【IM】如何保证消息可用性(一)
目录
- 1. 基本概念
- 1.1 长连接 和 短连接
- 1.2 PUSH模式和PULL模式
- 2. 背景介绍
- 2.1 理解端到端的思想
- 3. 方案选型
- 3.1 技术挑战
- 3.2 技术目标
1. 基本概念
在讲解消息可用性之前,需要理解几个通信领域的基本概念。
1.1 长连接 和 短连接
-
什么是长连接,短连接?
在HTTP/1.0中,默认使用的是短连接。也就是说,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。如果客户端浏览器访问的某个HTML或其他类型的 Web页中包含有其他的Web资源,如JavaScript文件、图像文件、CSS文件等;当浏览器每遇到这样一个Web资源,就会建立一个HTTP会话。但从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头有加入这行代码:
Connection:keep-alive在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的 TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接要客户端和服务端都支持长连接。
HTTP协议的长连接和短连接,实质上是TCP协议的长连接和短连接
-
TCP的长连接和短连接
-
对于TCP短连接,一般由客户端发起三次握手,经过一次读写操作后,由客户端发起四次挥手,断开连接。短连接的优点在于管理起来比较简单,存在的连接都是有用的连接,不需要额外的控制手段
-
对于TCP长连接,简单来说,client向server发起连接,server接受client连接,双方建立连接。Client与server完成一次读写之后,它们之间的连接并不会主动关闭,后续的读写操作会继续使用这个连接。
连接本身是一种资源,连接建立后,server需要保存相关的状态信息,如果客户端已经关闭,此时的状态信息就白白占用了server的资源,因此需要保活功能的存在: 保活功能主要为服务器应用提供,服务器应用希望知道客户主机是否崩溃,从而可以代表客户使用资源。如果客户已经消失,使得服务器上保留一个半开放的连接,而服务器又在等待来自客户端的数据,则服务器将应远等待客户端的数据,保活功能就是试图在服务 器端检测到这种半开放的连接。
如果一个给定的连接在两小时内没有任何的动作,则服务器就向客户发一个探测报文段,客户主机必须处于以下4个状态之一:正常运行,已经崩溃,客户主机崩溃并已经重新启动,客户机正常运行但是服务器不可达(弱网环境)
-
-
长短连接的选择
根据之前的介绍,我们已经能感受到长短连接的优缺点。长连接通常用于收发频繁的场景,尤其是点对点通信,比如IM,数据库;而短连接通常用于请求不频繁的情况,比如一般的WEB网站,对于网页资源的请求一般不会十分频繁。 -
简单的TCP长连接服务器DEMO
TCP的保活机制保证了传输层的连接可用性,但是如何保证应用层的连接,需要我们做跟多的工作,之后会单独讲解。package mainimport ("log""net""time" )func main() {// 创建 TCP 连接conn, err := net.Dial("tcp", "127.0.0.1:80")if err != nil {log.Fatal("Failed to connect:", err)}defer conn.Close()// 将连接转换为 TCPConn 类型tcpConn, ok := conn.(*net.TCPConn)if !ok {log.Fatal("Failed to convert to TCPConn")}// 设置 KeepAlive,启用 TCP 连接的 KeepAlive 功能if err := tcpConn.SetKeepAlive(true); err != nil {log.Fatal("Failed to set KeepAlive:", err)}// 设置 KeepAlive 周期,每隔一段时间发送一个 KeepAlive 包if err := tcpConn.SetKeepAlivePeriod(10 * time.Second); err != nil {log.Fatal("Failed to set KeepAlive period:", err)}// 在这里进行其他操作,保持 TCP 连接处于活跃状态 }
1.2 PUSH模式和PULL模式
这个比较简单,可以理解为GIT里的push和pull.服务器主动向客户端发数据叫做push,客户端向客户端请求数据叫做pull
2. 背景介绍
在IM场景下,消息的可用性包含两个方面:可靠性和一致性,可以总结为:可达有序,不重不漏。
- 可靠性:消息一旦显示发送成功,则一定到达对端
- 一致性:任何时刻消息保证由于发送端的发送顺序一致
2.1 理解端到端的思想
在设计IM系统的时候,最重要的思想是 端到端思维:
端到端原则是一种分布式系统中各个模块之间功能定位的设计原理,指的是从代价和性能的角度出发,在网络的最核心的部分应该只去做数据的传输而不能去做一些其他的应用,而数据是否正确传输则应该放到应用层去检查和判断,从而保证互联网核心的简单性,可维护性,可拓展性。
简单的理解端到端思想,可以以数据传输的可靠性为例子,在网络中传输文件,传输错误可能发生在端到端路线的多个节点,也许我们可以通过在每一个交换节点上都加入数据校验,超时,重传的机制来保证数据正确,但是,实际上,可能错误可能发生在端系统的自身,比如磁盘存取错误,缓存不足。这样一来,即使中间节点提供了数据的可靠,端系统也没有任何工作量的减少,依然需要进行正确性的检测。 因此,在中间节点只需要提供其能完全实现的功能,即路由转发即可。
OSI七层模型也是端到端思想的产物,主机网络的每一层都是一个端系统,只对本层负责,保证本层数据可靠,不保证上层数据可靠。这样的设计使得每一层功能不重叠,结构清晰:
- 数据链路层(第二层)和物理层(第一层): 这两层负责将数据转换为比特流并通过物理介质传输。在端到端原则下,这些层不应对数据进行处理,而应只负责将数据从一个点传输到另一个点。
- 网络层(第三层): 数据在网络中进行路由和转发,以便从计算机 A 到计算机 B。在端到端原则下,网络层应该提供最佳的数据传输路径,但不对数据进行修改或过滤
- 传输层(第四层): 数据被传输到传输层,以便在计算机 A 和 B 之间进行可靠的数据传输。在端到端原则下,传输层负责数据的分段、重传和错误检测,以保证数据的完整性和可靠性
由此我们可以总结:底层可靠性仅能保证底层可靠,不对上层负责。传输层已经帮我们做到了数据的完整和可靠,但是并不能说它能保证应用层的可靠了。
那么TCP到底做到了哪一步,我们又需要做哪些工作呢?
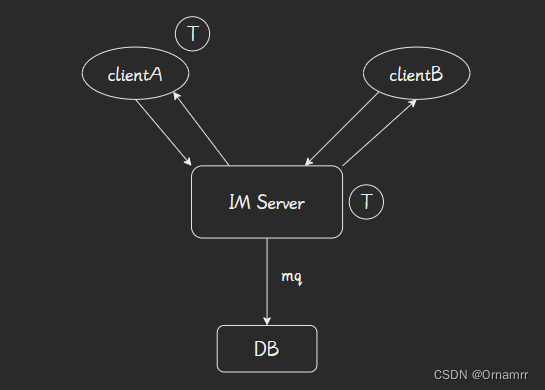
现在假设一个场景(应用层不做可用性处理):clientA发送msg1和msg2到server,两个消息通过一个长连接到达了服务端,此时可能会出现下面这些情况:
- msg1和msg2到达应用层,分别由一个线程去处理,msg2先落表成功,发送给clientB,造成数据乱序。
- msg1在server落盘失败,msg2成功,先发送给了clientB,造成数据丢失,乱序。
- 消息在由接入层到达业务层的时候,server进程崩溃,但是此时clientA认为已经送达,服务端业务无法感知,消息丢失。
因此对于IM这种三方通信来说,TCP/UDP的保证是远远不足够。
消息的端到端可用性 = 上行消息可用 + 服务端业务可用 + 下行消息可用
3. 方案选型
如何设计一个保证消息端到端可用性的协议是我们的本文的最重要任务。
3.1 技术挑战
- 三方通信,难以保证网络上的消息必达
- 没有全局时钟,那一确定唯一顺序,因果顺序
- 时钟零点漂移问题:时钟零点漂移通常指的是在计算机系统中时钟的偏移或漂移,这可能会导致时钟与实际时间之间存在误差。这种情况可能由多种因素引起,包括硬件时钟的不准确性、操作系统的时钟管理、系统负载等。
可行的解决方式有:- 使用网络时间协议(NTP): NTP 是一种用于同步计算机时钟的协议,可以从互联网上的时间服务器获取准确的时间信息,并调整本地时钟以匹配其时间。在大多数操作系统中,可以配置系统以自动与 NTP 服务器同步时间。
- 定期同步时间: 即使已启用自动同步时间功能,也建议定期手动同步一次时间,以确保时钟的准确性
- 减少系统负载: 高负载的系统可能会影响时钟同步的准确性。尽量减少系统的负载,特别是在进行时钟同步时
- 时钟零点漂移问题:时钟零点漂移通常指的是在计算机系统中时钟的偏移或漂移,这可能会导致时钟与实际时间之间存在误差。这种情况可能由多种因素引起,包括硬件时钟的不准确性、操作系统的时钟管理、系统负载等。
- 消息顺序性在多客户端,多服务端,多线程/协程下那一保持
3.2 技术目标
对消息可用性的进一步细化:
- 消息及时:实时接收,发送 (响应时间<=200ms,高峰期 <=1s)
- 消息可达:超时重试,ACK确认
- 消息幂等(每条消息只处理一次):分配seqId,服务端存储seqId
- 消息有序:seqId可比较,接收端可以按照发送端的顺序进行消息排序 (一个会话内保证消息有序即可)
在下一篇文章中,我们将探讨更加具体的实现方案。