所执行的操作,在算法中都有确切的规定,不会产生二义性,使算法的执行者和阅读者都能明确其含义及如何执行,对于相同的输入只能得到相同的输出
- 可行性:算法中的所有操作都可以通过已经实现的基本操作运算执行有限次来实现
- 输入:一个算法有0个或多个输入
- 输出:一个算法有一个或多个输出
1.4.2 评价算法优劣的基本标准
- 正确性
- 在合理的数据输入下,能够在有限的运行时间内得到正确的结果。
- 程序对于精心选择的、典型、苛刻且带有刁难的几组输入数据可以得出满足要求的结果
- 可读性
- 一个好的算法,首先应便于人们理解和相互交流,其次才是机器可执行性。
- 可读性强的算法有助于人们对算法的理解,而难懂的算法易于隐藏错误,且难于调试和修改。
- 健壮性
- 当输人的数据非法时,好的算法能适当地做出正确反应或进行相应处理,而不会产生一些莫名其妙的输出结果。
- 高效性
- 高效性包括时间和空间两个方面。
- 花费尽量少的时间和尽量低的存储需求
- 时间高效是指算法设计合理,执行效率高,可以用时间复杂度来度量
- 空间高效是指算法占用存储容量合理,可以用空间复杂度来度量。
- 时间复杂度和空间复杂度是衡量算法的两个主要指标。
1.4.3 算法的时间复杂度
- 算法效率分析的目的
- 看算法实际是否可行,并在同一问题存在多个算法时,可进行时间和空间性能上的比较,以便从中挑选出较优算法。
- 算法的效率从以下两个方面进行考虑
- 时间效率
- 指算法所耗费的时间
- 空间效率
- 指算法执行过程中所耗费的存储空间
- 时间效率与空间效率有时是矛盾的
- 时间效率
- 算法的时间效率可以依据该算法编写的程序在计算机上执行所消耗的时间来度量
- 衡量算法效率的方法主要有两类
- 事后统计法
- 事前分析估算法
- 事后统计法
- 需要先将算法实现,然后测算其时间和空间开销。
- 必须把算法转换成可执行的程序,耗费时间和精力;时空开销的测算结果依赖于计算机的软硬件等环境因素,这容易掩盖算法本身的优劣。
- 事前分析估算法
- 对算法所消耗资源的一种估算方法
- 通过计算算法的渐近复杂度来衡量算法的效率。
- 算法运行时间 = 一个简单操作所需的时间 X 简单操作的次数
- 也即算法中每条语句的执行时间之和
- 算法运行时间 = Σ(每条语句的执行次数 X 该语句执行一次所需的时间)
- 一条语句的重复执行次数称为语句频度
- 算法运行时间 = Σ(每条语句的频度 X 该语句执行一次所需的时间)
- 设每条语句执行一次所需的时间为单位时间,则一个算法的执行时间可用该算法中所有语句频度之和来度量
- 为了便于比较不同的算法的时间效率,仅比较算法的数量级,即只采用算法中基本语句的执行次数来度量算法的工作量
- 基本语句:算法中重复执行次数和算法的执行时间成正比的语句,对算法运行时间的贡献度最大,执行的次数最多
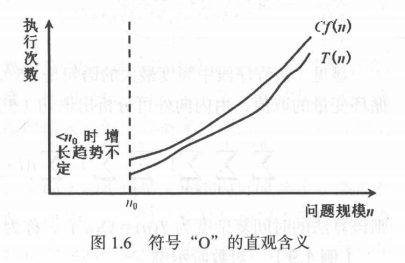
- 使用
O表示数量级,算法中基本语句重复执行的次数是问题规模n的某个函数f(n),算法的时间度量为T(n) = O(f(n)),表示随问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同,称作算法的渐渐时间复杂度,简称时间复杂度 - 例如,f(n)=2n3+3n2+2n+1f(n) = 2n^3 + 3n^2 + 2n + 1f(n)=2n3+3n2+2n+1,则T(n) = O(f(n)) = O(n3)
- 一般情况下,不必计算所有操作的执行次数,而只需考虑算法中基本操作执行的次数,它是问题规模n的某个函数,用T(n)表示
- 定理1.1
- 若f(n)=amnm+am−1nm−1+...+a1n+a0f(n) = a_mn^m + a_{m-1}n^{m-1} + ... + a_1n + a_0f(n)=amnm+am−1nm−1+...+a1n+a0是一个m次多项式,则T(n)=O(nm)T(n) = O(n^m)T(n)=O(nm)
- 在计算算法时间复杂度时,可用忽略所有低次幂项和最高次幂的系数,这样可以简化算法分析,也体现出增长率的含义
- 分析算法时间复杂度的基本方法
- 1.找出语句频度最大的那条语句作为基本语句
- 2.计算基本语句的频度得到问题规模n的某个函数f(n)
- 3.取其数量级用符号“O”表示
- 算法的时间复杂度分析举例
-
x = 1; for (i=1; i<=n; i++)for (j=1; j<=i; j++)for (k=1; k<=j; k++)x++;- ∑i=1n∑j=1i∑k=1j1\sum_{i=1}^{n} \sum_{j=1}^{i} \sum_{k=1}^{j} 1∑i=1n∑j=1i∑k=1j1
- =∑i=1n∑j=1ij=\sum_{i=1}^{n} \sum_{j=1}^{i} j=∑i=1n∑j=1ij
- =∑i=1ni(i+1)2=\sum_{i=1}^{n} \frac{i(i+1)}{2}=∑i=1n2i(i+1)
- =12(∑i=1ni2+(∑i=1ni)=\frac{1}{2} (\sum_{i=1}^{n} i^2 + (\sum_{i=1}^{n} i)=21(∑i=1ni2+(∑i=1ni)
- =12(n(n+1)(2n+1)6+n(n+1)2)=\frac{1}{2}(\frac{n(n+1)(2 n+1)}{6}+\frac{n(n+1)}{2})=21(6n(n+1)(2n+1)+2n(n+1))
- 该算法的时间复杂度为T(n) = O(n3)
-
for (i=1; i<=n; i=i*2) {x++;s=0; }- 若循环执行1次:i = 1*2 = 2
- 若循环执行2次:i = 2*2 = 22
- 若循环执行3次:i = 3*2 = 23
- …
- 若循环执行x次:i = x*2 = 2x
- 设循环中语句的执行次数为x,由于循环条件i<=n,所以2x<=n2^x<=n2x<=n,x=log2nx = log_2nx=log2n
- 所以该算法的时间复杂度为T(n)=O(log2n)T(n) = O(log_2n)T(n)=O(log2n)
-
- 常见的时间复杂度按数量级递增排列依次为
- 常数阶 O(1)、对数阶 O(log2nlog_2nlog2n)、线性阶 O(n)、线性对数阶 O(nlog2nnlog_2nnlog2n)、平方阶 O(n2)、立方阶 O(n3)、…、k次方阶 O(nk)、指数阶 O(2n)、阶乘 O(n!)
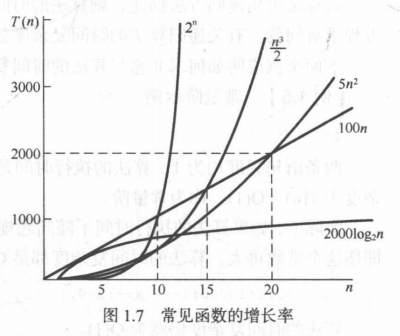
- 一般情况下,随着n增大,T(n)的增长较慢的算法为较优的算法
- 一般情况下,算法的时间复杂度不仅与问题的规模有关,还与问题的其他因素相关,如随问题的输入数据集不同而不同
- 最好时间复杂度:
- 算法在最好情况下的时间复杂度,指算法计算量可能达到的最小值
- 最坏时间复杂度:
- 算法在最坏情况下的时间复杂度,指算法计算量可能达到的最大值
- 平均时间复杂度:
- 指算法在所有可能情况下,按照输入实例以等概率出现时,算法计算量的加权平均值
- 很多情况下,算法的平均复杂度难于确定,通常在讨论算法在最坏情况下的时间复杂度,即分析在最坏情况下,算法执行时间的上界,保证算法的运行时间不会比它更长
- 大O的加法法则与乘法法则
- 加法法则:T(n)=T1(n)+T2(n)=O(f(n))+O(g(n))=O(max(f(n),g(n)))T(n) = T_1(n) + T_2(n) = O(f(n)) + O(g(n)) = O(max(f(n), g(n)))T(n)=T1(n)+T2(n)=O(f(n))+O(g(n))=O(max(f(n),g(n)))
- 乘法发则:T(n)=T1(n)∗T2(n)=O(f(n))∗O(g(n))=O(f(n)∗g(n))T(n) = T_1(n) * T_2(n) = O(f(n)) * O(g(n)) = O(f(n) * g(n))T(n)=T1(n)∗T2(n)=O(f(n))∗O(g(n))=O(f(n)∗g(n))
1.4.4 算法的空间复杂度
- 采用渐近空间复杂度作为算法所需存储空间的量度,简称空间复杂度,它也是问题规模n的函数,记作:
- S(n)=O(f(n))S(n) = O(f(n))S(n)=O(f(n))
- 一般情况下,一个程序在机器上执行时,除了需要寄存本身所用的指令、常数、变量和输入数据外,还需要一些对数据进行操作的辅助存储空间。
- 若算法执行时所需要的辅助空间相对于输入数据量而言是个常数,则称这个算法为原地工作,辅助空间为O(1)
- 求算法的空间复杂度举例。
- 数组逆序,将一维数组逆序存放为原数组
- 算法1
-
for (i=0; i<n; i++) {t = a[i];a[i] = a[n-i-1];a[n-i-1] = t; } - 算法1仅需要另外借助一个变量t,与问题规模n大小无关,所以其空间复杂度为O(1)。
-
- 算法2
-
for (i=0; i<n; i++)b[i] = a[n-i-1]; for (i=0; i<n; i++)a[i] = b[i]; - 算法2需要另外借助一个大小为n的辅助数组b,所以其空间复杂度为O(n)。
-
- 对于一个算法,其时间复杂度和空间复杂度往往是相互影响的,当追求一个较好的时间复杂度时,可能导致占用较多的存储空间,即可能使空间复杂度的性能变差,反之亦然