学习笔记——ENM模拟
学习笔记——ENM模拟
文章目录
- 前言
- 一、文献一
- 1. 材料与方法
- 1.1. 大致概念
- 1.2. 生态模型的构建
- 1.2.1. 数据来源:
- 1.2.2. 数据处理:
- 1.2.3. 模型参数优化:
- 1.3. 适生情况预测
- 1.3.1. 预测模型构建
- 1.3.2. 适生区划分
- 1.4. 模型的评估与验证
- 2. 结果与分析
- 2.1. 预测模型的构建
- 2.2. 潜在的适生分布预测
- 2.3. 生态模型的评估与验证
前言
学习文献里的方法,初步了解一下什么是ENM模拟
文献名称:
《基于MaxEnt模型和ArcGIS预测多肋藻在中国海域的适生分布特征》
一、文献一
1. 材料与方法
1.1. 大致概念
本研究采用MaxEnt 模型预测多肋藻在我国的适生情况, 并探究不同因子对多肋藻孢子体生长的影响,旨在为开展多肋藻栽培提供支撑。
关键词: 多肋藻; MaxEnt; ArcGIS; 生态风险; 适生分布
物种分布模型(species distribution model, SDM)
主要是根据物种特定的生存环境及存在的分布位点, 通过模型的数学算法模拟出其基本生态位, 可解释为物种出现的概率分布或生境适宜度等。
目前应用较广的 SDM有 BIOCLIM、CLIMEX、DOMAIN、GAM、GARP、MaxEnt、ENFA 等。
MaxEnt (maximum entropy)模型
是基于最大熵理论, 即假设物种在没有约束的情况下, 会尽最大可能扩散蔓延, 接近均匀分布。最大熵模型以物种仅存在分布信息及相关环境因子信息, 依靠数学模型来推算物种的生态需求, 并模拟物种在目标区域的适生概率。
1.2. 生态模型的构建
所采用的生态位预测模型为最大熵模型MaxEnt 3.4, 运用 ArcGIS 10.2 划分适生区
1.2.1. 数据来源:
物种分布数据
分布信息来源: 全球生物多样性信息网络 GBIF (https://www.gbif.org/zh/)和文献资料, 选取明确位置的分布点, 并通过地名数据库 GNDB(https://dmfw.mca.gov.cn/index.html)查验经纬度坐标信息。
最后整理成物种名–经度–纬度形式, 保存为*.CSV 格式文件
环境变量数据
来源于全球海洋生物扩散模型环境数据库 Bio-ORICLE (https://bio-oracle.org/)中基于 2000─2014 年期间月平均值的气候数据编制的图层, 其空间分辨率为 5 arcmin (约为9.2 km), 下载格式为*.asc 格式。选择影响海洋藻类分布的 42 项环境参数。
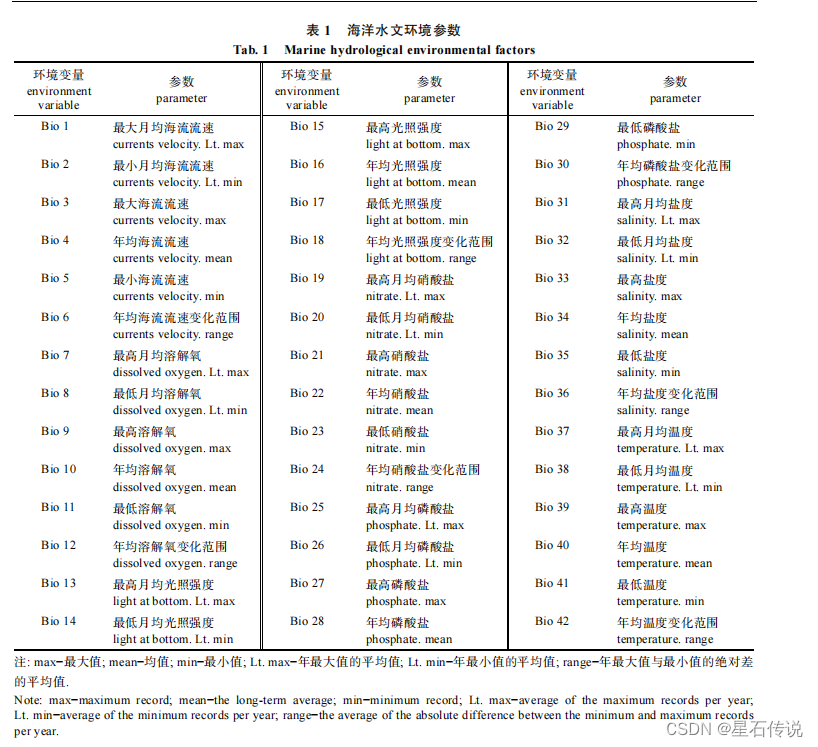
地图数据
选用 1∶400 万中国省级行政区图作为分析地图, 从国家基础地理信息系统网站(http://www.ngcc.cn/ngcc/)下载
推荐文章:
国家基础地理信息中心行政边界等矢量数据免费下载保姆级教程–关于地理数据收集与处理的基本工具推荐(7)
1.2.2. 数据处理:
分布数据的空间过滤
物种分布点的数据通过 Excel 删除重复点后, 将剩余分布位点导入 ArcGIS 中, 通过投影工具, 对分布点建立以 m 为单位的坐标系, 并以每个分布点为中心, 建立半径为 5 km 的圆型区域进行邻域分析,
删去重叠交叉的分布簌, 随机保留其中一个位点, 将最终保留下的分布点数据用于模型构建。
环境变量的相关性检验与筛选

下载ArcGIS软件:
https://zhuanlan.zhihu.com/p/670775519
下载 MaxEnt软件:
http://lucky-boy.ysepan.com/
(注意:这个网站有许多生物信息学相关资源。强烈推荐)
1.2.3. 模型参数优化:
正则化参数的优化

(训练集 : 测试集)比值的优化
设置 4 组训练集与测试集组合(50 : 50、70 : 30、75 : 25、80 : 20),
正则化参数取上述 8 组不同系数经 5–折交叉验证
后的最佳 β 值, 环境变量同上筛选, 并选择
随机种子设置, 其余参数为系统默认值, 每组重复
运行 10 次, 比较各组的平均测试 AUC 值, 选择最
高 AUC 值的训练集: 测试集组合用于模型构建
1.3. 适生情况预测
多肋藻在我国适生情况预测
1.3.1. 预测模型构建
将经 1.2.2处理的分布点、环境变量数据分别导入 MaxEnt 模型, 根据 1.2.3化结果设置正则化参数 β 以及训练集: 测试集参数, 构建环境变量响应曲线, 并采用刀切法检测环境变量的贡献值, 以 logistic 格式输出概率分布预测图。
1.3.2. 适生区划分

1.4. 模型的评估与验证

2. 结果与分析
结果与分析
2.1. 预测模型的构建
环境变量筛选
正则化参数的交叉验证和(训练集 : 测试
集)比值的筛选
2.2. 潜在的适生分布预测
2.3. 生态模型的评估与验证
