MYSQL中group by分组查询的用法详解(where和having的区别)!
文章目录
- 前言
- 一、数据准备
- 二、使用实例
- 1.如何显示每个部门的平均工资和最高工资
- 2.显示每个部门的每种岗位的平均工资和最低工资
- 3.显示平均工资低于2000的部门和它的平均工资
- 4.having 和 where 的区别
- 5.SQL查询中各个关键字的执行先后顺序
前言
在前面的文章中,我们介绍了MYSQL中常见的CURD操作,而今天要谈的是在select 中使用group by 子句可以对指定列进行分组查询。
一、数据准备
我们准备了3张表及以下数据进行测试:
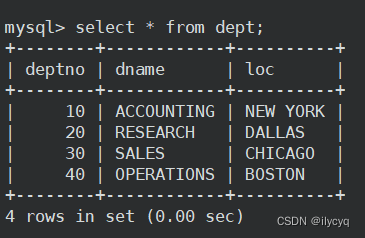
部门表(部门编号、部门名称、地点):
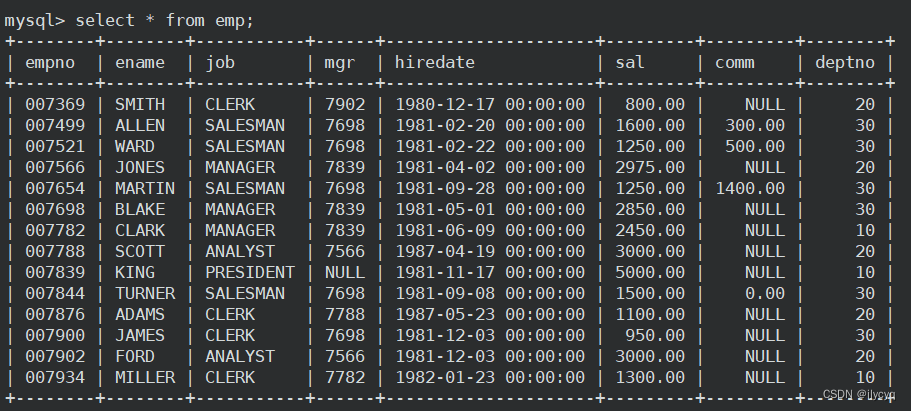
员工表(员工编号,名字,职位,领导编号,雇佣时间,月薪,奖金,部门编号):
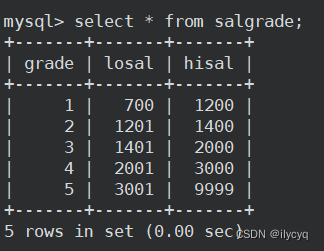
薪水等级表(等级,最低工资,最高工资):
创建实例的语句:
DROP database IF EXISTS `scott`;
CREATE database IF NOT EXISTS `scott` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;USE `scott`;DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (`deptno` int(2) unsigned zerofill NOT NULL COMMENT '部门编号',`dname` varchar(14) DEFAULT NULL COMMENT '部门名称',`loc` varchar(13) DEFAULT NULL COMMENT '部门所在地点'
);DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'
);DROP TABLE IF EXISTS `salgrade`;
CREATE TABLE `salgrade` (`grade` int(11) DEFAULT NULL COMMENT '等级',`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资'
);insert into dept (deptno, dname, loc)
values (10, 'ACCOUNTING', 'NEW YORK');
insert into dept (deptno, dname, loc)
values (20, 'RESEARCH', 'DALLAS');
insert into dept (deptno, dname, loc)
values (30, 'SALES', 'CHICAGO');
insert into dept (deptno, dname, loc)
values (40, 'OPERATIONS', 'BOSTON');insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, null, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, null, 10);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, '1981-11-17', 5000, null, 10);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698,'1981-09-08', 1500, 0, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, null, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, null, 10);insert into salgrade (grade, losal, hisal) values (1, 700, 1200);
insert into salgrade (grade, losal, hisal) values (2, 1201, 1400);
insert into salgrade (grade, losal, hisal) values (3, 1401, 2000);
insert into salgrade (grade, losal, hisal) values (4, 2001, 3000);
insert into salgrade (grade, losal, hisal) values (5, 3001, 9999);
二、使用实例
1.如何显示每个部门的平均工资和最高工资
我们很容易拿到整张表的最高工资和平均工资,但是如果要按照每个部门来显示呢?
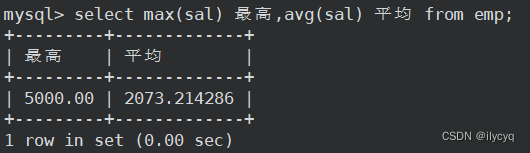
这种情况就需要用到 group by 子句来进行分组查询:
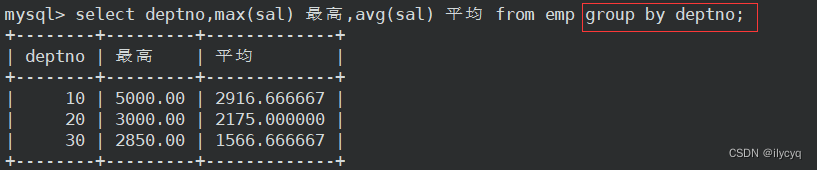
这时我们可以来理解一下分组:
- 分组的目的是为了进行分组后,方便进行聚合统计
- 指定列名分组,实际上是按照这一列数据是否相同而进行分组,相同则一组
2.显示每个部门的每种岗位的平均工资和最低工资
我们可以在 group by 后面添加多个列,同时满足这两个条件相等的数据会被分到一组:
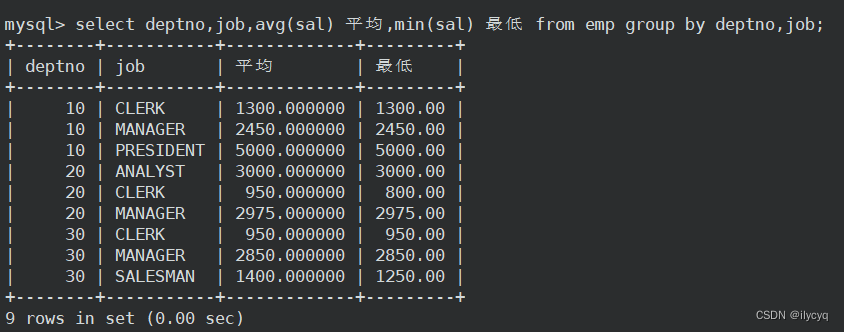
如果我们在 select 后面加上ename字段会报错:

MYSQL的报错信息是:
SELECT 列表的表达式 #1 不在 GROUP BY 子句中,并且包含非聚合列“scott.emp.ename”,
该列在功能上不依赖于 GROUP BY 子句中的列; 这与 sql_mode=only_full_group_by 不兼容
3.显示平均工资低于2000的部门和它的平均工资

这里having的功能和where类似,但如果我们换成where:

我们前面在介绍where时就说过,别名不能在where子句中使用!
4.having 和 where 的区别
我们用下面的例子来解释它们的区别:

这个语句的有5个动作,它们的顺序依此是:
- from:从emp表中进行查询
- where:对任意列进行条件筛选
- group by:进行分组
- having:对分组聚合之后的结果进行条件筛选
- select:筛选出符合条件的数据
所以我们现在很容易理解它们的区别:
- 作用时间不同:where执行优先级高于having
- 作用场景不同:having经常和group by搭配使用,作用是对分组进行筛选
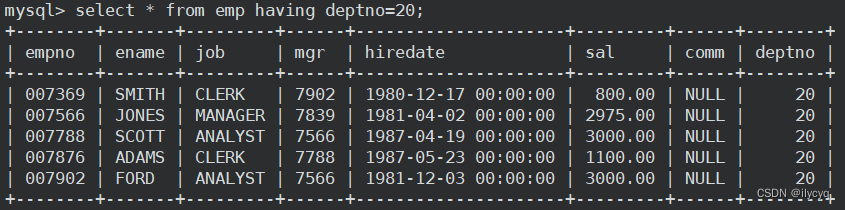
但 having 作用和 where 类似,可以单独使用:
5.SQL查询中各个关键字的执行先后顺序
from > on> join > where > group by > with > having > select> distinct > order by > limit