ES监控方法以及核心指标
文章目录
- 1. 监控指标采集
- 1.1 部署elasticsearch_exporter
- 1.2 prometheus采集elasticsearch_exporter的暴露指标
- 1.3 promethues配置告警规则或者配置grafana大盘
- 2. 核心告警指标
- 2.1 es核心指标
- 2.2 es容量模型建议
- 3. 参考文章
探讨es的监控数据采集方式以及需要关注的核心指标,便于日常生产进行监控和巡检。
1. 监控指标采集
监控指标的采集方式使用promethues + elasticsearch_exporter的方式采集es的指标,并通过promethues协议暴露出来。本文探讨es的采集监控方式,以及常用核心监控告警配置。
1.1 部署elasticsearch_exporter
elasticsearch_exporter的 下载地址 选择合适的版本下载,并解压,使用如下方法启动。
# 不带鉴权方式
./elasticsearch_exporter --web.listen-address=":9114" --es.uri=http://127.0.0.1:9200
# 带鉴权方式
./elasticsearch_exporter --web.listen-address=":9114" --es.uri=http://admin:pass@127.0.0.1:9200
确定metrics指标暴露出来后,就可以通过prometheus配置target进行指标采集
# 通过promethues协议暴露指标
curl http://localhost:9114/metrics
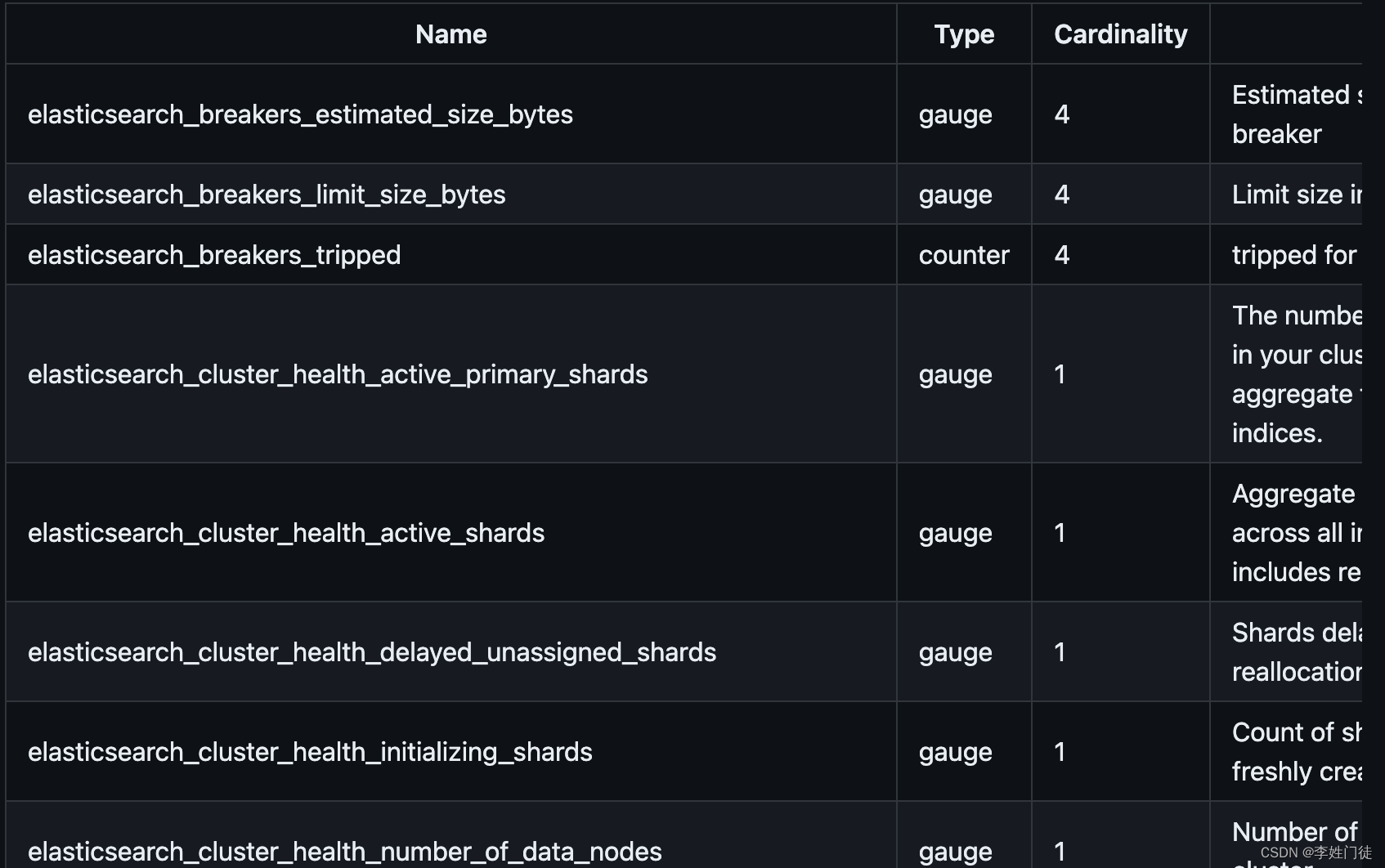
1.2 prometheus采集elasticsearch_exporter的暴露指标
配置prometheus的指标采集任务
- job_name: esstatic_configs:- targets: ['172.19.0.2:9114','172.19.0.3:9114','172.19.0.4:9114']labels:instance: es
1.3 promethues配置告警规则或者配置grafana大盘
再次不进行扩展。
2. 核心告警指标
es的指标很多,相关的指标含义可以参考 官网文档,本文将摘选出核心的指标,作为es集群的核心监控并配置相关的告警。
2.1 es核心指标
es性能指标有以下三类:
- es本身的指标
- 主机层面的指标
- JVM垃圾回收指标
es层面指标
| 指标名称 | 指标说明 | 参考值 | 备注 |
|---|---|---|---|
| 进程 | 进程 | 进程存在 == 1 | |
| 指标名称 | 指标说明 | 参考值 | 备注 |
| elasticsearch_cluster_health_status{status=“green”} | 集群状态 | !==1 | green( 所有的主分片和副本分片都正常运行)、yellow(所有的主分片都正常运行,但不是所有的副本分片都正常运行)red(有主分片没能正常运行) |
| elasticsearch_cluster_health_relocating_shards | 前节点正在迁移到其他节点的分片数量 | <=20 | 通常为0,集群中有节点新加入或者退出时该值会增加 |
| elasticsearch_cluster_health_initializing_shards | 正在初始化的分片 | <=50 | 如果数据写入,通常持续有小幅度值出现 |
| elasticsearch_cluster_health_unassigned_shards | 未分配的分片数 | <=1 | 通常为0,当有节点的副本分片丢失该值会增加 |
| elasticsearch_cluster_health_number_of_pending_tasks | 队列中等待的任务 | <=20 | 绝大部分情况下元数据更改的队列基本上保持为零 |
| elasticsearch_cluster_health_active_shards | 活跃的分片数量 | <=3w | 通常按照容量模型,单个集群的总分片不应该超过3w |
| 暂无指标 | 单shard数据存储大小 | <=50g | 通常按照容量模型,单个分片的最大存储数据量不应该超过50g |
机器层面指标
| 指标名称 | 指标说明 | 参考值 | 备注 |
|---|---|---|---|
| elasticsearch_process_cpu_percent | CPU使用率 | <=80% | 机器的cpu使用率不能过高 |
| elasticsearch_filesystem_data_free_bytes | 磁盘可用空间 | >=30% | 机器的磁盘是使用率不能过高,否则可能会触发只读风险 |
| elasticsearch_process_open_files_count | 进程打开的文件描述符 | <=60w | 需要配置ulimit,匹配相关的进程进行文件读写,通常不能低于60w |
| elasticsearch_transport_rx_packets_total | 节点之间网络入流量 | 根据机器的规格调整 | 节点之间网络入流量,根据机器的网络网卡规格调整,如果单节点的出入网络过高则说明需要扩容了 |
| elasticsearch_transport_tx_packets_total | 节点之间网络出流量 | 根据机器的规格调整 | 节点之间网络出流量,根据机器的网络网卡规格调整,如果单节点的出入网络过高则说明需要扩容了 |
JVM指标
| 指标名称 | 指标说明 | 参考值 | 备注 |
|---|---|---|---|
| MemHeapUsedM/MemHeapMaxM | Jvm 堆内内存使用率 | <= 60% |
2.2 es容量模型建议
根据公有云以及es的维护、使用的相关经验,单个es集群的容量不是无上限,整理出es的容量模型,需要进行注意及时扩容或者做数据分流
1.【公有云 ES 最佳实践】
1.1 集群总分片数 < 30000,单个索引分片大小建议不超过 50g,单节点分片数量 < 4000
1.2 节点数超过 20 节点添加专有 master 节点,即 data:master ≤ 20:1
1.3 cpu/mem/disk 建议比例
搜索场景:比例 1:2:32
日志场景:比例 1:4:192 ~ 1:4:384
1.4 单节点性能规格参考
写入性能: 16c/64g、 jvm 32G 单节点可支持 2w docs/s 写入
存储容量 = 源数据 * (1 + 副本数量) * 1.45 * (1 + 0.5)≈ 源数据 * (1 + 副本数量)
2.【社区建议】
2.1 数据加速、查询聚合等场景:单节点磁盘最大容量 = 单节点内存大小(GB)* 10。
日志写入、离线分析等场景:单节点磁盘最大容量 = 单节点内存大小(GB)* 50。
通常情况:单节点磁盘最大容量 = 单节点内存大小(GB)* 30。
2.2单个数据节点的shard数量 = 当前节点的内存大小 * 30(小规格实例参考)
单个数据节点的shard数量 = 当前节点的内存大小 * 50(大规格实例参考)
3.其他指标
cpu < 60%
jvm内存 < 80%
磁盘util < 60%
磁盘使用率 < 70%
集群所有index,必须至少1主 + 1从副本
集群读写拒绝率 < 0.1%
集群无节点 old gc
单节点承载最大数据量 < 1T
ES版本 >= 6.8
3. 参考文章
- es监控官网