第 385 场 LeetCode 周赛题解
A 统计前后缀下标对 I


模拟
class Solution {
public:int countPrefixSuffixPairs(vector<string> &words) {int n = words.size();int res = 0;for (int i = 0; i < n; i++)for (int j = i + 1; j < n; j++)if (words[i].size() <= words[j].size()) {int li = words[i].size(), lj = words[j].size();if (words[i] == words[j].substr(0, li) && words[i] == words[j].substr(lj - li, li))res++;}return res;}
};
B 最长公共前缀的长度

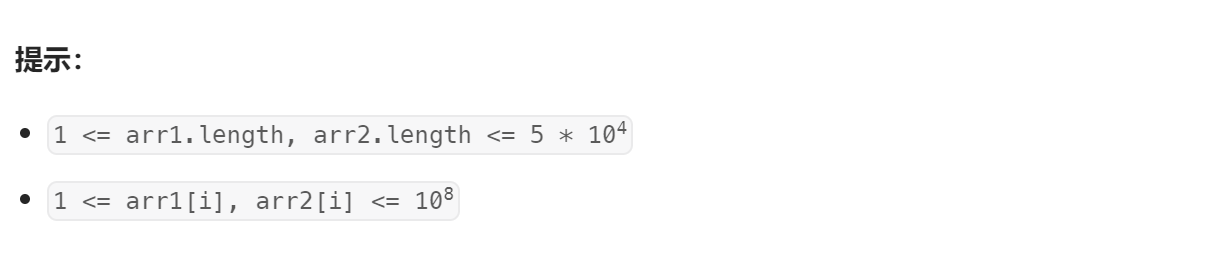
字典树:先将 a r r 1 arr1 arr1 中元素加入字典树,然后遍历 a r r 2 arr2 arr2 中元素,在字典树上查询最长的匹配的前缀
class Solution {
public:int longestCommonPrefix(vector<int> &arr1, vector<int> &arr2) {trie tree;for (auto x: arr1)tree.insert(x);int res = 0;for (auto x: arr2)res = max(res, tree.query(x));return res;}class trie {//字典树public:vector<trie *> next;trie() {next = vector<trie *>(10);}void insert(int x) {string s = to_string(x);trie *cur = this;for (auto c: s) {if (!cur->next[c - '0'])cur->next[c - '0'] = new trie();cur = cur->next[c - '0'];}}int query(int x) {string s = to_string(x);trie *cur = this;int res = 0;for (auto c: s)if (cur->next[c - '0']) {res++;cur = cur->next[c - '0'];} elsebreak;return res;}};
};
C 出现频率最高的素数




枚举:枚举并计数各个单元格向各方向能生成的大于10的素数
class Solution {
public:int mostFrequentPrime(vector<vector<int>> &mat) {int m = mat.size(), n = mat[0].size();int dr[8] = {1, 0, -1, 0, 1, 1, -1, -1};int dc[8] = {0, 1, 0, -1, 1, -1, 1, -1};unordered_map<int, int> cnt;for (int r = 0; r < m; r++)for (int c = 0; c < n; c++) {for (int k = 0; k < 8; k++) {int cur = mat[r][c];for (int nr = r + dr[k], nc = c + dc[k];; nr += dr[k], nc += dc[k]) {if (nr < 0 || nr >= m || nc < 0 || nc >= n)break;cur = cur * 10 + mat[nr][nc];if (isprime(cur))cnt[cur]++;}}}int mx = 0, res = -1;for (auto &[vi, ci]: cnt)if (ci > mx || ci == mx && vi > res) {res = vi;mx = ci;}return res;}bool isprime(int x) {for (int i = 2; i * i <= x; i++)if (x % i == 0)return false;return true;}
};
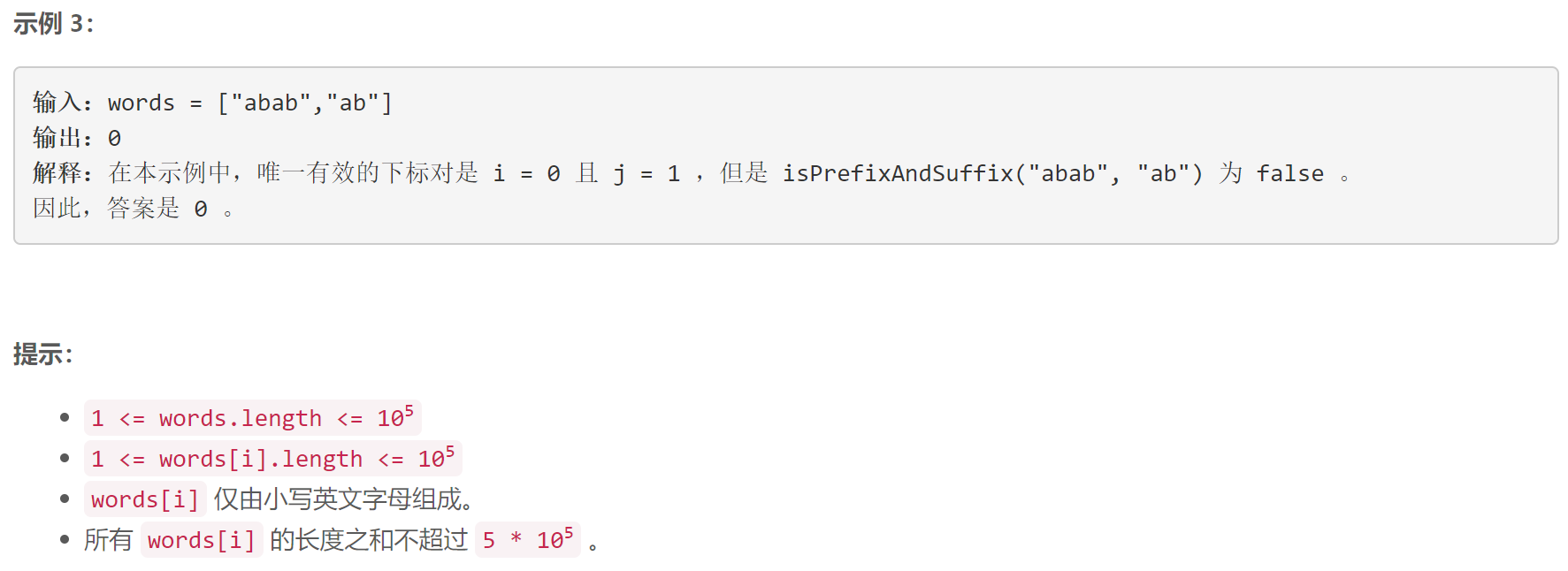
D 统计前后缀下标对 II

哈希 + 字符串哈希:遍历 w o r d [ i ] word[i] word[i] ,枚举 w o r d [ i ] word[i] word[i] 的前缀,若其长为 l l l 的前缀和长为 l l l 的后缀相同,则答案增加 w o r d [ 0 , i − 1 ] word[0,i-1] word[0,i−1] 中 w o r d [ i ] word[i] word[i] 长为 l l l 的前缀的出现次数
class Solution {
public:long long countPrefixSuffixPairs(vector<string> &words) {int n = words.size();srand(time(0));int e = 2333 + rand() % 10, mod = 1e9 + rand() % 10;unordered_map<int, int> cnt;//记录字符串(通过哈希值表示)的出现次数long long res = 0;for (int i = 0; i < n; i++) {shash hi(words[i], e, mod);int m = words[i].size();for (int l = 1; l <= m; l++) {if (auto pre = hi(0, l - 1);pre == hi(m - l, m - 1) && cnt.count(pre))res += cnt[pre];}cnt[hi(0, m - 1)]++;}return res;}class shash {//字符串哈希模板public:using ll = long long;vector<ll> pres;vector<ll> epow;ll e, p;shash(string &s, ll e, ll p) {int n = s.size();this->e = e;this->p = p;pres = vector<ll>(n + 1);epow = vector<ll>(n + 1);epow[0] = 1;for (int i = 0; i < n; i++) {pres[i + 1] = (pres[i] * e + s[i]) % p;epow[i + 1] = (epow[i] * e) % p;}}ll operator()(int l, int r) {ll res = (pres[r + 1] - pres[l] * epow[r - l + 1] % p) % p;return (res + p) % p;}};
};