大模型训练流程(三)奖励模型
为什么需要奖励模型
因为指令微调后的模型输出可能不符合人类偏好,所以需要利用强化学习优化模型,而奖励模型是强化学习的关键一步,所以需要训练奖励模型。
1.模型输出可能不符合人类偏好
上一篇讲的SFT只是将预训练模型中的知识给引导出来的一种手段,而在SFT 数据有限的情况下,我们对模型的引导能力就是有限的。这将导致预训练模型中原先错误或有害的知识没能在 SFT 数据中被纠正,从而出现「有害性」或「幻觉」的问题。
2.需要利用强化学习优化模型
一些让模型脱离昂贵标注数据,自我进行迭代的方法被提出,比如:RLHF,DPO,RLHF是直接告诉模型当前样本的(好坏)得分,DPO 是同时给模型一条好的样本和一条坏的样本。最终目的是告知模型什么是好的数据,什么是不好的数据,将大模型训练地更加符合人类偏好。
3.设计有效的奖励模型是强化学习的关键一步
- 设计有效的奖励模型是 RLHF 的关键一步,因为没有简单的数学或逻辑公式可以切实地定义人类的主观价值。
- 在进行RLHF时,需要奖励模型来评估语言大模型(actor model)回答的是好是坏,这个奖励模型通常比被评估的语言模型小一些(deepspeed的示例中,语言大模型66B,奖励模型只有350M)。奖励模型的输入是prompt+answer的形式,让模型学会对prompt+answer进行打分。
- 奖励模型的目标是构建一个文本质量对比模型,对于同一个提示词,SFT 模型给出的多个不同输出结果的质量进行排序。
训练奖励模型
1.训练数据(人工排好序的数据)
奖励模型的训练数据是人工对问题的每个答案进行排名,如下图所示:
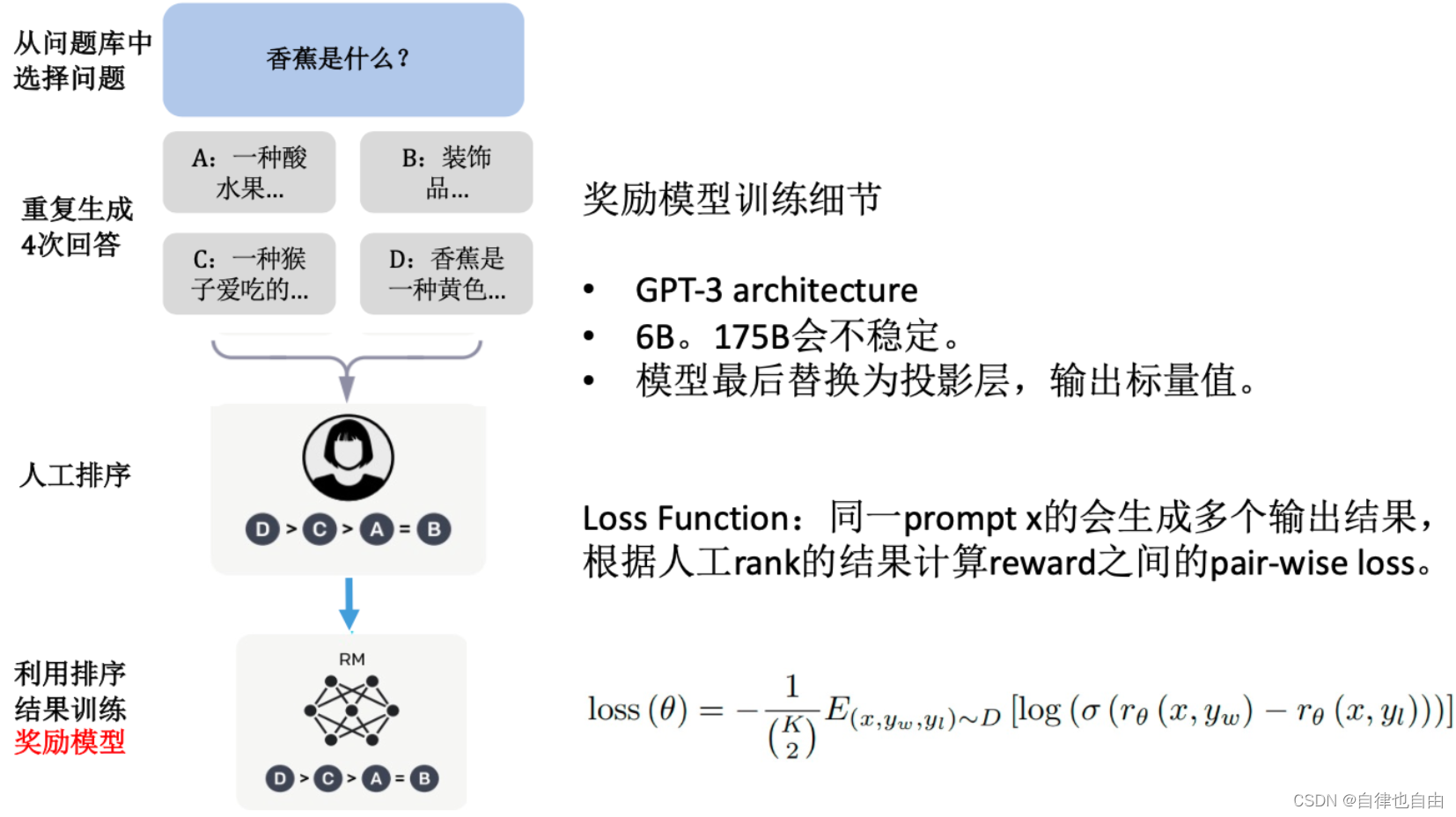
对于每个问题,给出若干答案,然后工人进行排序,而奖励模型就是利用排序的结果来进行反向传播训练。
问题:最终目的是训练一个句子打分模型,为什么不让人直接打分,而是去标排序序列呢?
直接给生成文本进行打分是一件非常难统一的事情。如果对于同样的生成答案,有的标注员打 5 分,但有的标注员打 3 分,模型在学习的时候就很难明确这句话究竟是好还是不好。
既然打绝对分数很难统一,那就转换成一个相对排序的任务能够更方便标注员打出统一的标注结果。
模型通过尝试最大化「好句子得分和坏句子得分之间的分差」,从而学会自动给每一个句子判分。
问题:使用多少数据能够训练好一个RM?
在 OpenAI Summarize 的任务中,使用了 6.4w 条]偏序对进行训练。
在 InstructGPT 任务中,使用了 3.2w 条 [4~9] 偏序对进行训练。
在 StackLlama]任务中,使用了 10w 条 Stack Exchange 偏序对进行训练。
从上述工作中,我们仍无法总结出一个稳定模型需要的最小量级,这取决于具体任务。
但至少看起来,5w 以上的偏序对可能是一个相对保险的量级。
2.模型架构
奖励模型(RM 模型)将 SFT 模型最后一层的 softmax 去掉,即最后一层不用 softmax,改成一个线性层。RM 模型的输入是问题和答案,输出是一个标量即分数。
由于模型太大不够稳定,损失值很难收敛且小模型成本较低,因此,RM 模型采用参数量为 6B 的模型,而不使用 175B 的模型。
问题:RM 模型的大小限制?
Reward Model 的作用本质是给生成模型的生成内容进行打分,所以 Reward Model 只要能理解生成内容即可。
关于 RM 的规模选择上,目前没有一个明确的限制:
Summarize 使用了 6B 的 RM,6B 的 LM。
InstructGPT 使用了 6B 的 RM,175B 的 LM。
DeepMind 使用了 70B 的 RM,70B LM。
不过,一种直觉的理解是:判分任务要比生成认为简单一些,因此可以用稍小一点的模型来作为 RM。
3.损失函数(最大化差值)
假定现在有一个排好的序列:A > B > C >D。
我们需要训练一个打分模型,模型给四句话打出来的分要满足 r(A) > r(B) > r(C) > r(D)。
那么,我们可以使用下面这个损失函数:
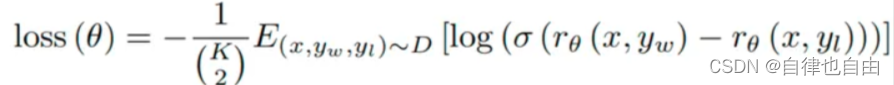
其中,yw 代表排序排在 yl 的所有句子。
用上述例子(A > B > C > D)来讲,loss 等于:
loss = r(A) - r(B) + r(A) - r(C) + r(A) - r(D) + r(B) - r(C) + ... + r(C) - r(D)
loss = -loss
为了更好的归一化差值,我们对每两项差值都过一个 sigmoid 函数将值拉到 0 ~ 1 之间。
可以看到,loss 的值等于排序列表中所有排在前面项的reward减去排在后面项的reward的和。
而我们希望模型能够最大化这个好句子得分和坏句子得分差值,而梯度下降是做的最小化操作。因此,我们需要对 loss 取负数,就能实现最大化差值的效果了。
问题:奖励模型的损失函数为什么会比较答案的排序,而不是去对每一个答案的具体分数做一个回归?
每个人对问题的答案评分都不一样,无法使用一个统一的数值对每个答案进行打分,训练标签不好构建。如果采用对答案具体得分回归的方式来训练模型,会造成很大的误差。但是,每个人对答案的好坏排序是基本一致的。通过排序的方式避免了人为的误差。
问题:奖励模型中每个问题对应的答案数量即K值为什么选 9 更合适,而不是选择 4 呢?
- 进行标注的时候,需要花很多时间去理解问题,但答案之间比较相近,假设 4 个答案进行排序要 30 秒时间,那么 9 个答案排序可能就 40 秒就够了。9 个答案与 4 个答案相比生成的问答对多了 5 倍,从效率上来看非常划算;
- K=9时,每次计算 loss 都有 36 项rθ(x,y)需要计算,RM 模型的计算所花时间较多,但可以通过重复利用之前算过的值(也就是只需要计算 9 次即可),能节约很多时间。
总结
奖励模型通过与人类专家进行交互,获得对于生成响应质量的反馈信号,从而进一步提升大语言模型的生成能力和自然度。与监督模型不同的是,奖励模型通过打分的形式使得生成的文本更加自然逼真,让大语言模型的生成能力更进一步。