机器学习:Transformer
Transformer
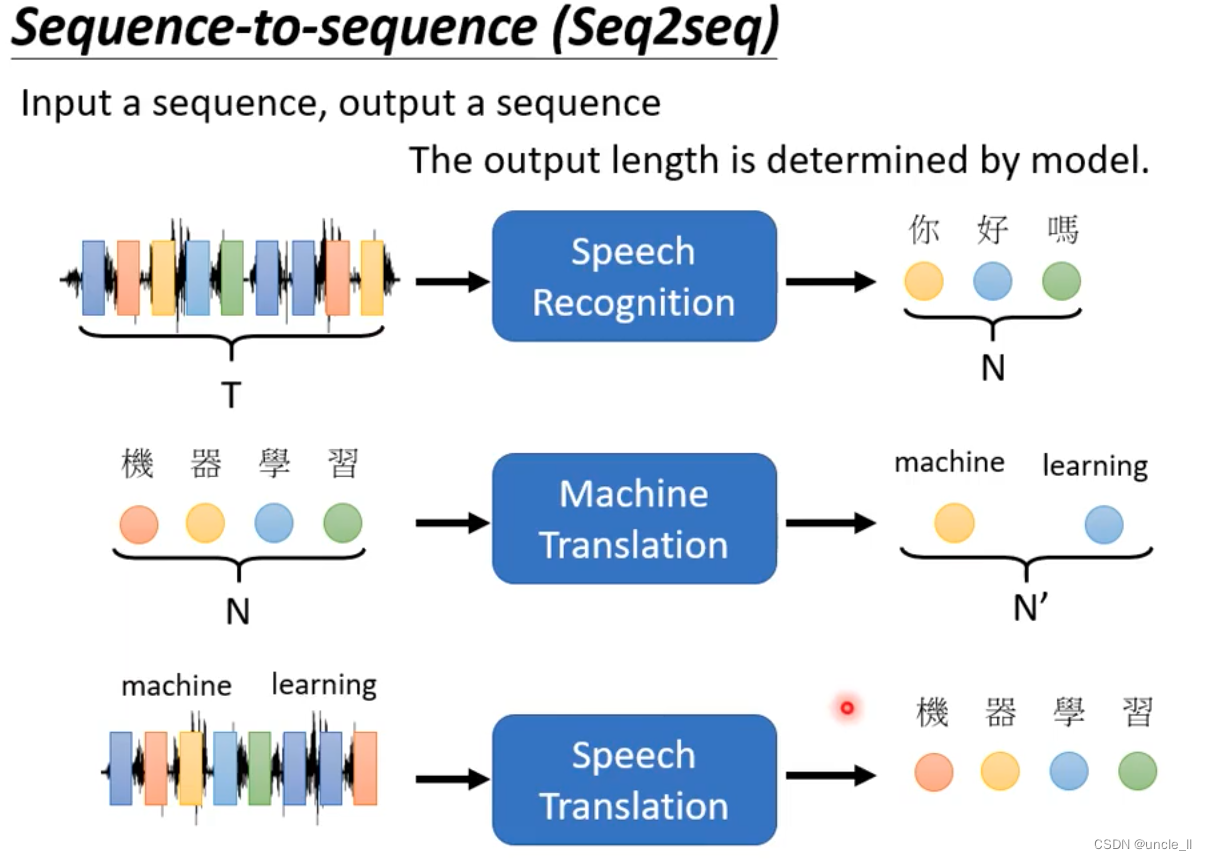
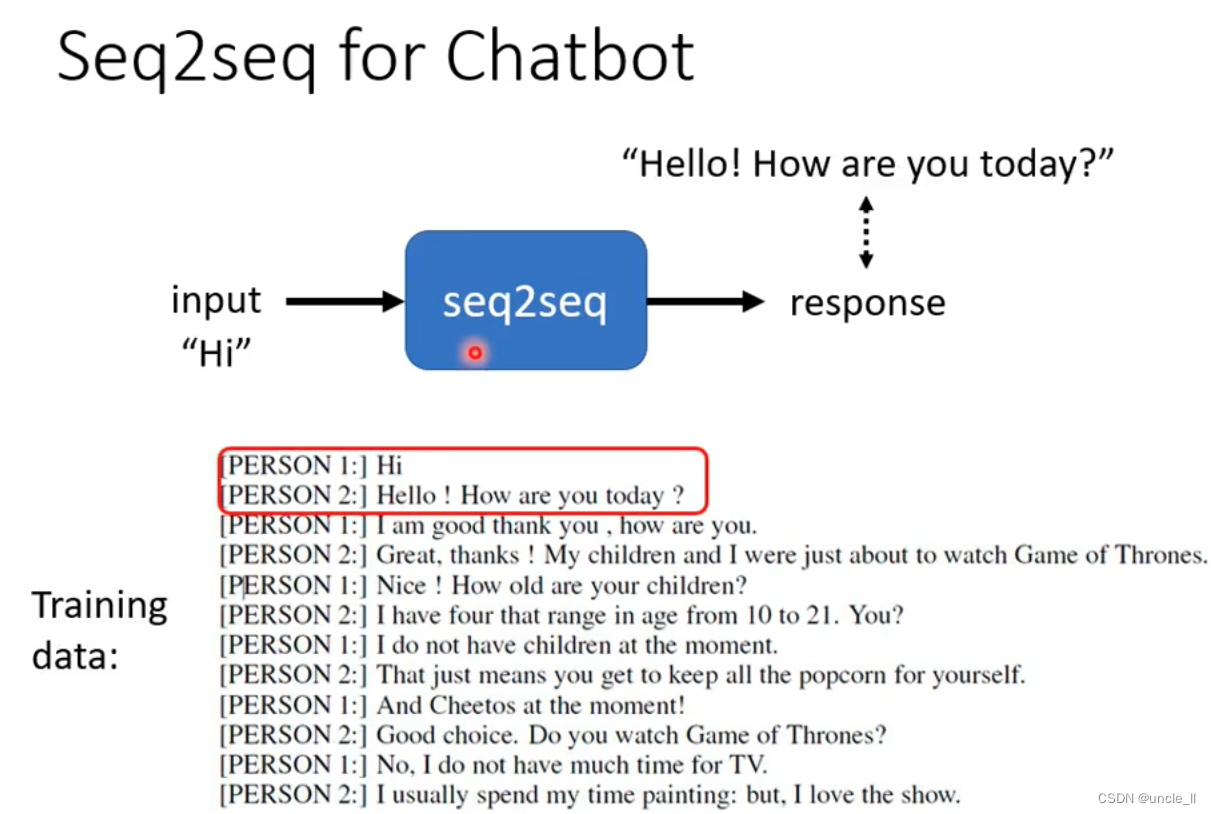
sequence-to-sequence(seq2seq)
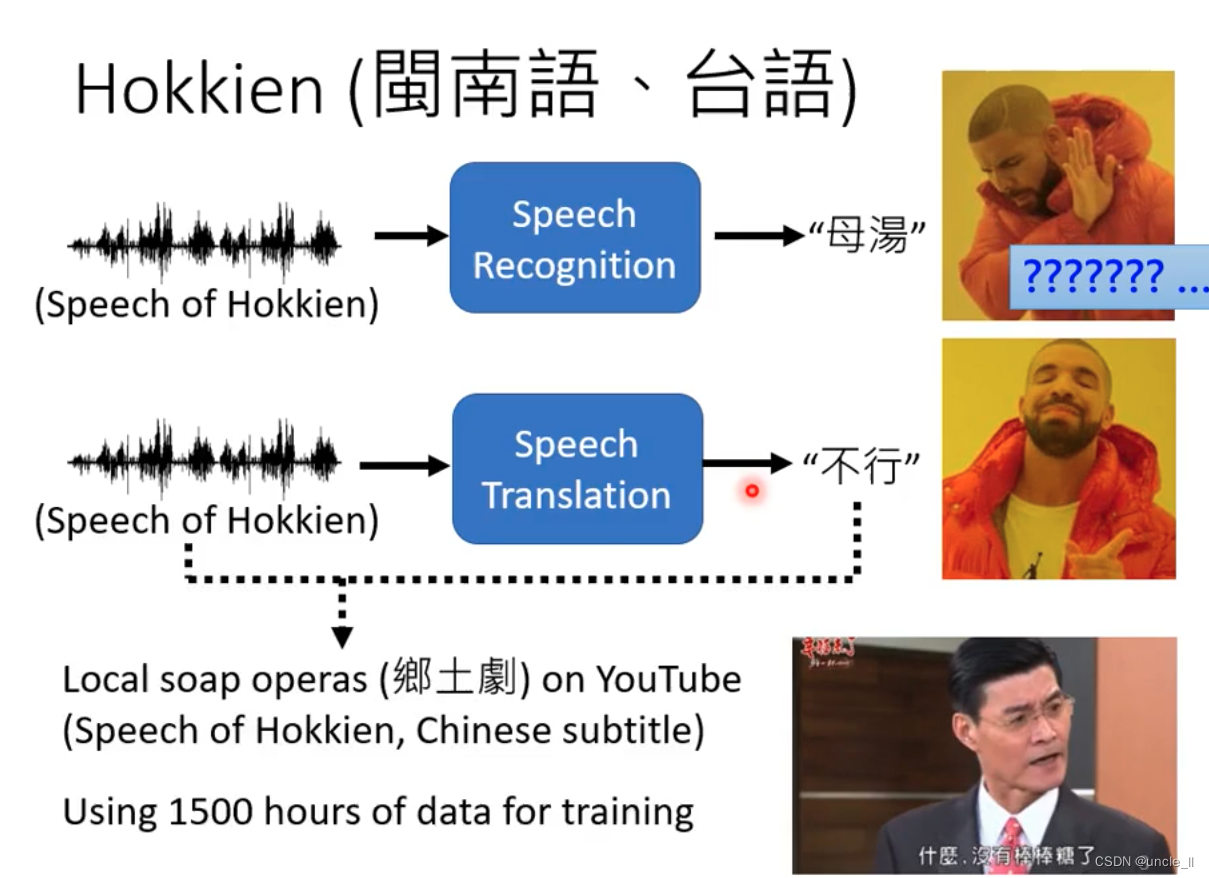
很大语音没有文本,7000种中超半数没有文字。
遇到的问题:

遇到问题时候可以先不管它,先出一个baseline看看效果,后续再进行提升。
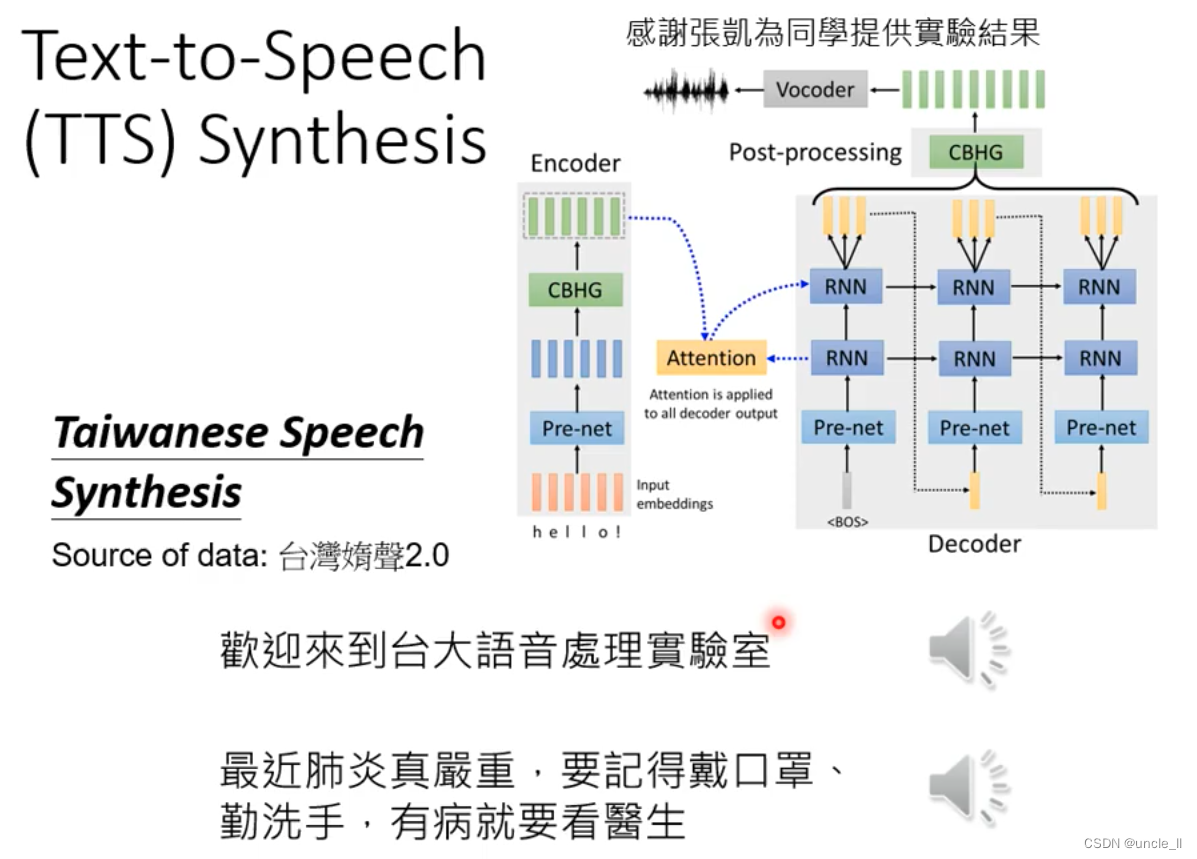
tts: 文本转语音,语音合成
目前是两阶段:先用文本转成中文音标,再转成声音信号。
Seq2seq for chatbot
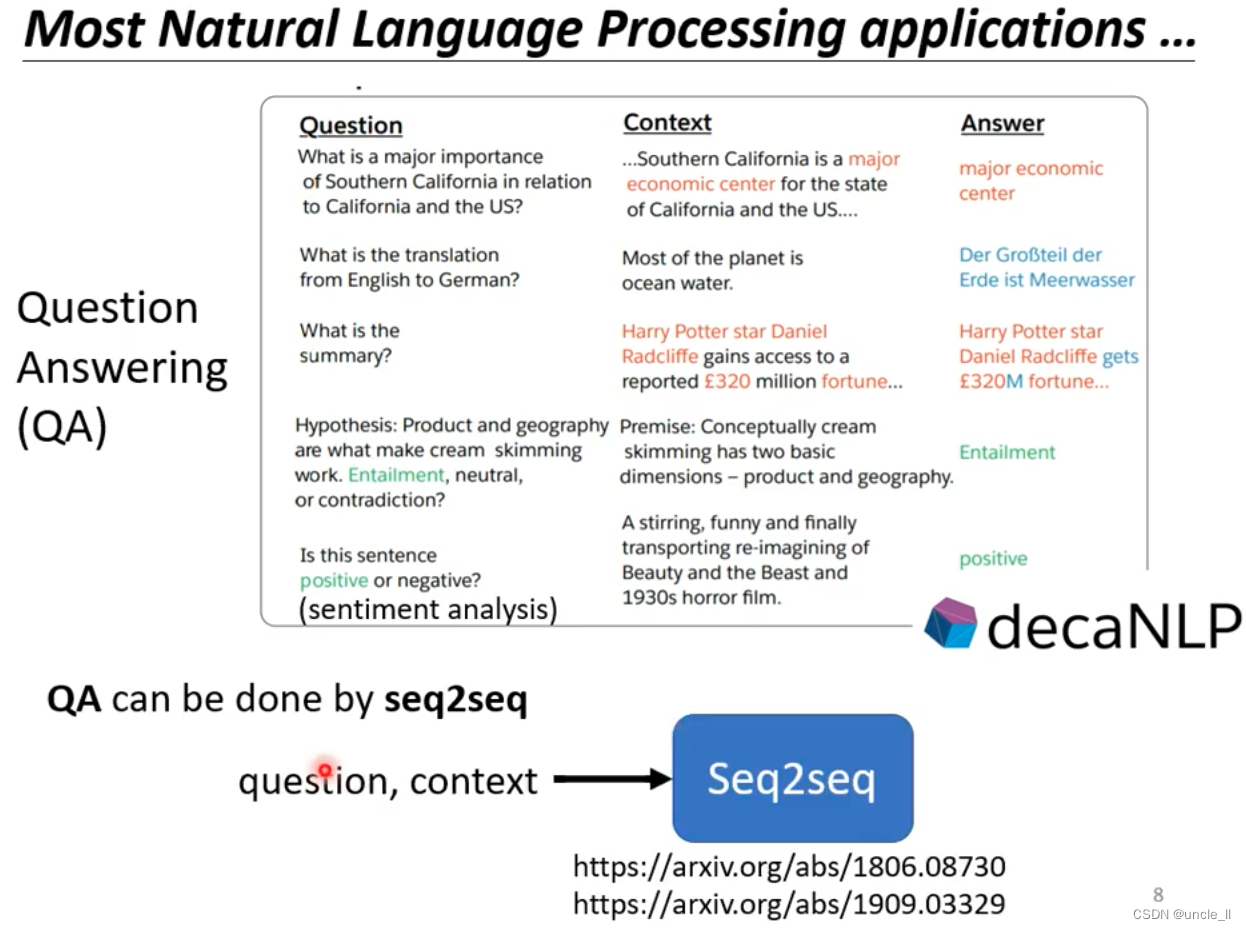
可以将大多数的NLP任务看做是Question Answering任务(QA),QA问题可以用seq2seq解决。定制化的模型比单一模型效果要好一点,但随着大模型的到来,效果可能会越好越好。感兴趣的可以继续学习下面课程。
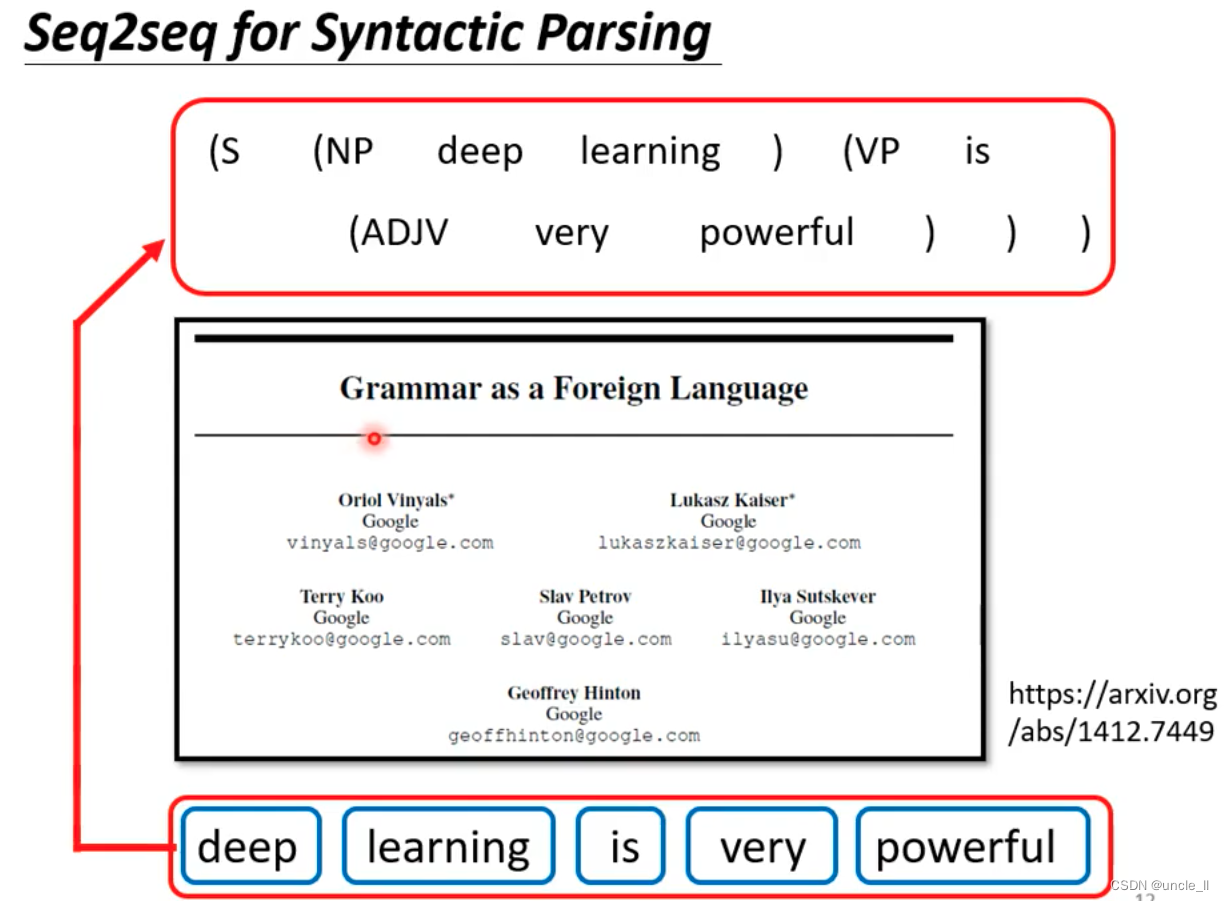
Seq2seq for syntactic parsing
Seq2seq for Multi-label classification
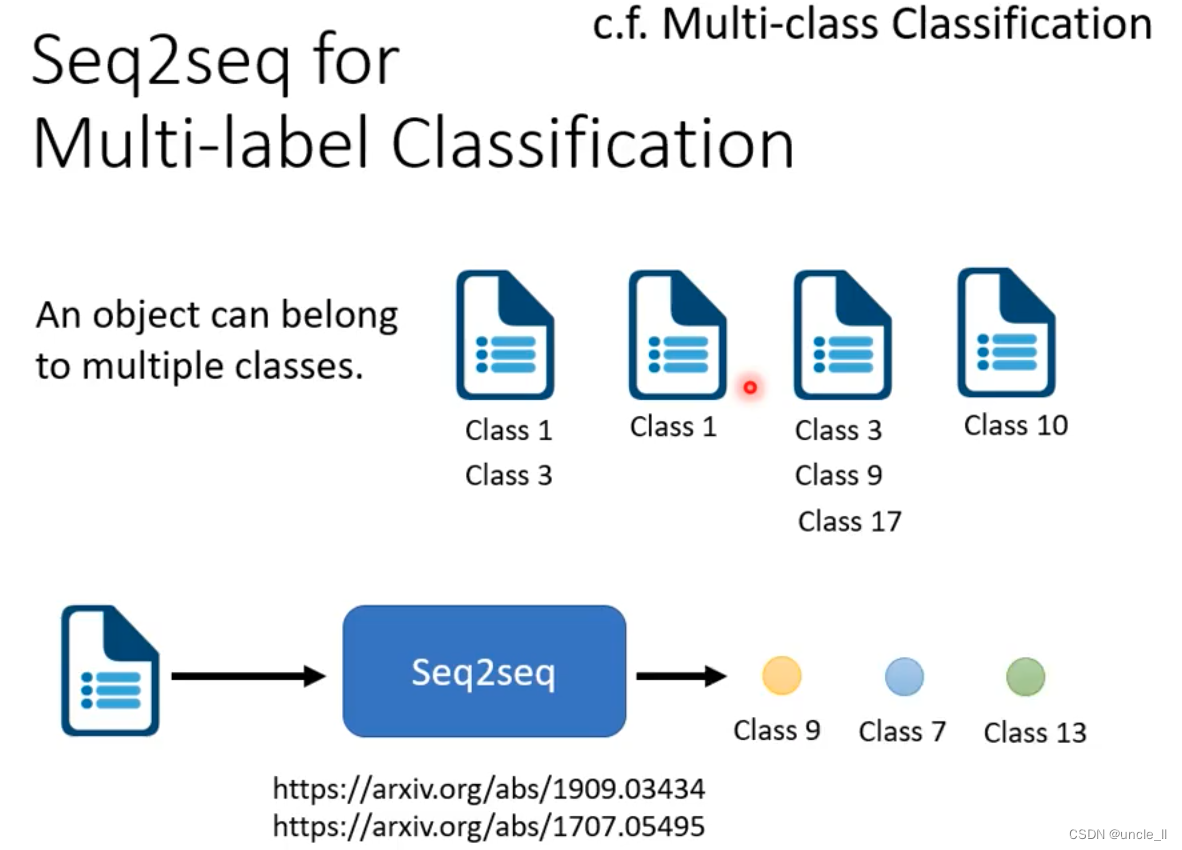
机器自己决定输出多少个类别。
Seq2seq for object detection
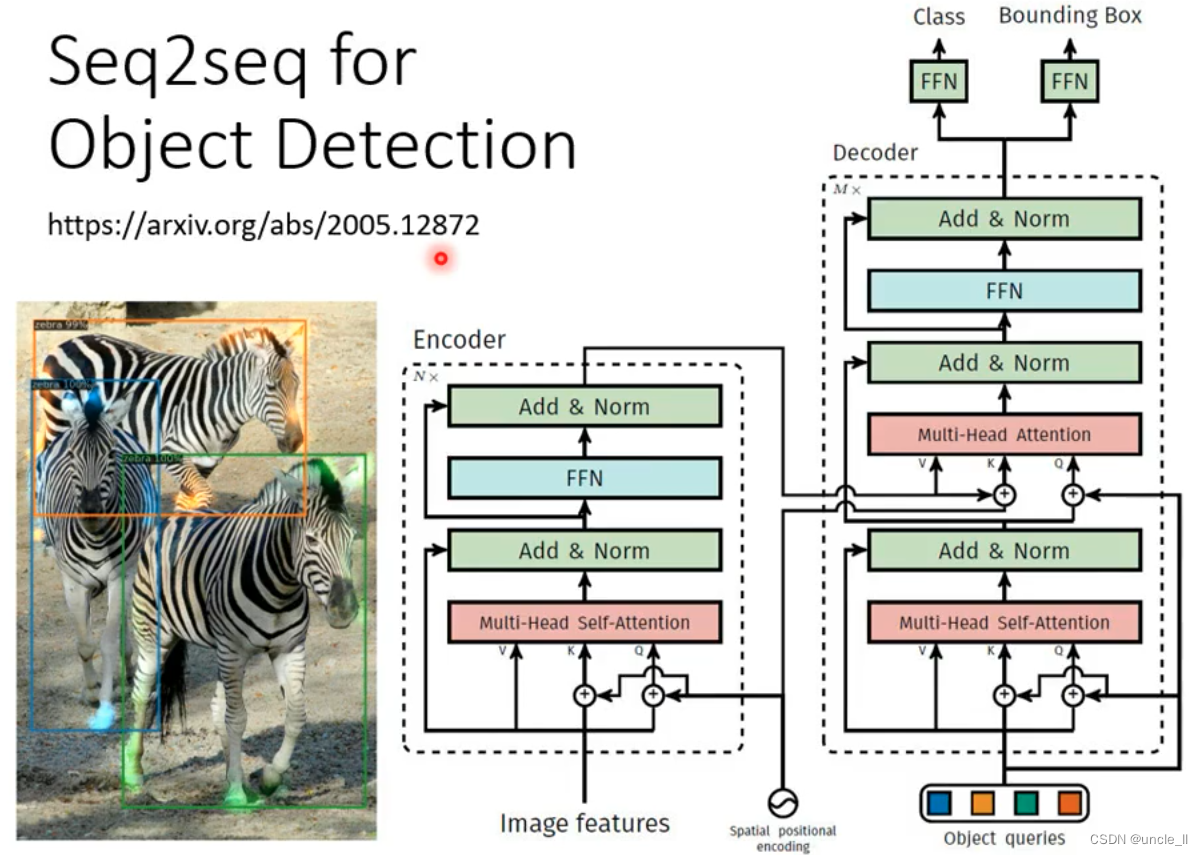
硬解目标检测问题,输入是图像,输出是文本框及类别
–
Seq2seq 基本原理
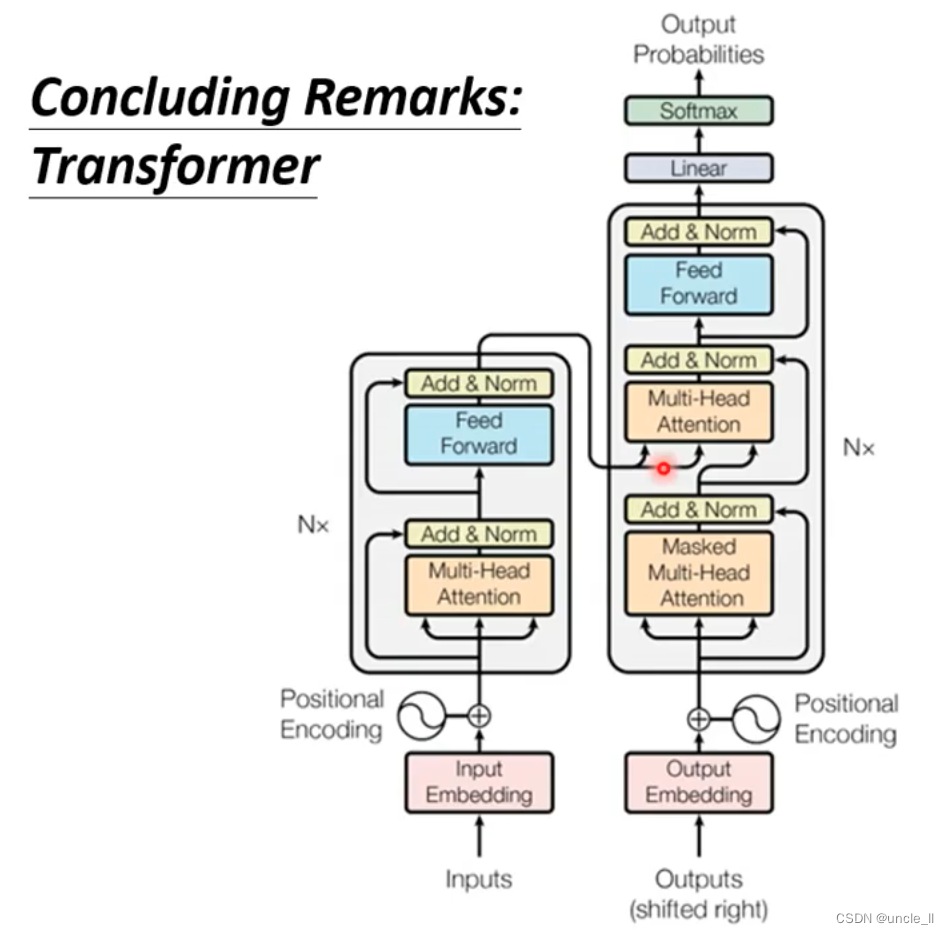
包含两个部件,编码器encoder和译码器decoder
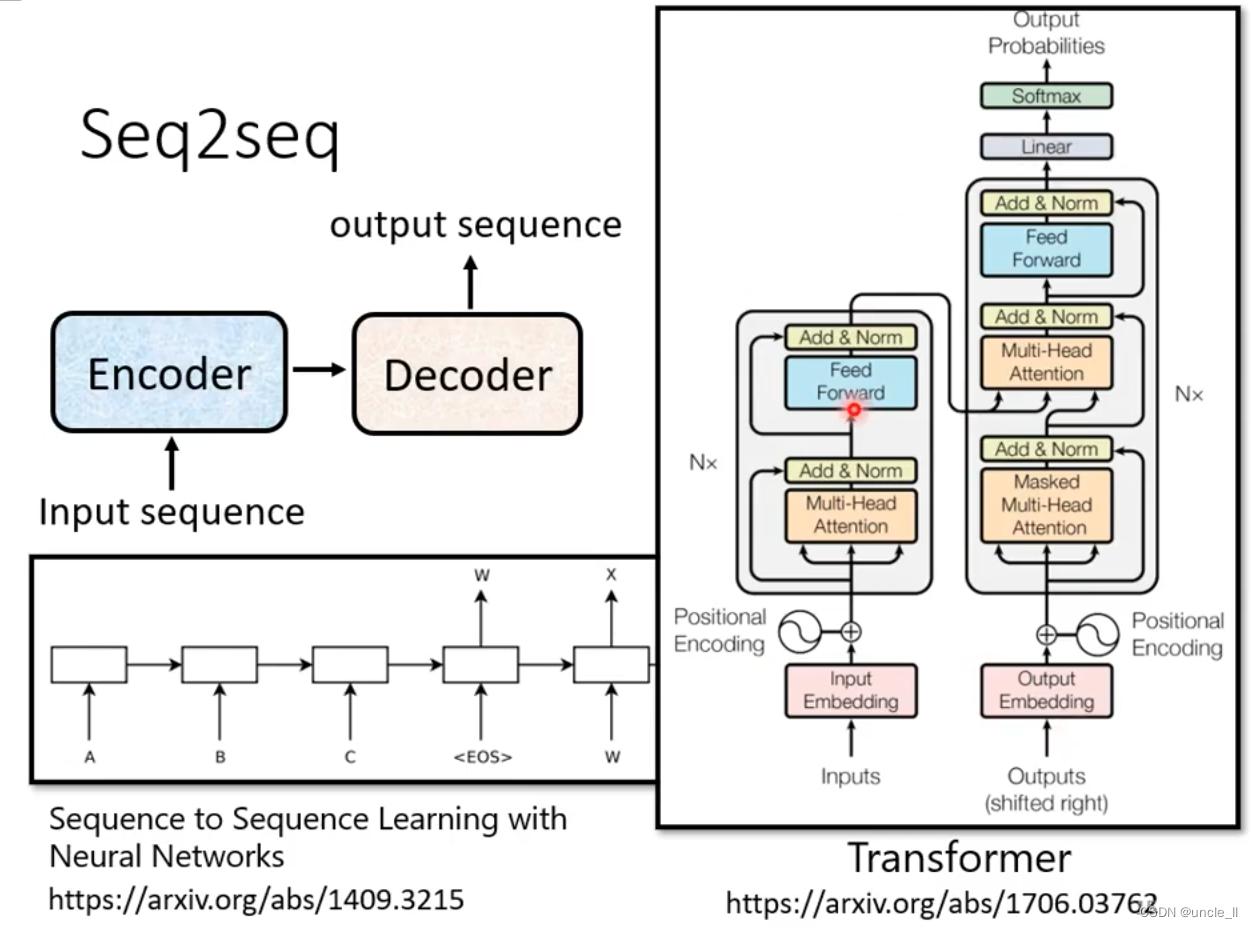
最早起源于14年,目前成熟结构是transformer结构。
Seq2seq’s Encoder
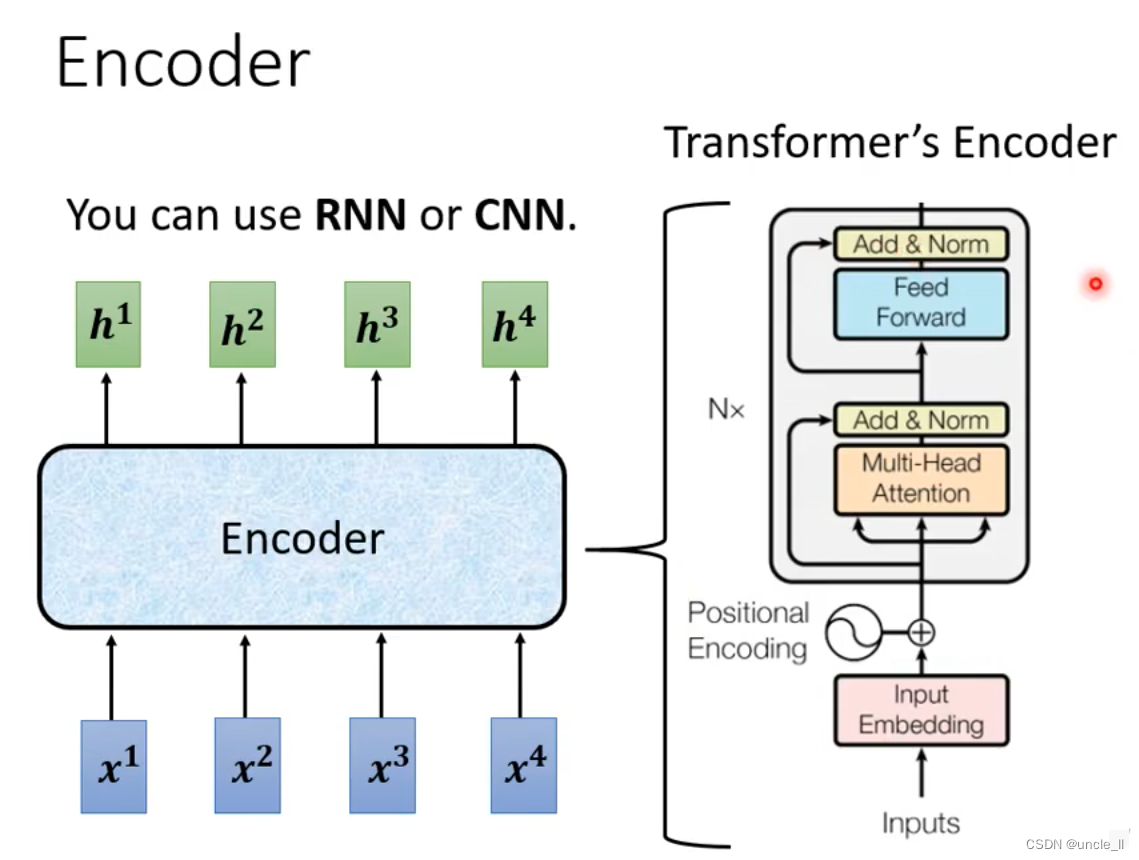
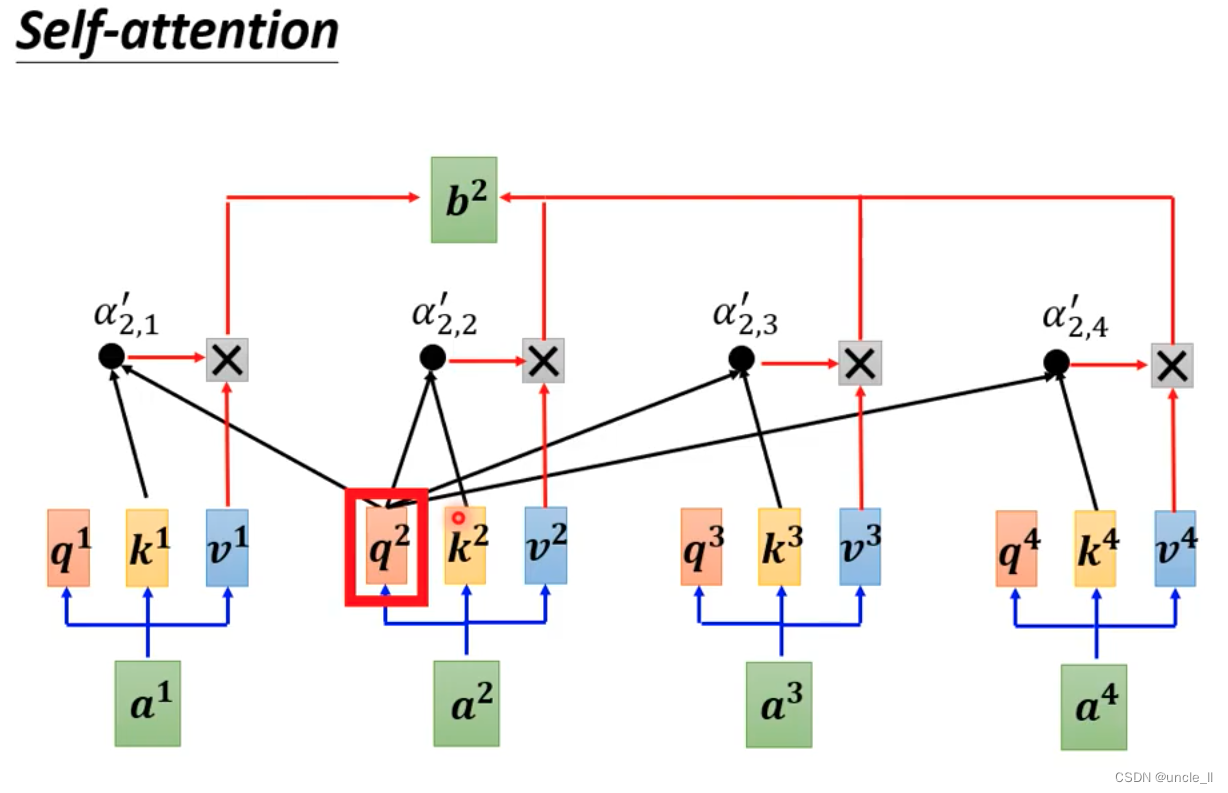
encoder的作用是将一个向量编码成另外一个向量,有很多部件都能完成该功能,比如self-attention,RNN,CNN,目前流行的是transformer。
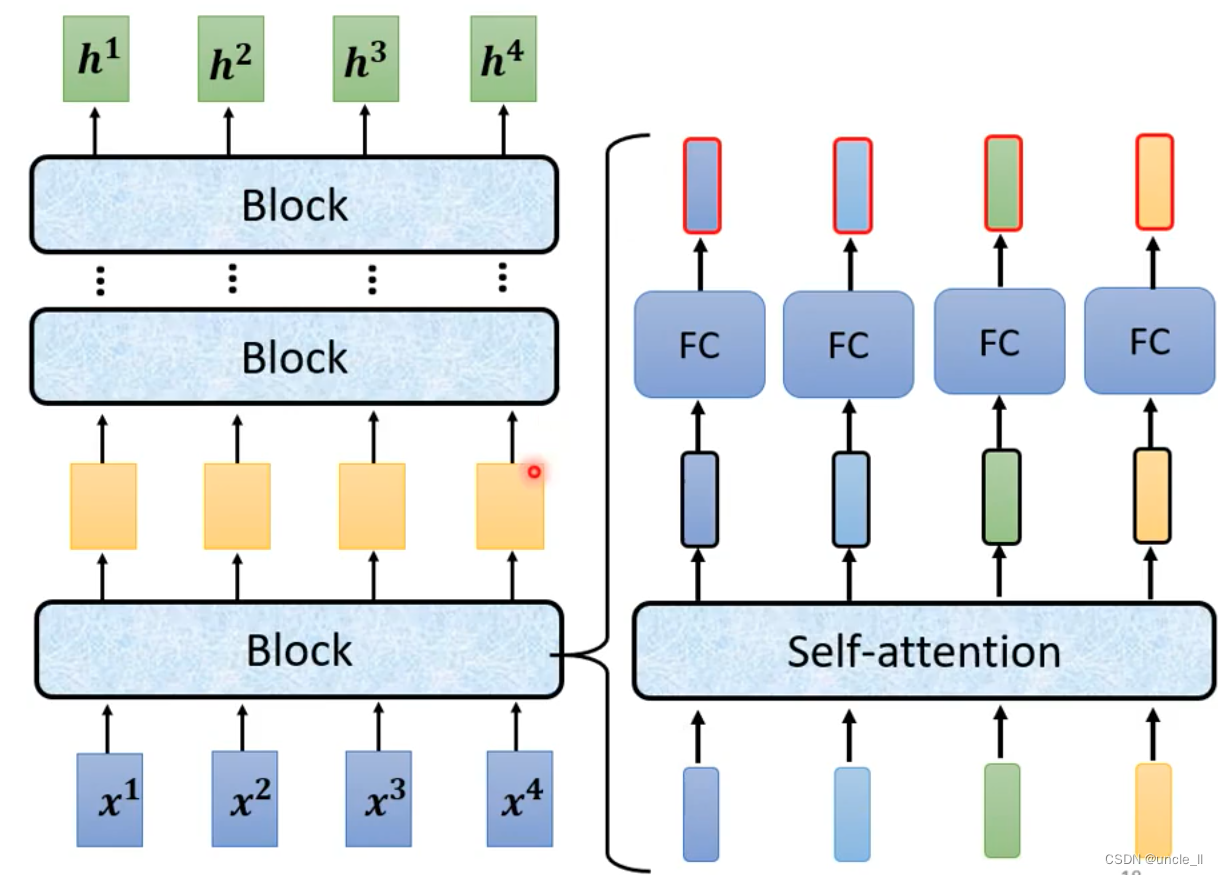
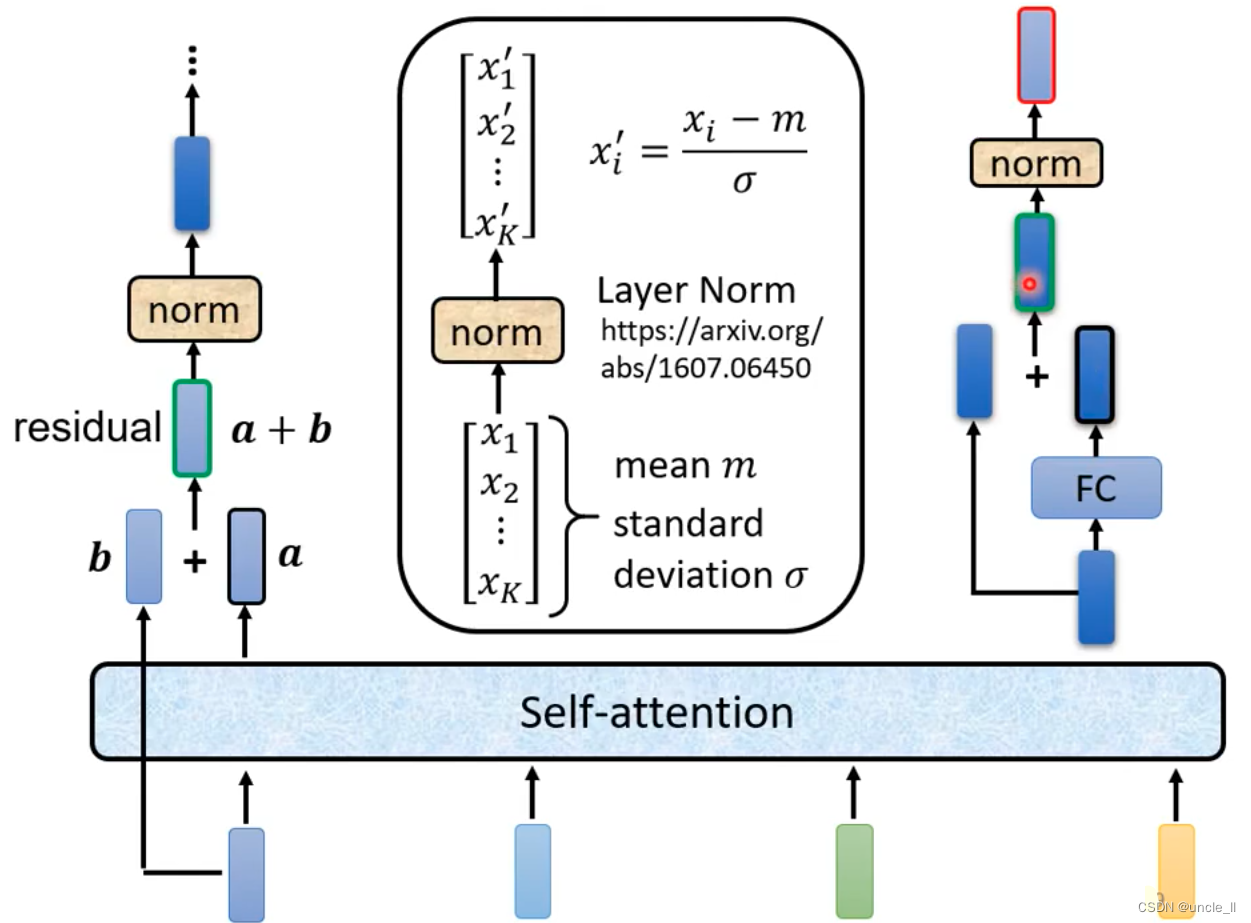
block中的过程要更加复杂一点,将block的输出与输入叠加送到下一层,类似于残差结构,然后进行normalizaition,使用的是layer norm, 对每一层计算均值和标准差。
有很多变体:
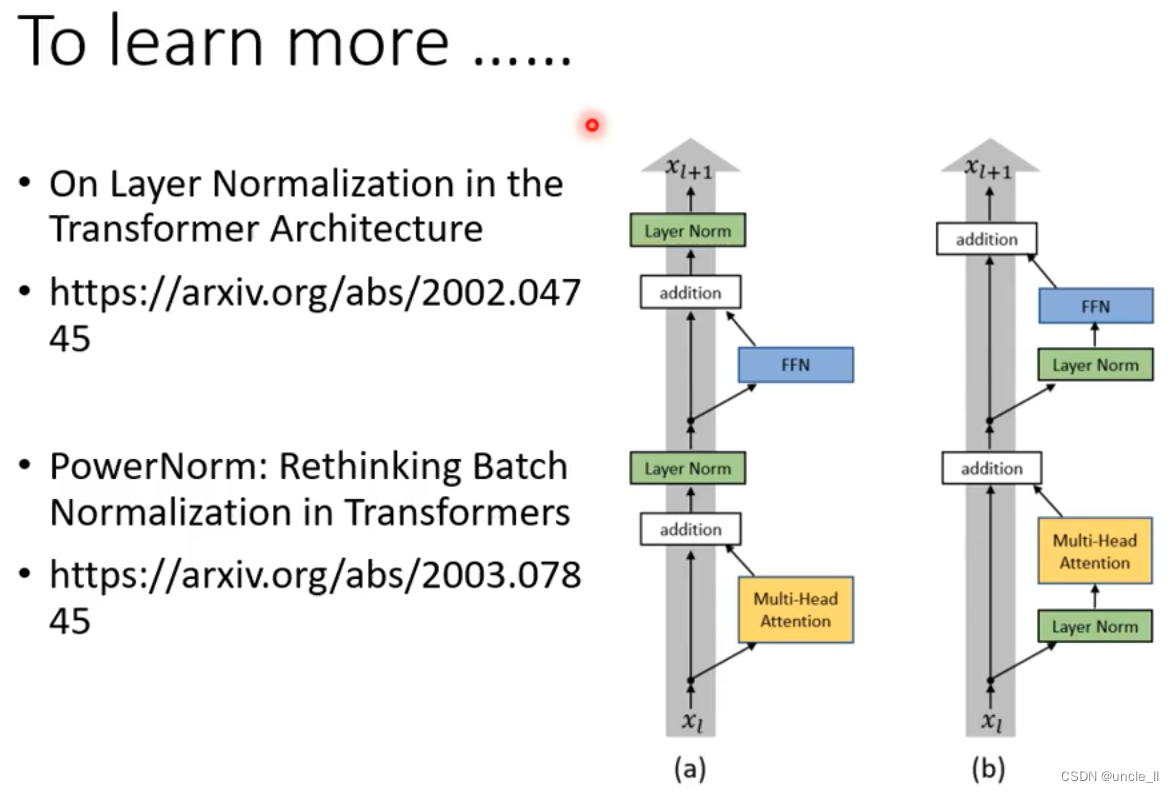
在transformer中,batch normalization表现没有layer normalization表现好,作者又提出了PowerNorm。
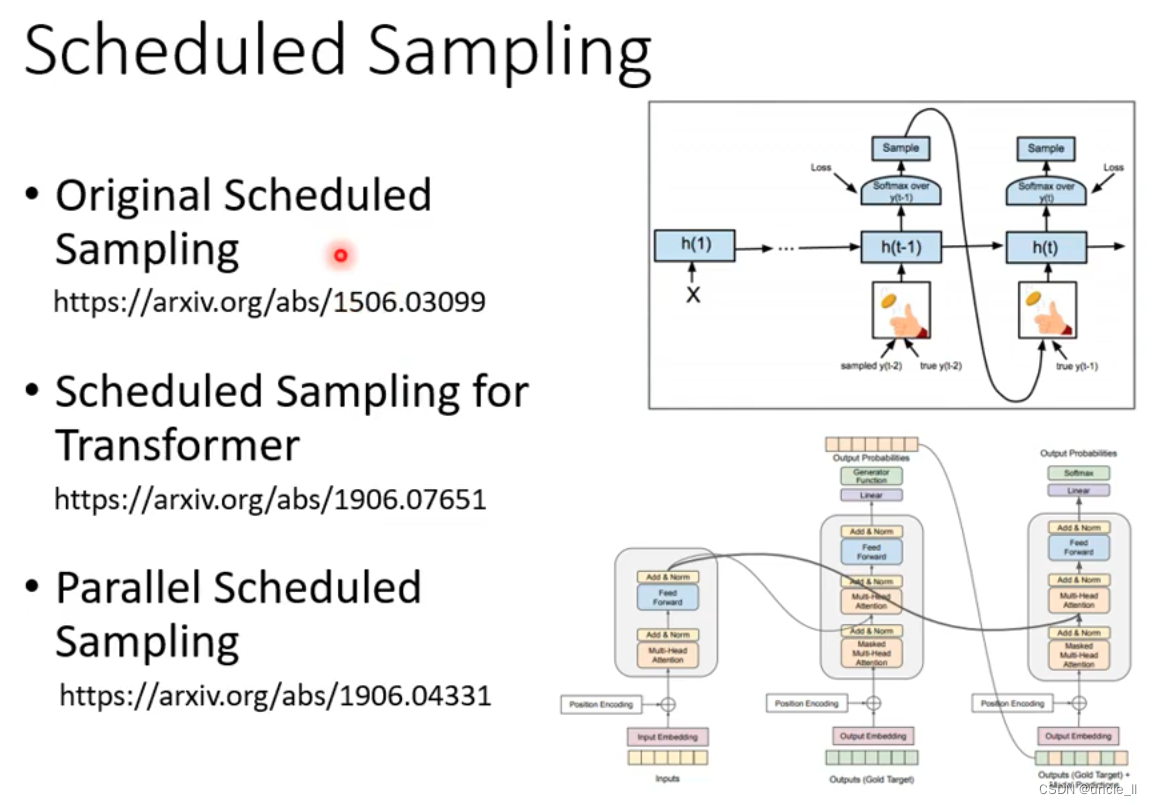
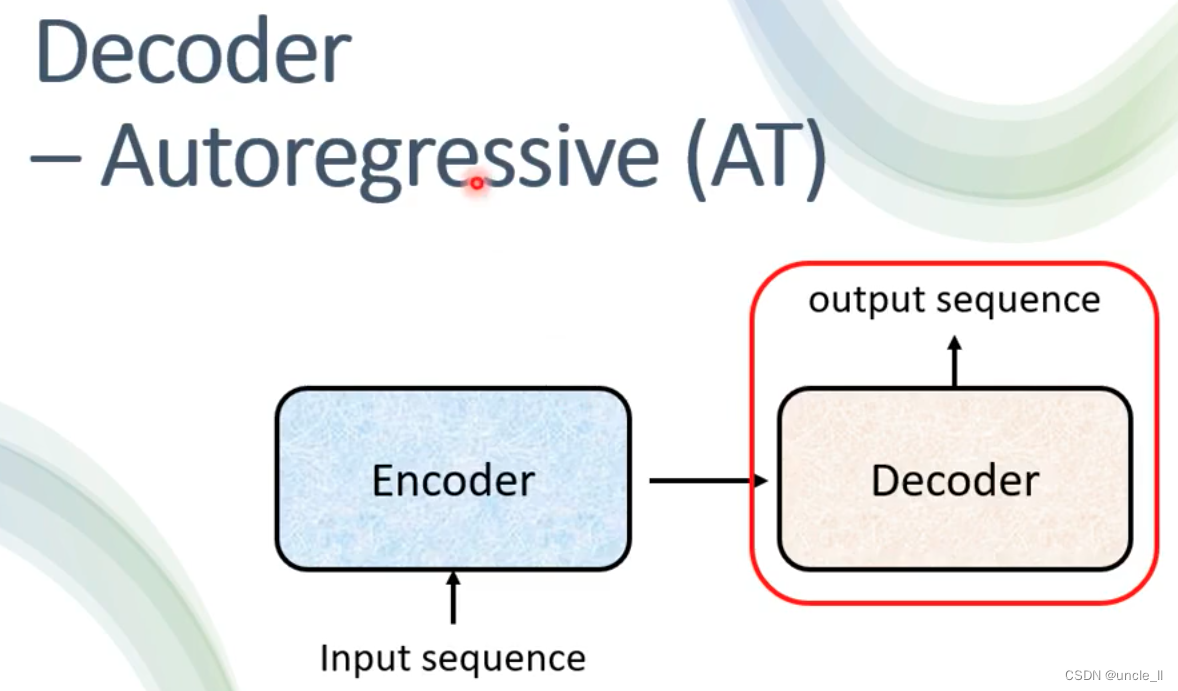
Decoder-Autoregressive(AT)
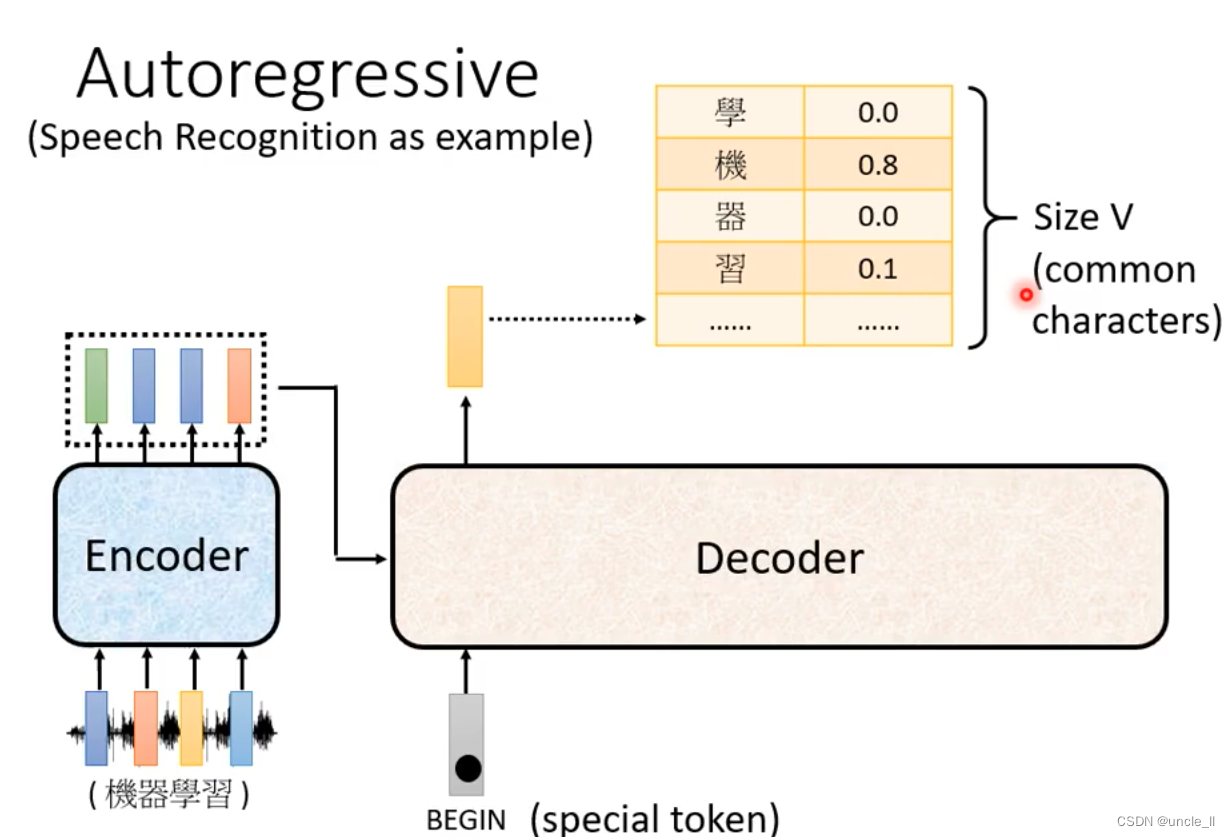
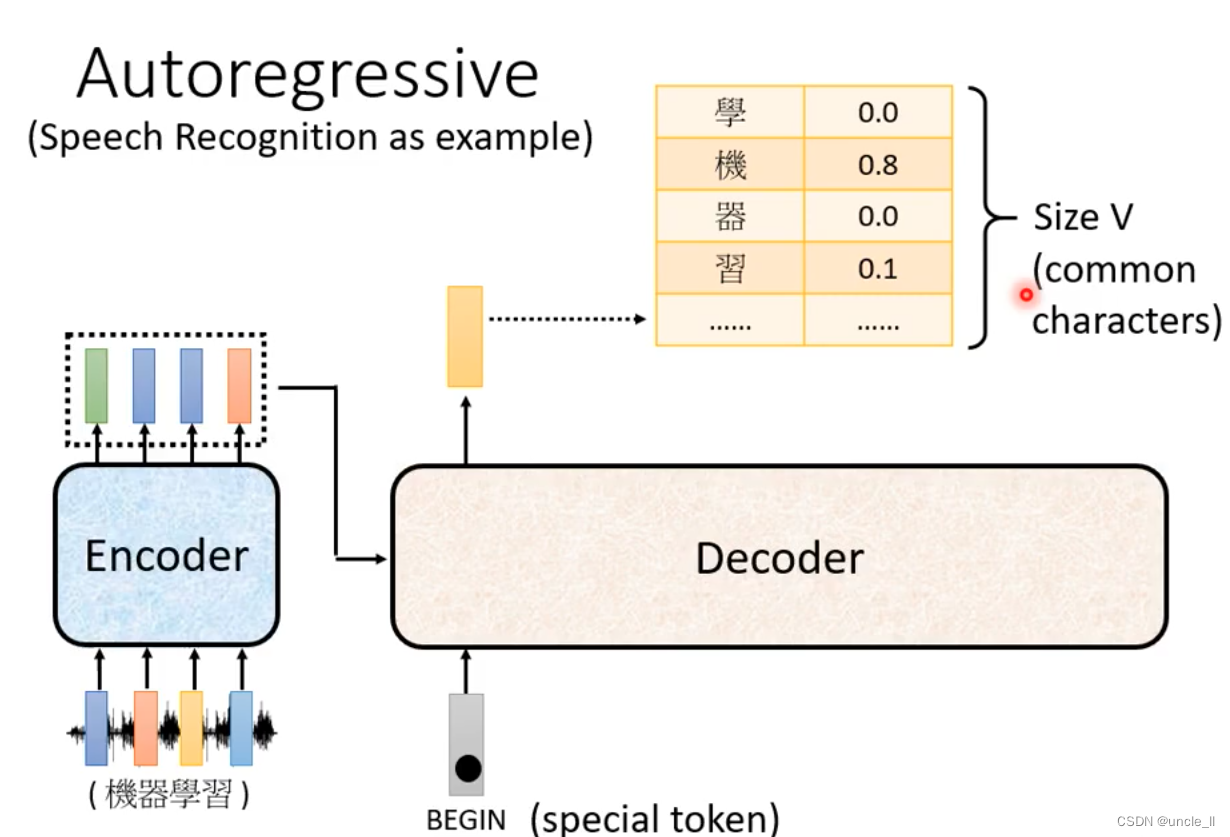
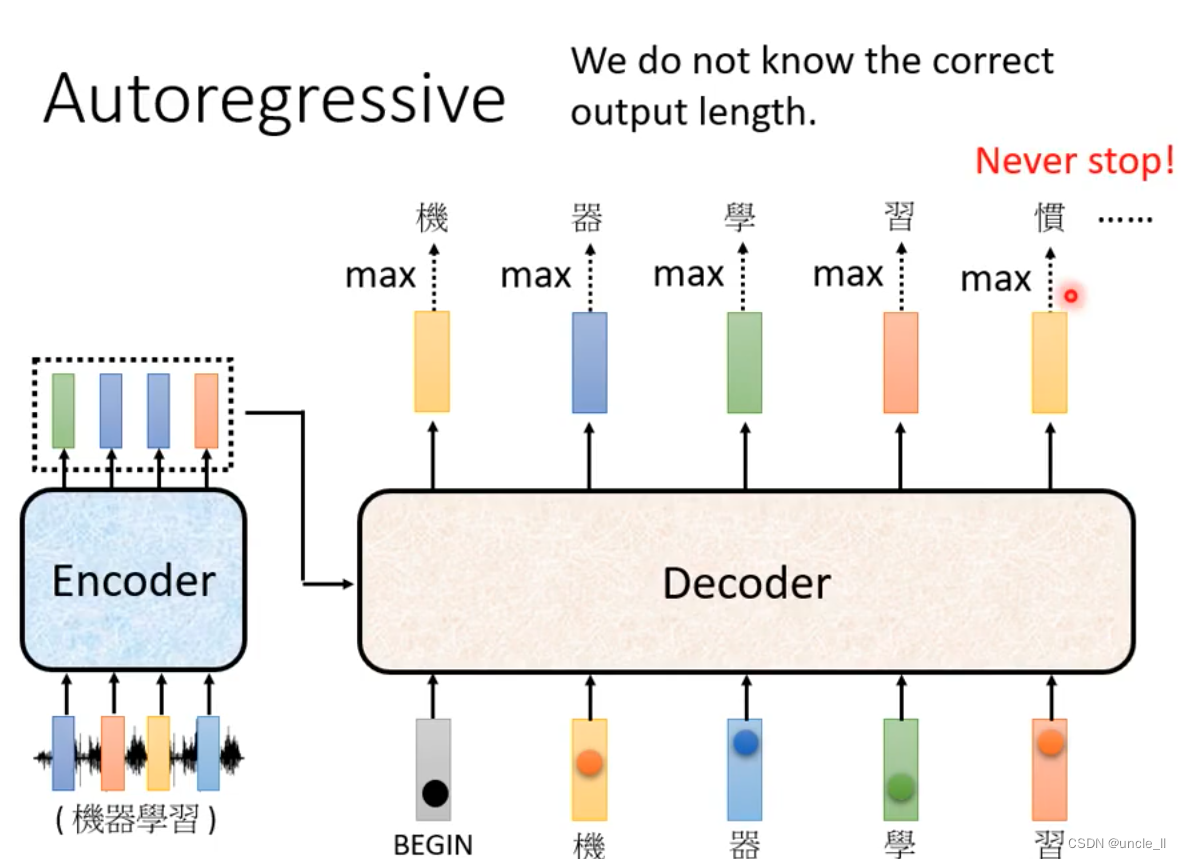
begin是special token,然后经过softmax得到最大分数的结果“机”, 基于这两个输入输出“器”。以此类推,输入变多,再预测输出。decode的输入是前一个的输出。
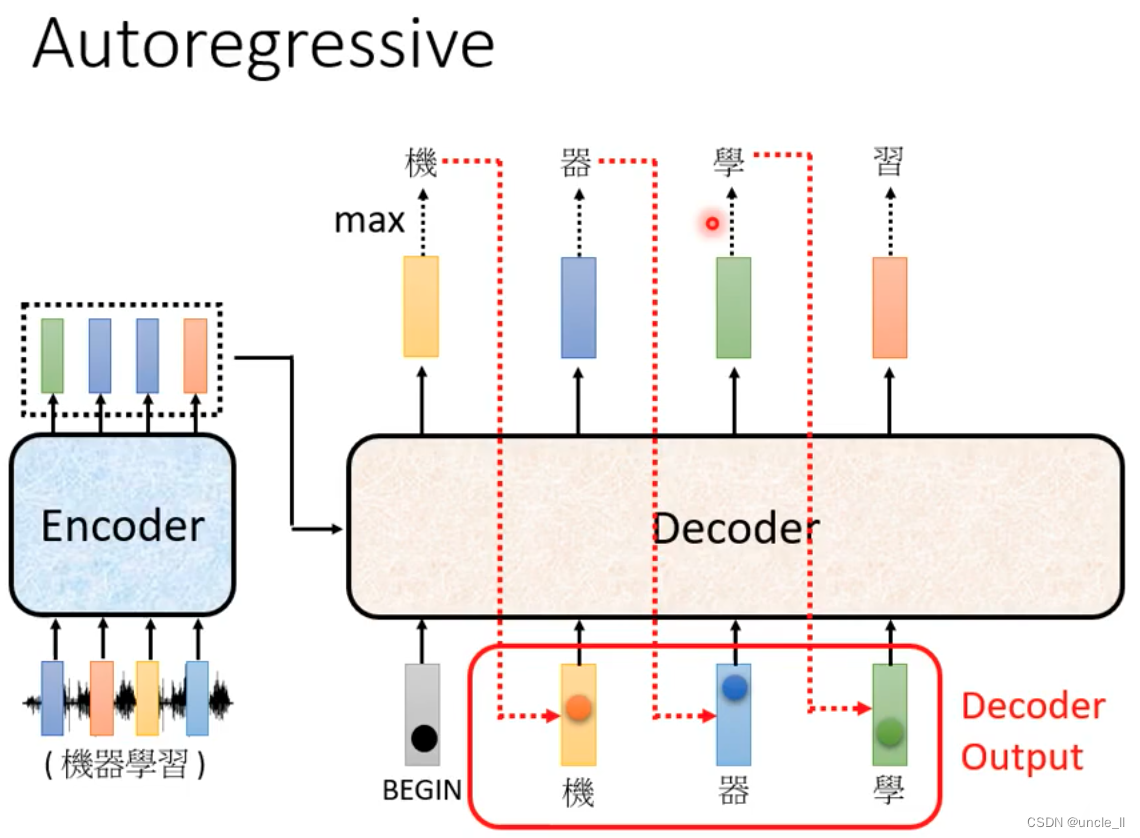
中间有可能识别错误导致输出变错,但是会继续往下传下去。
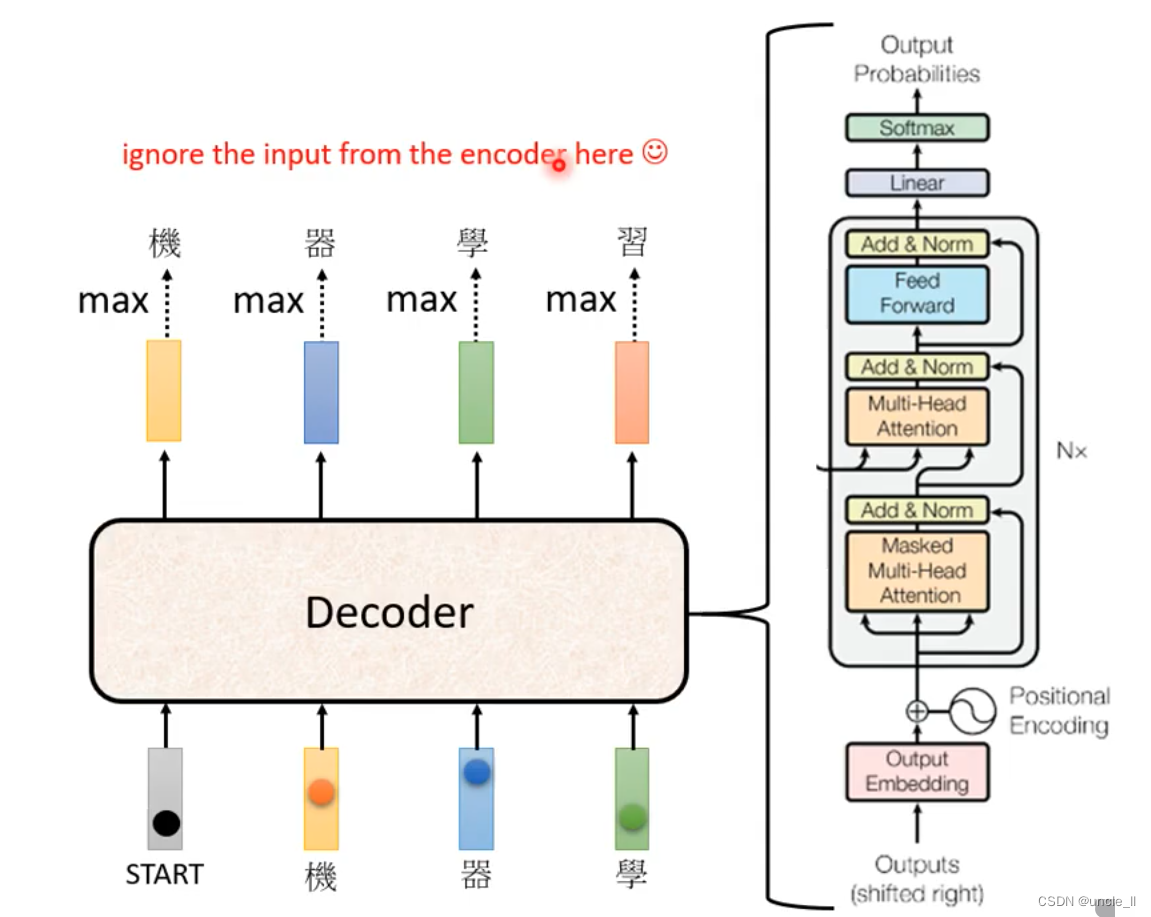
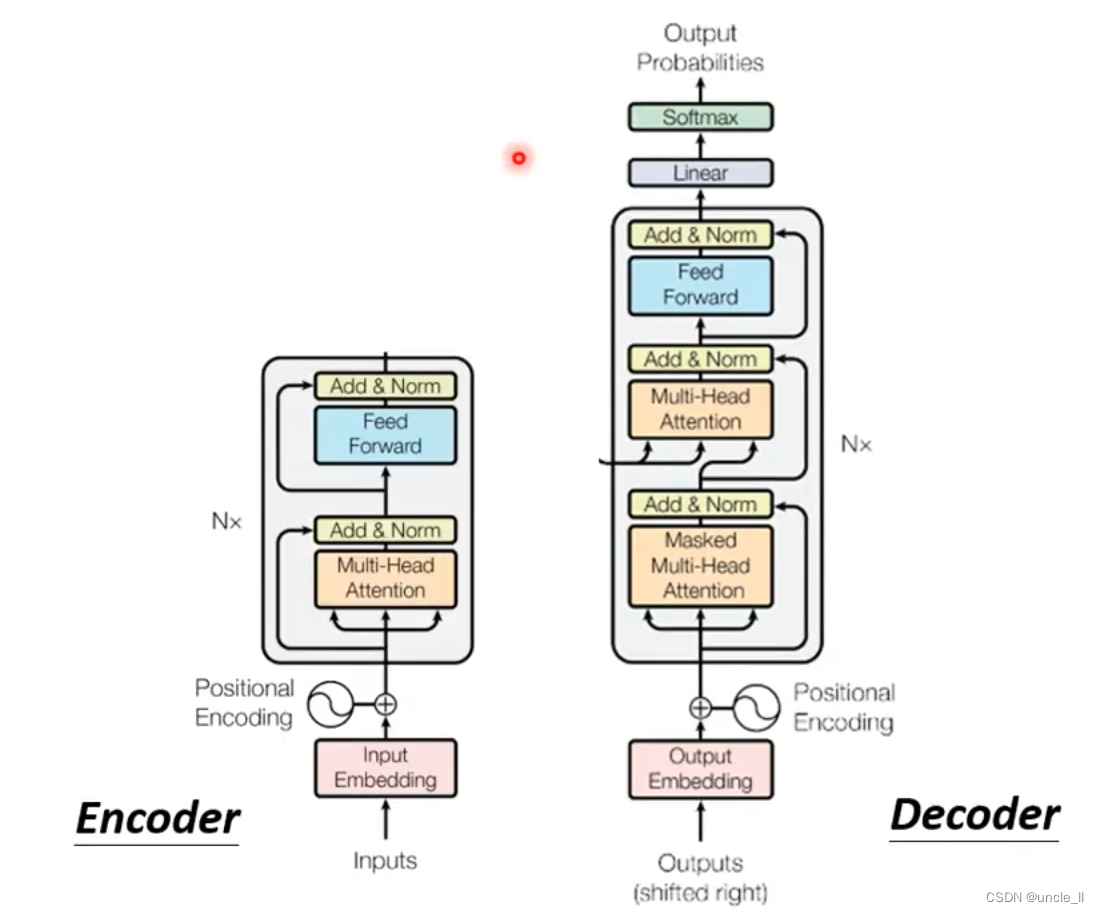
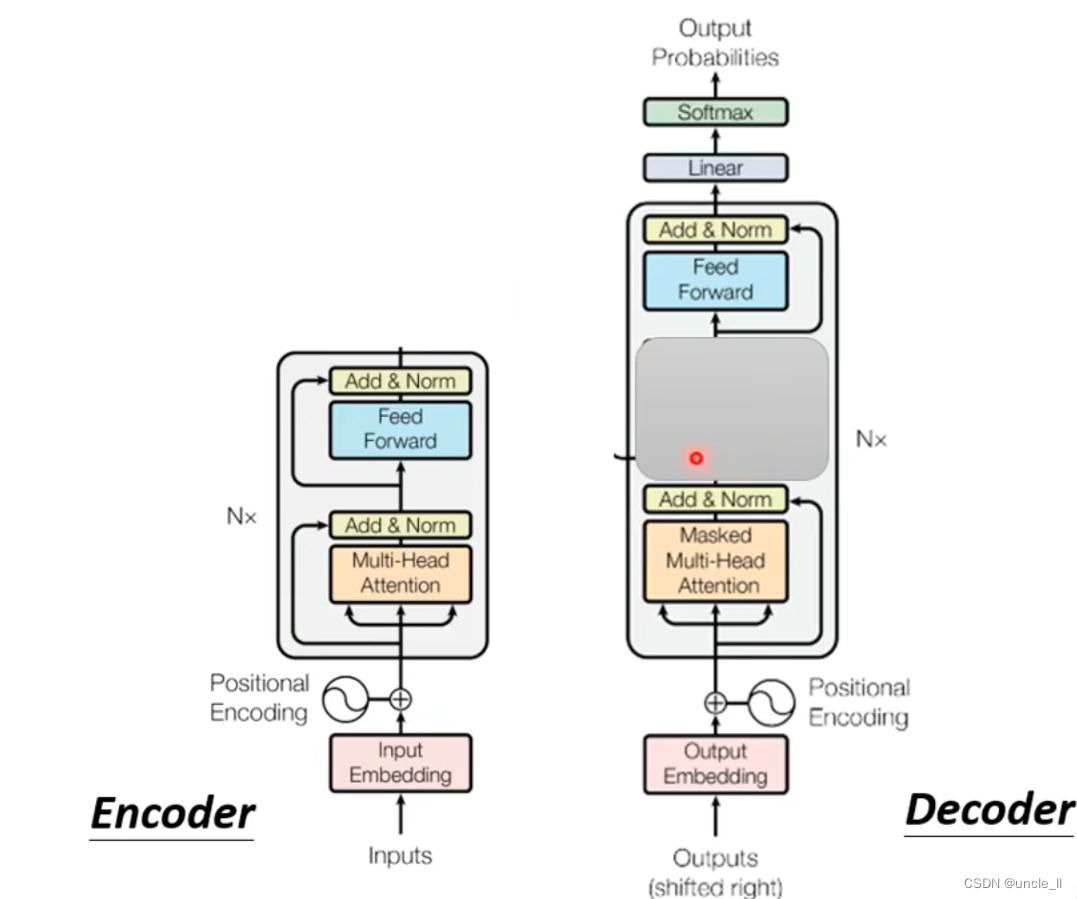
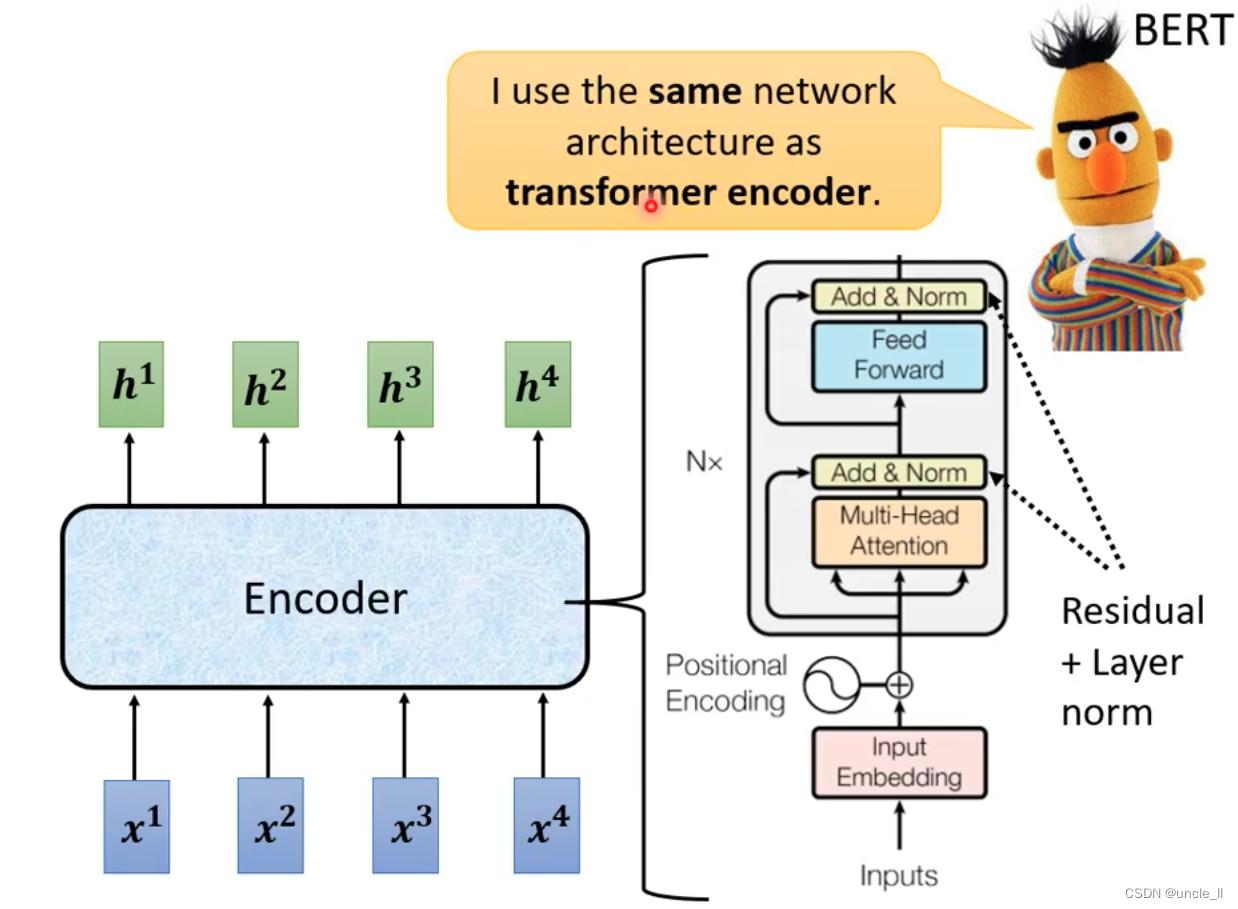
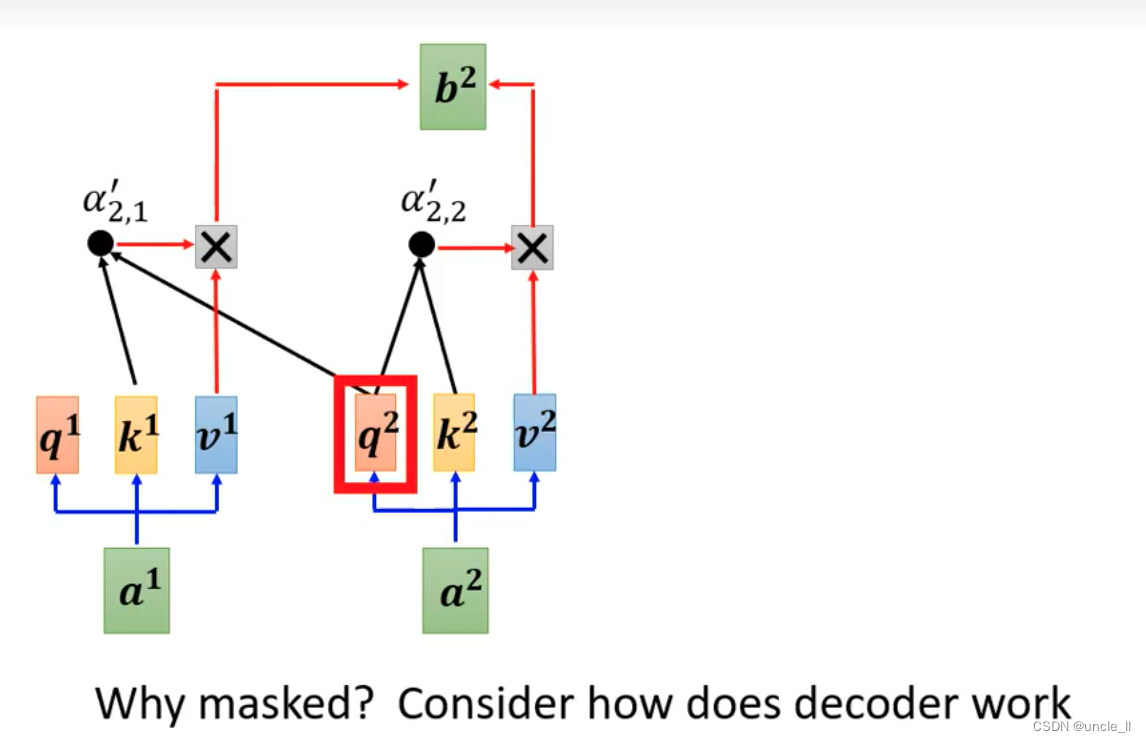
将decoder中间状态遮盖起来后,encoder和decoder是差不多,只是multi-head上面加了mask。
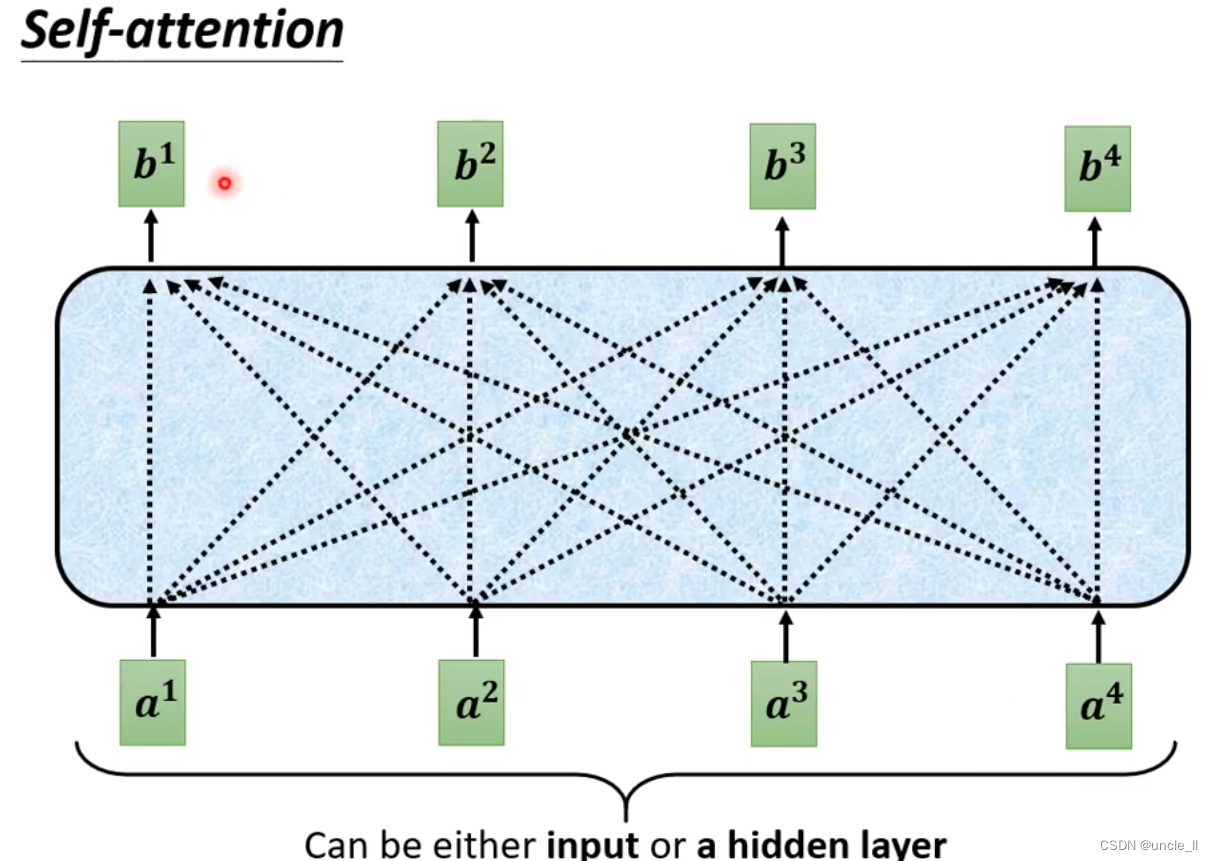
之前的self-attention得到的时候需要考虑所有的信息。现在变成masked-self-attention, 就是不能考虑右边的信息。
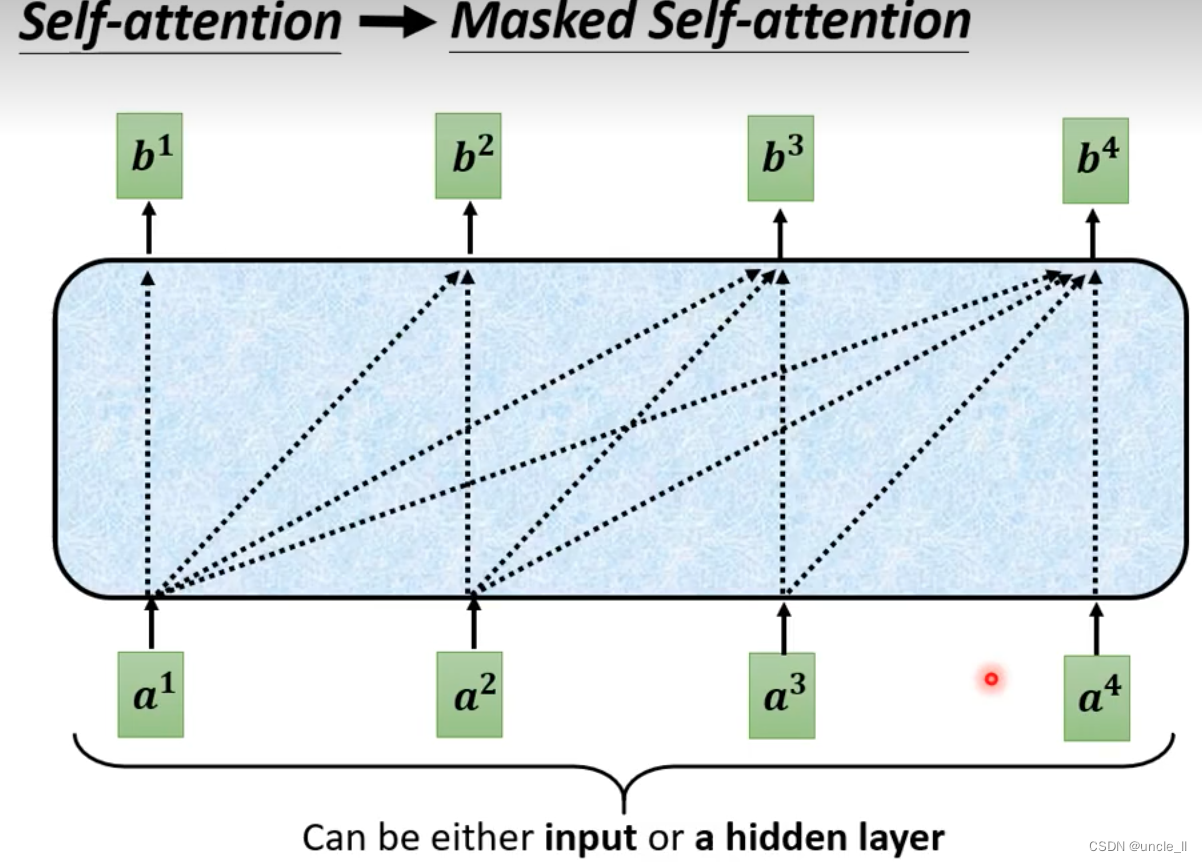
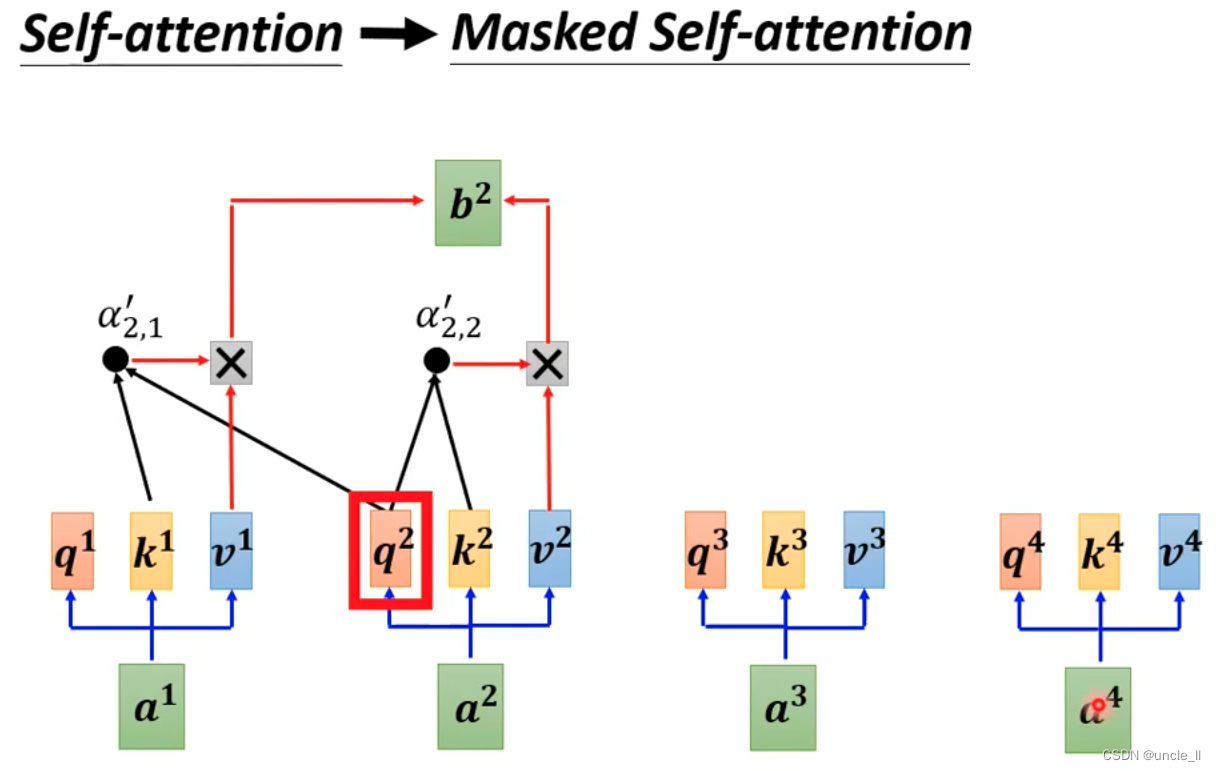
为什么要加masked,是计算a2时候不知道a3,a4…,没法考虑右边的信息。
另外不知道输出的正确长度。

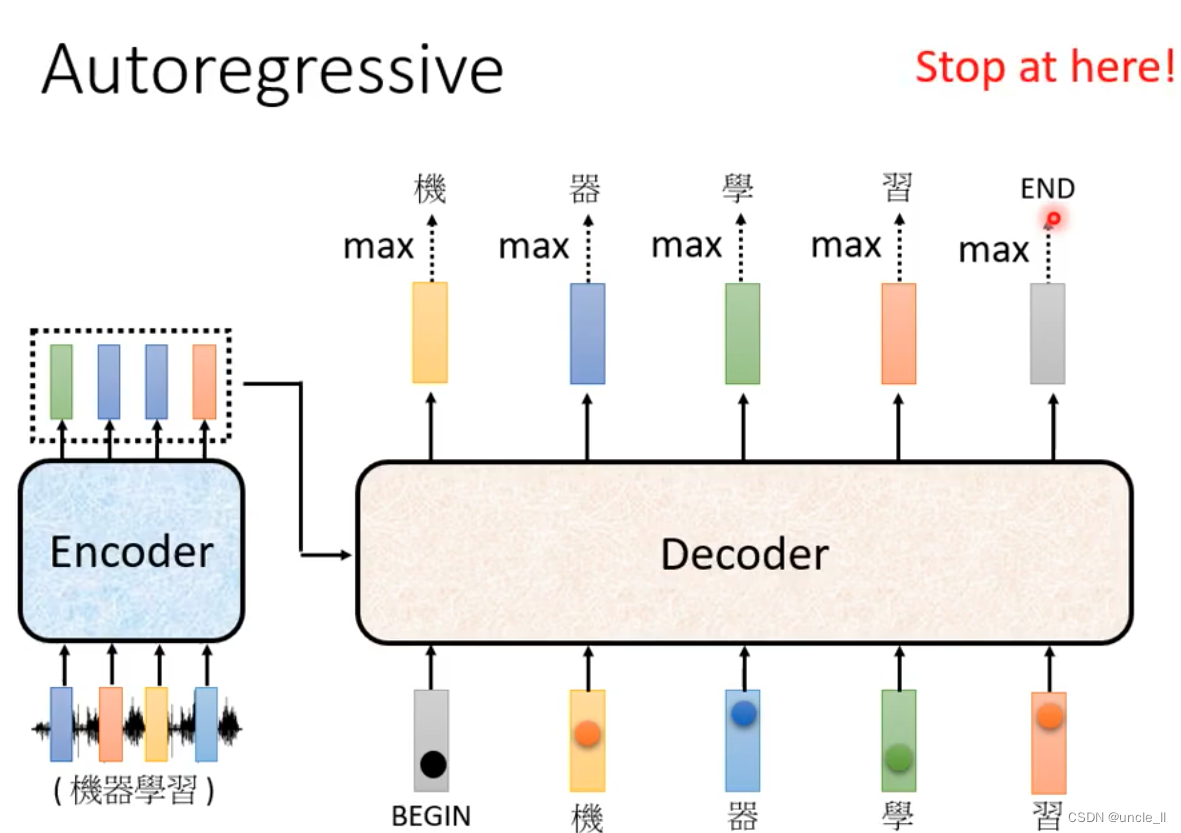
增加一个stop token 让其不一直无限推理下去。
Decoder-Non-autoregressive(NAT)
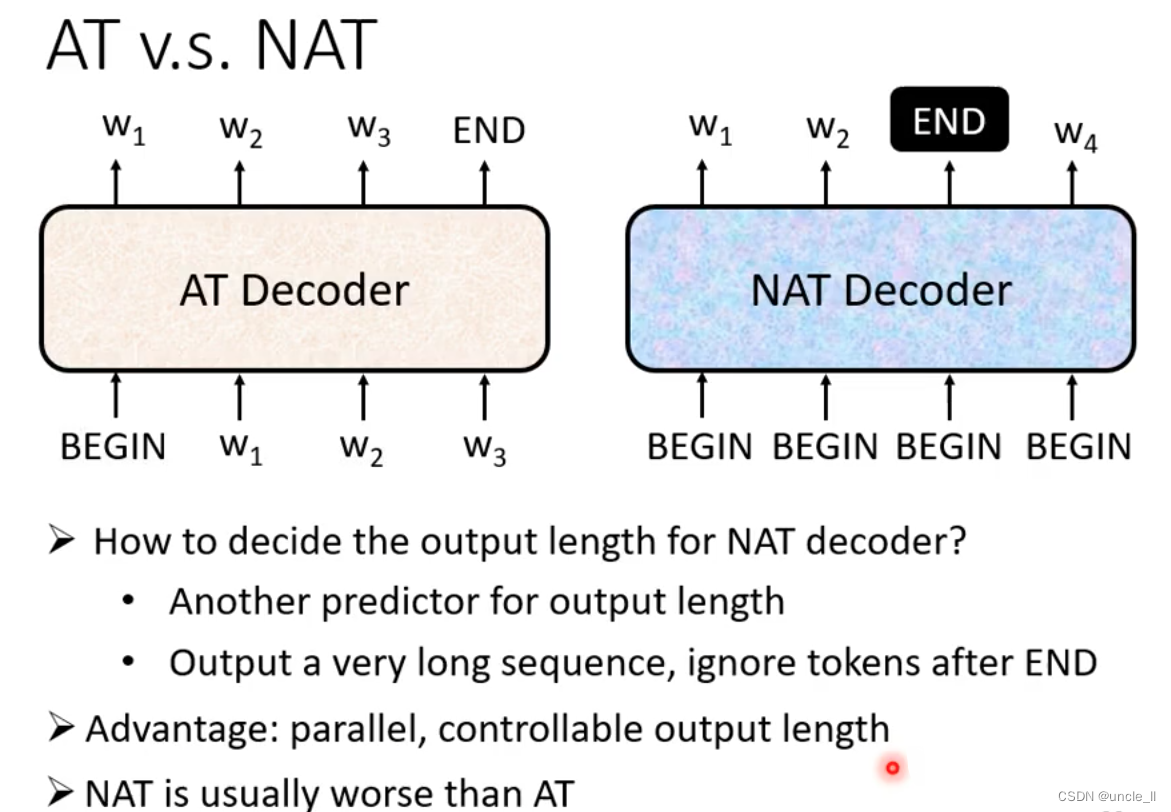
NAT不知道什么时候停,有两种方式:
- 训练一个长度分类器
- 直接输出,如果遇到end就忽略后续的结果
好处就是并行化,能一下子输出结果,比较能够控制输出的长度,但实际应用上一般而言NAT的效果比AT的效果要差,原因是Multi-modality。
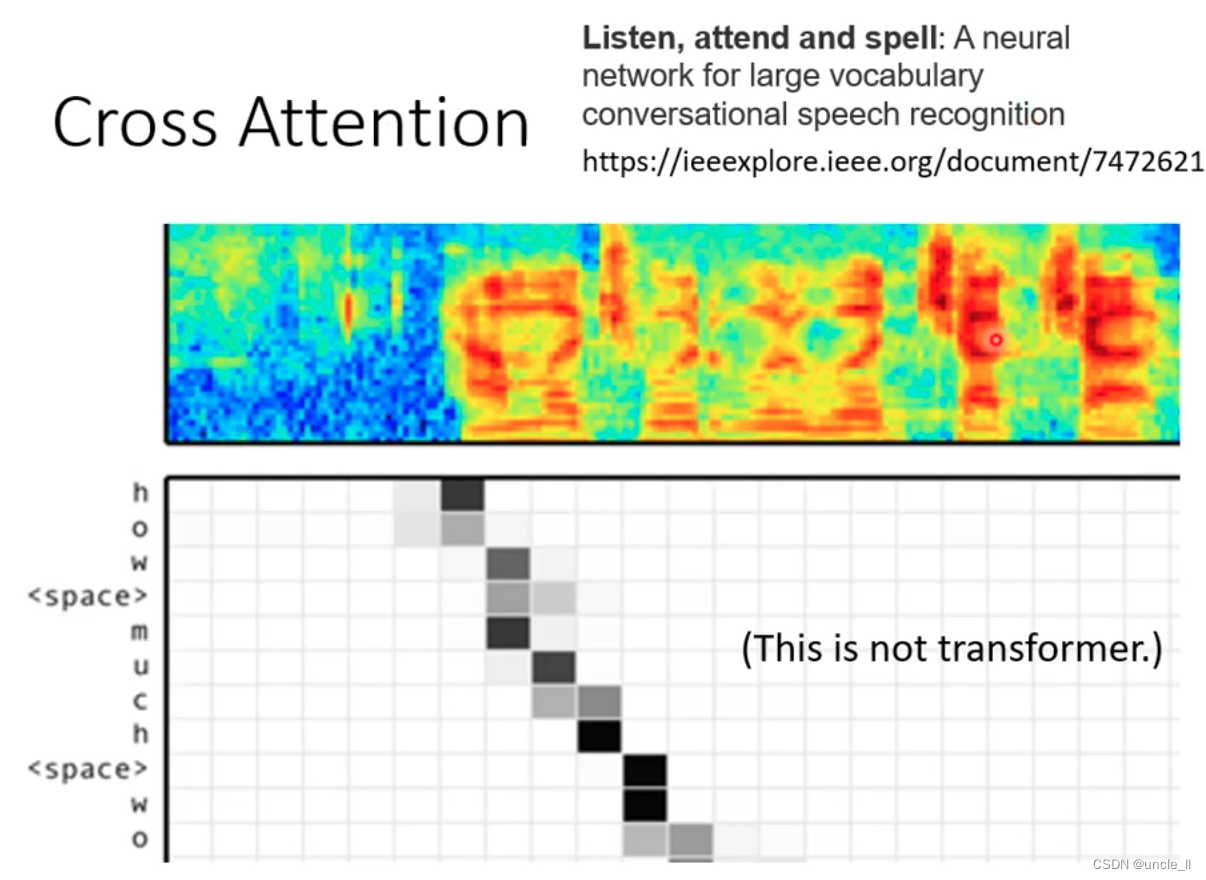
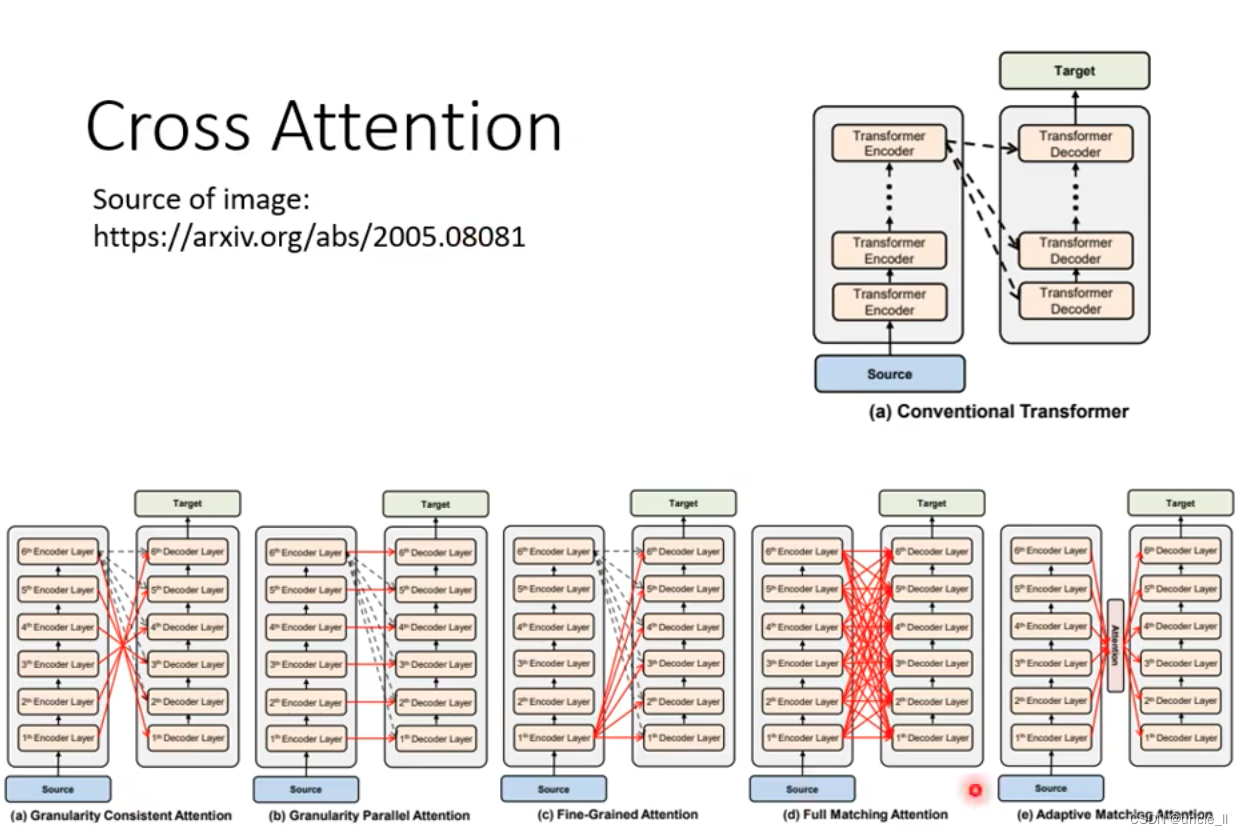
Cross attention
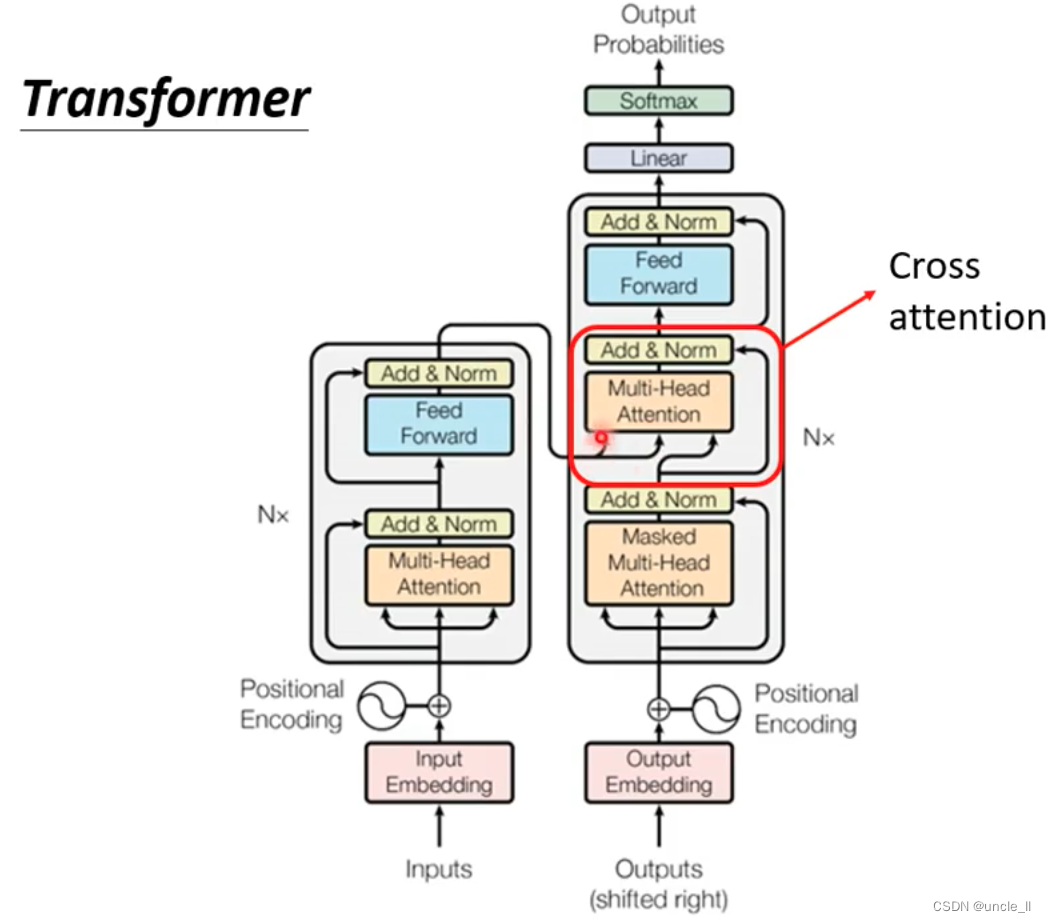
encoder和decoder连接,通过cross attention进行连接
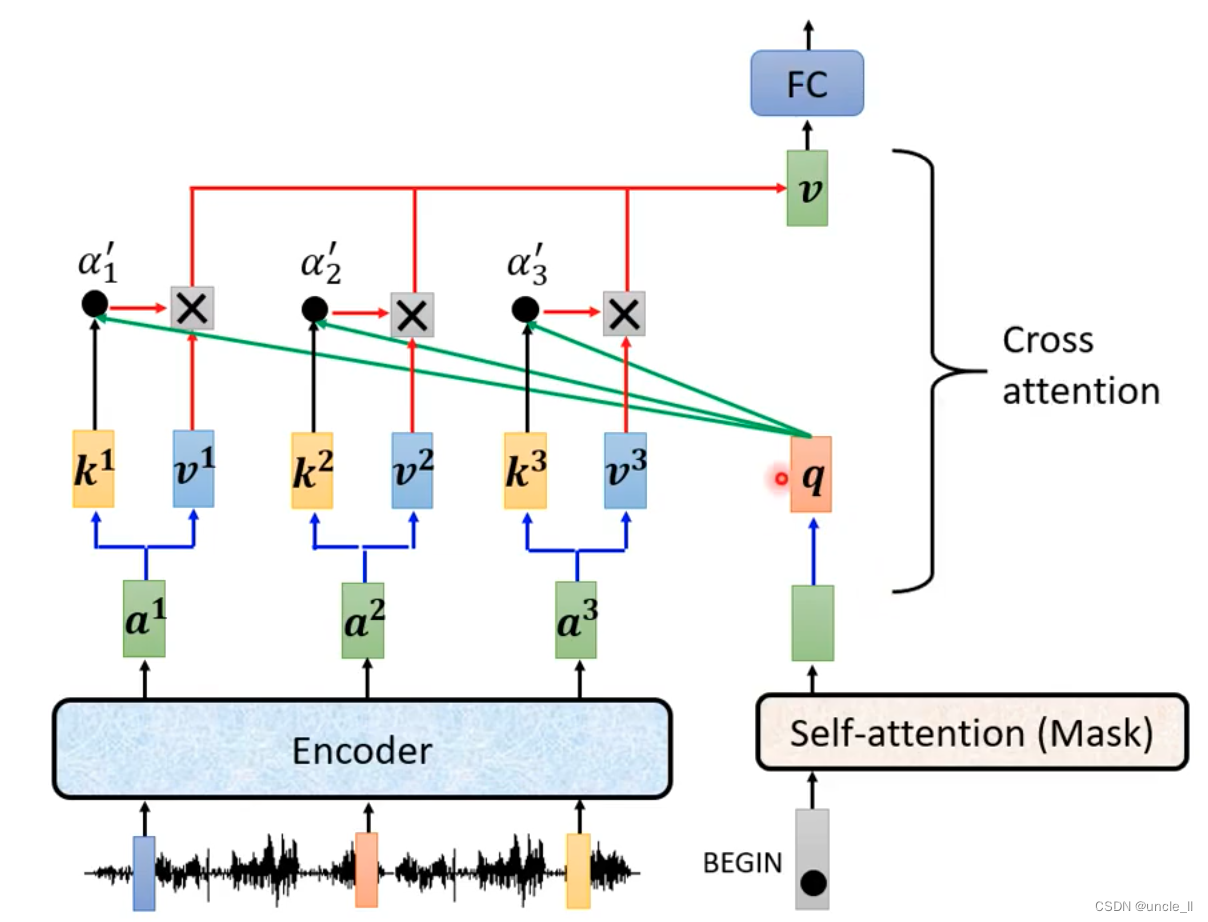
kv来自encoder,q来自decoder。
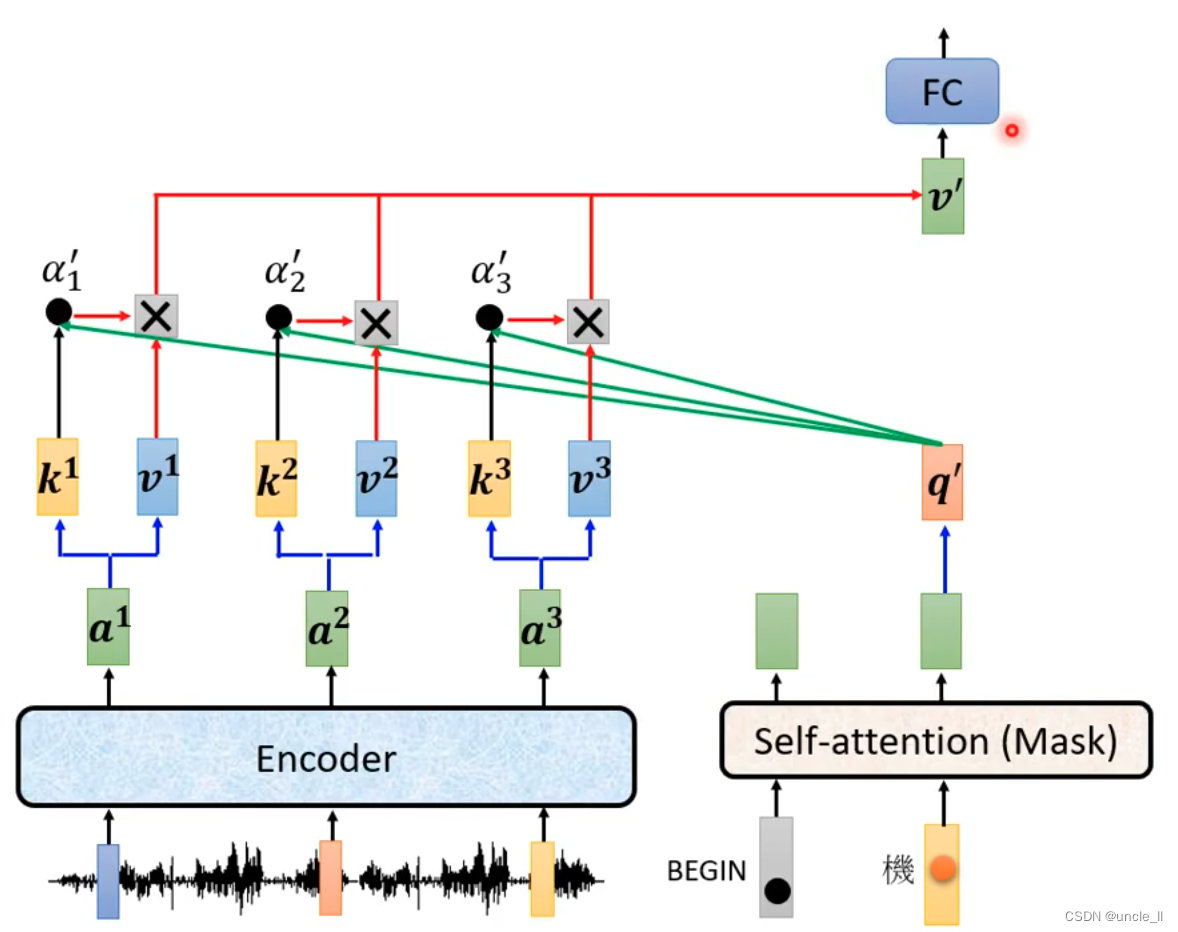
Train
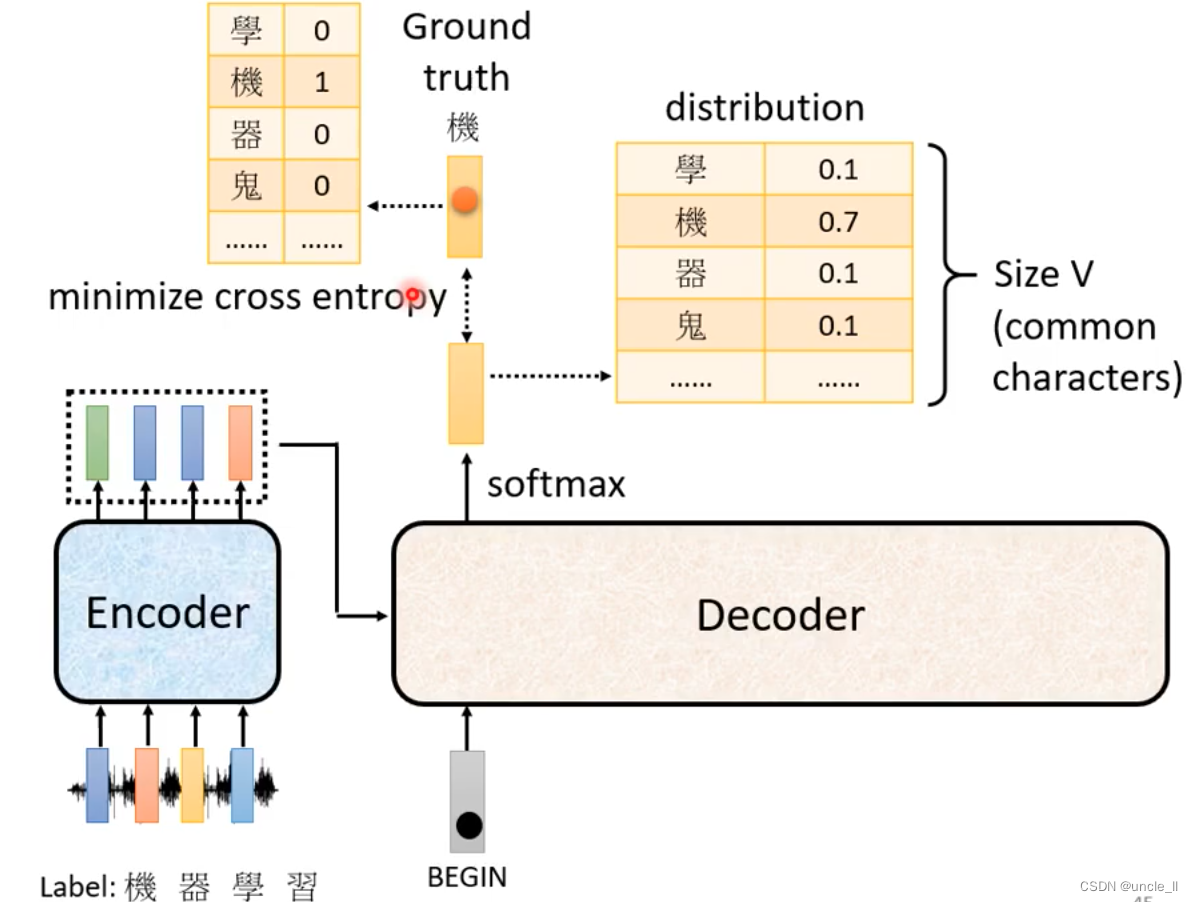
每次decoder产生中文字时候做了一次分类问题。
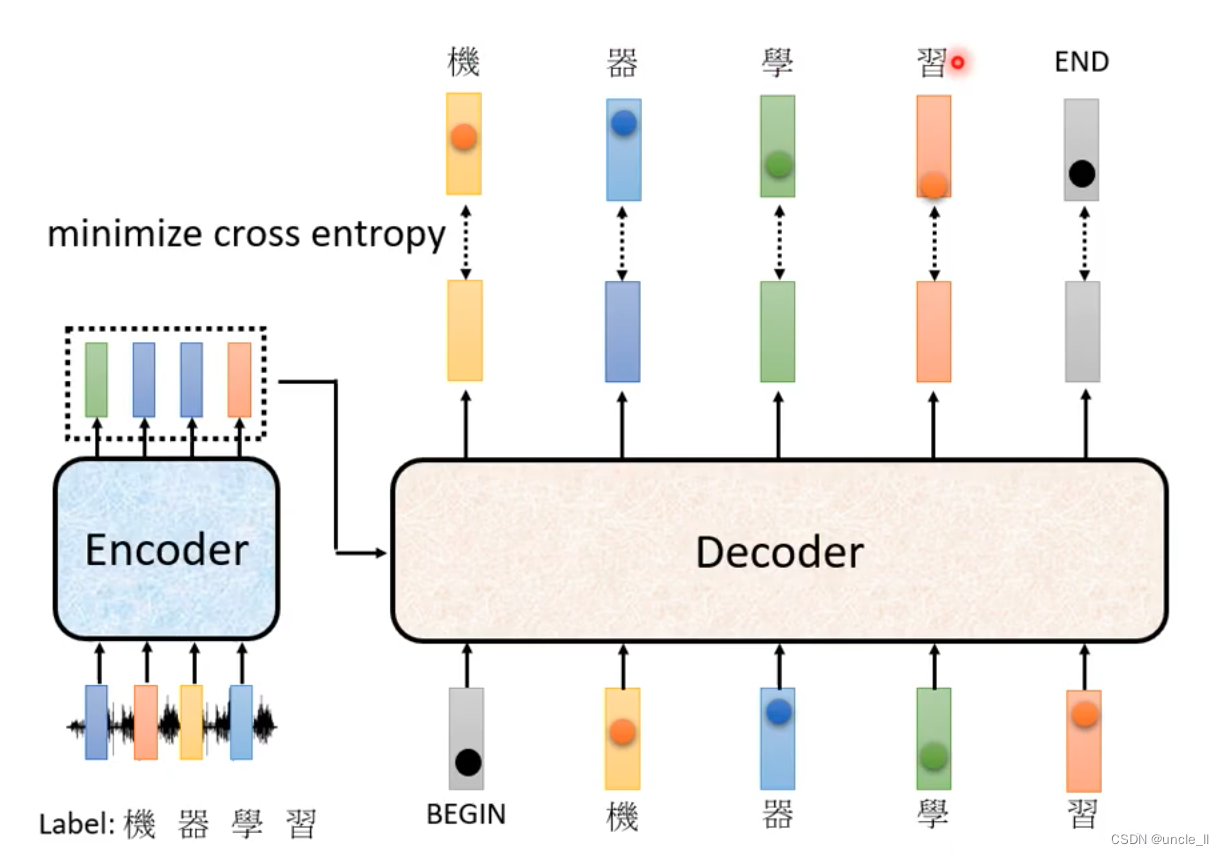
每一个输出都会有cross entropy,所有的cross entropy的总和最小。
end也会参与计算。
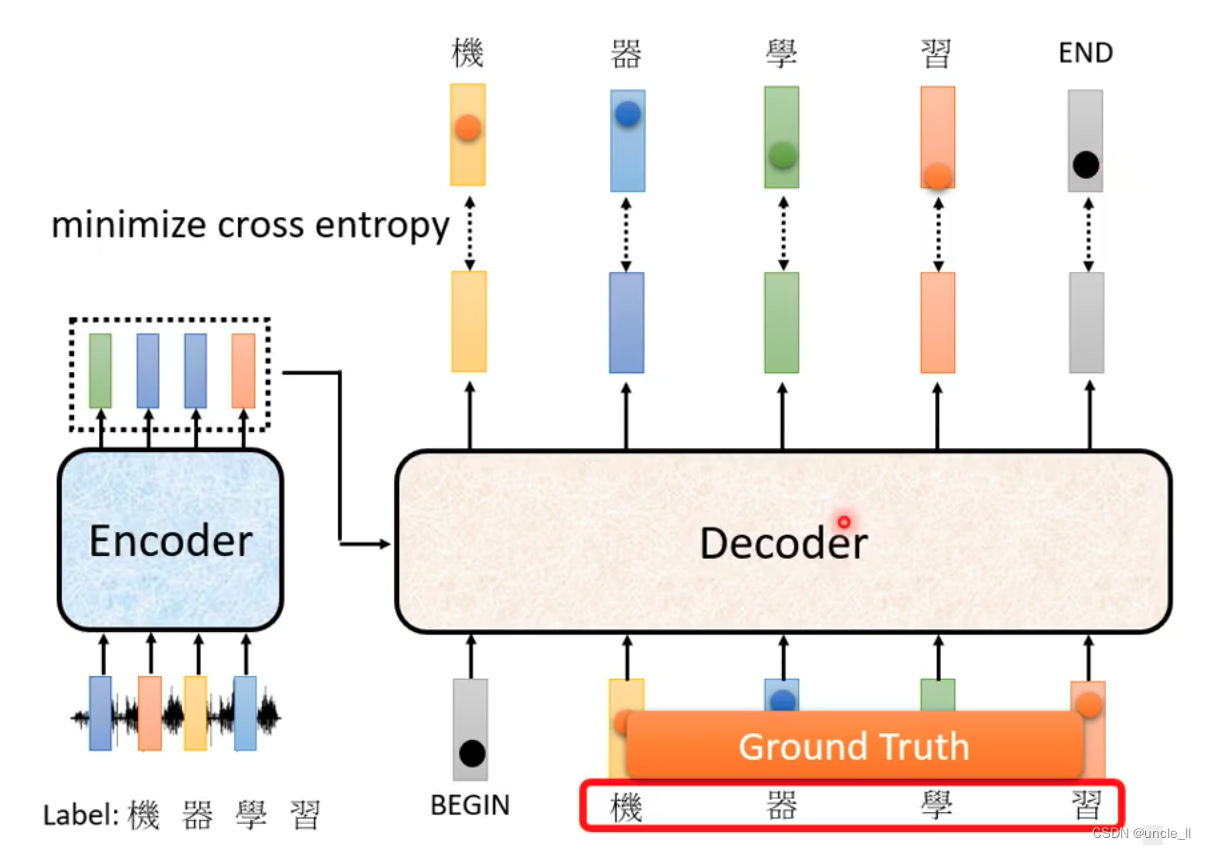
输入的时候是给的正确答案,teacher forcing,正确答案当作decoder的输入。
Tips
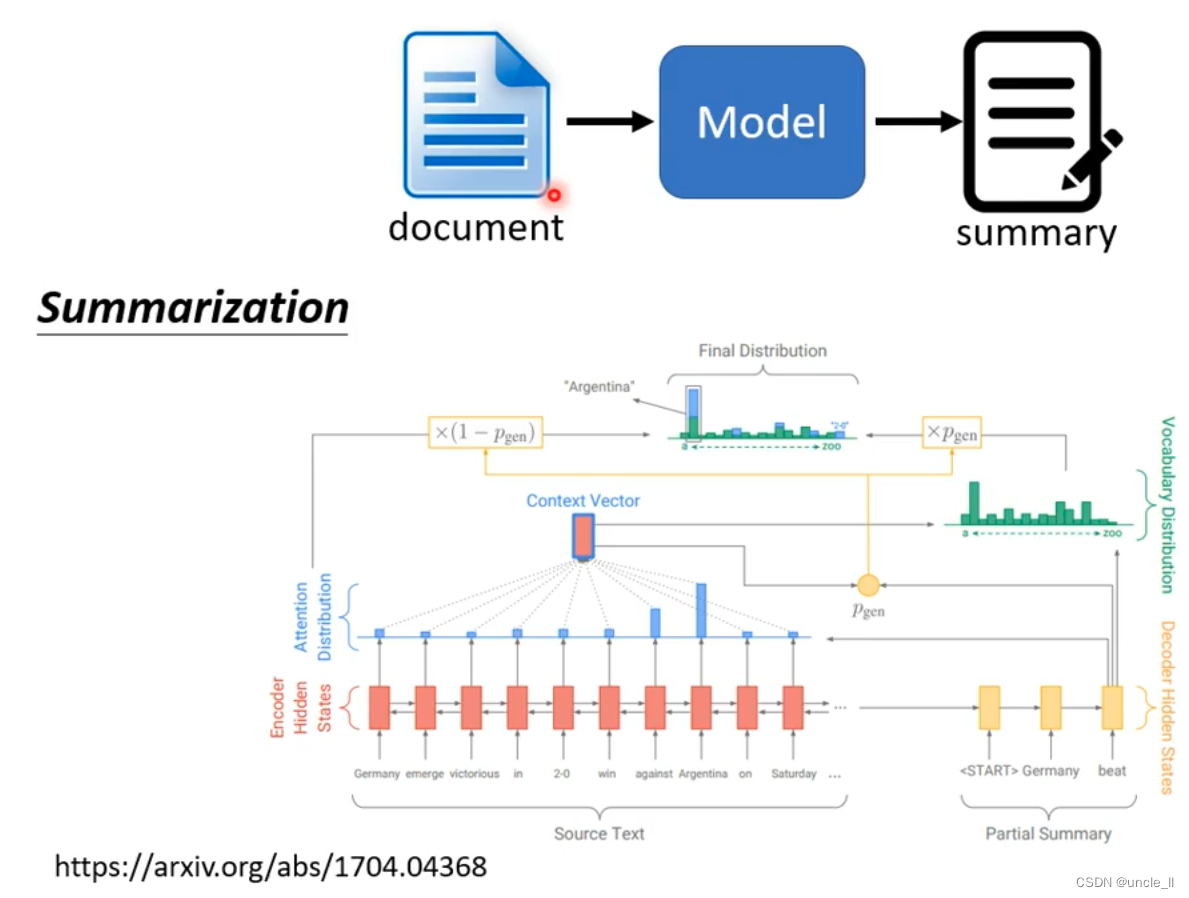
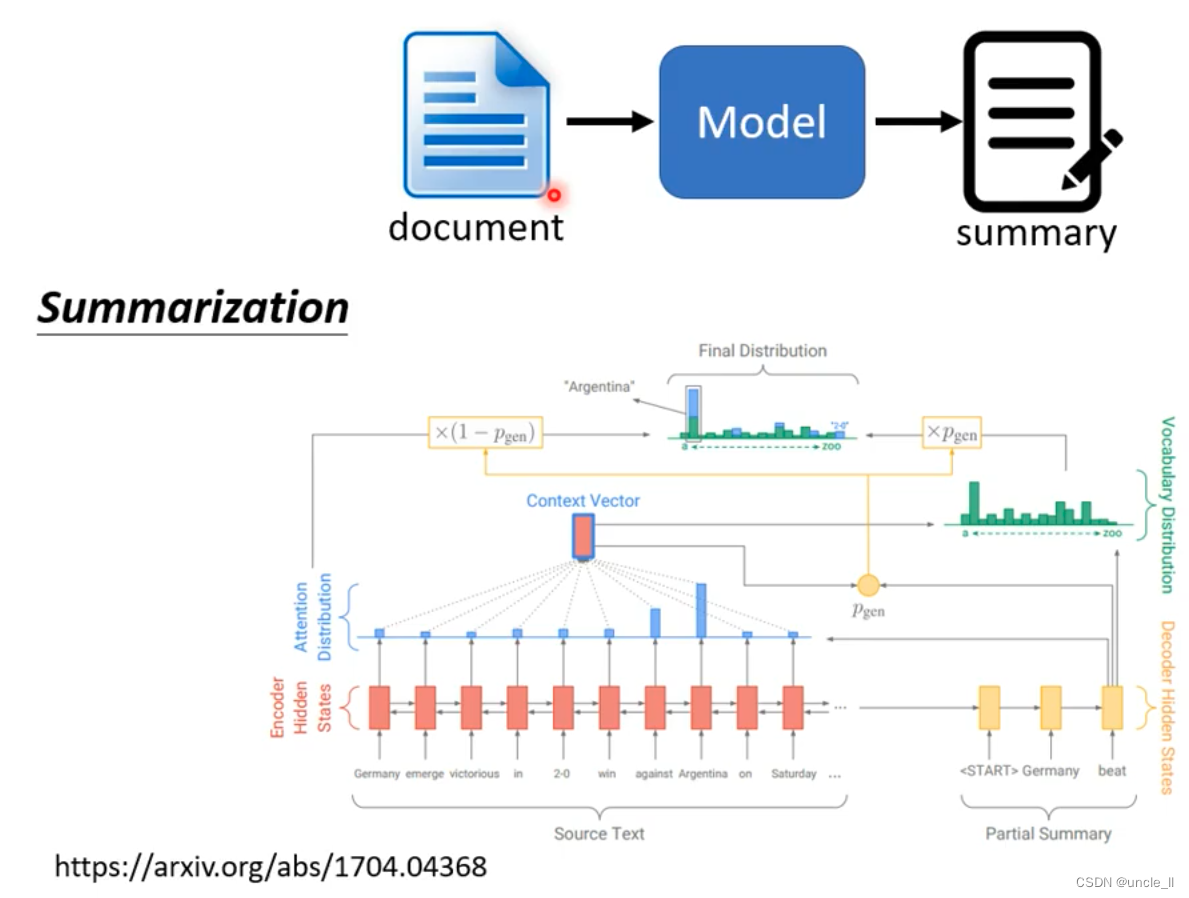
Copy Mechanism
- char-bot

- summarization
Guided Attention
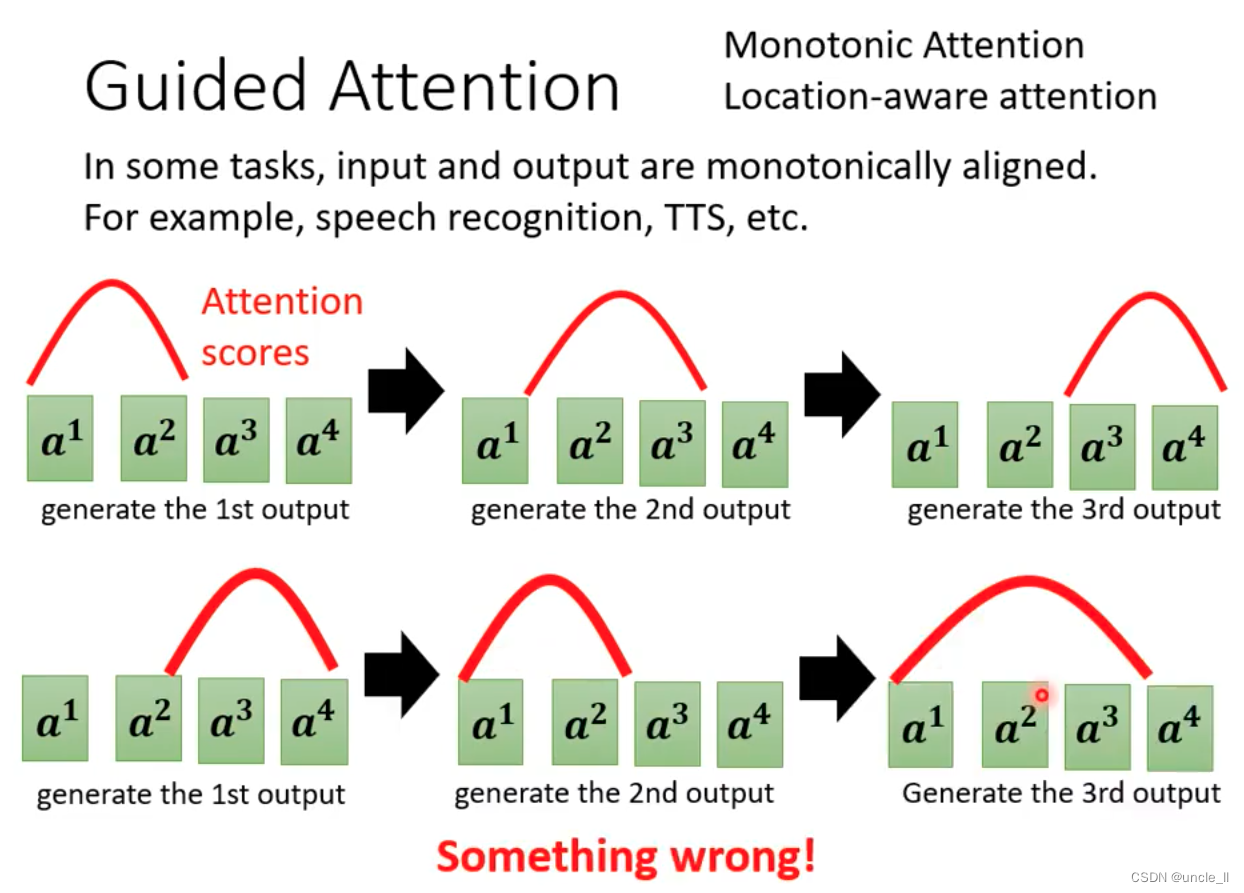
可以通过monotonic attention等方式避免上述这种问题。
Beam Search
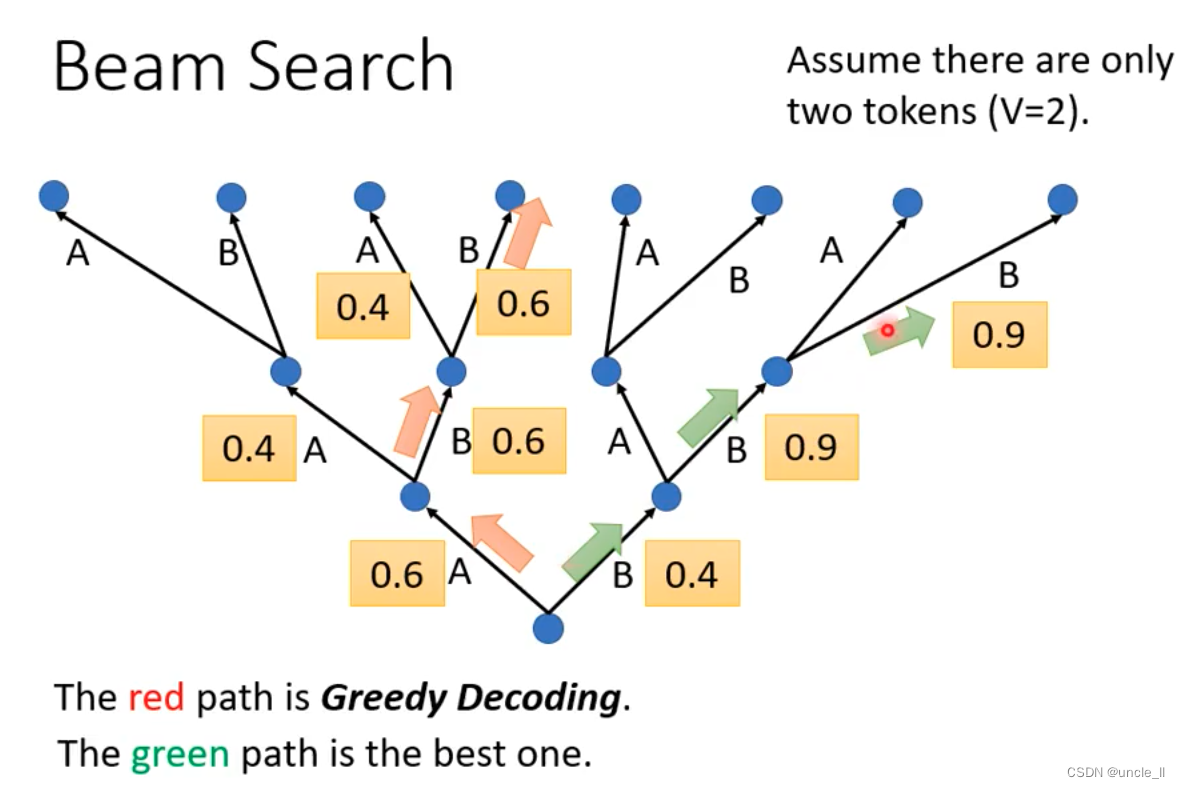
每次选最大的是贪心的方式,如红色所示;但是如果走绿色的是最优的方式。
可以用beam search方法找到一个不是完全精准的解决方法。

beam search有时候是有用的,有时候是无用的。可以加一些随机性在decoder里面。
tts的时候,decoder中加一点noise,可能效果会变好。模型训练好后,测试的时候也要加noise。
Accept that nothing is perfect, true beauty lies in the cracks of imperfection.
optimizing Evaluation Metrics
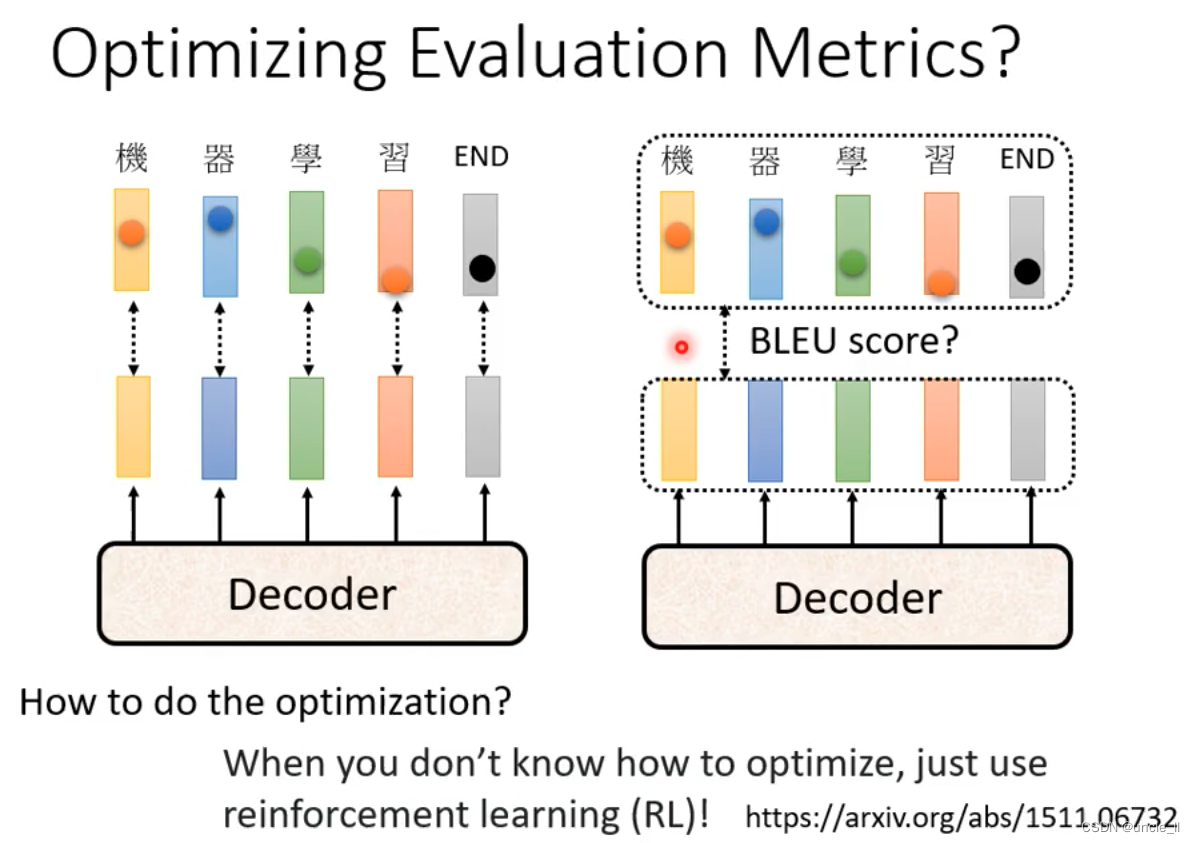
blue score不好计算,遇到无法优化的时候,使用reinforcement learning(RL)硬来训练。
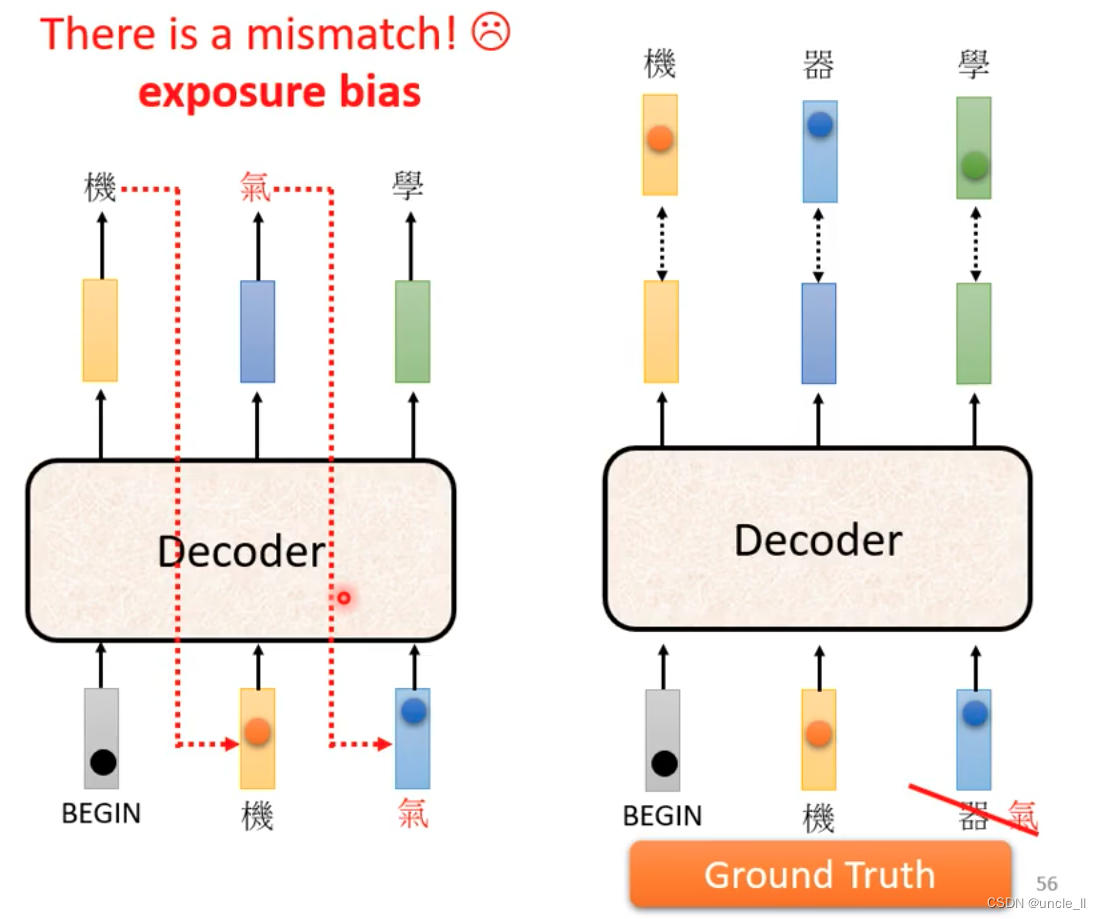
给一些错误的输入。