机器学习 | 利用Pandas进入高级数据分析领域
目录
初识Pandas
Pandas数据结构
基本数据操作
DataFrame运算
文件读取与存储
高级数据处理
初识Pandas
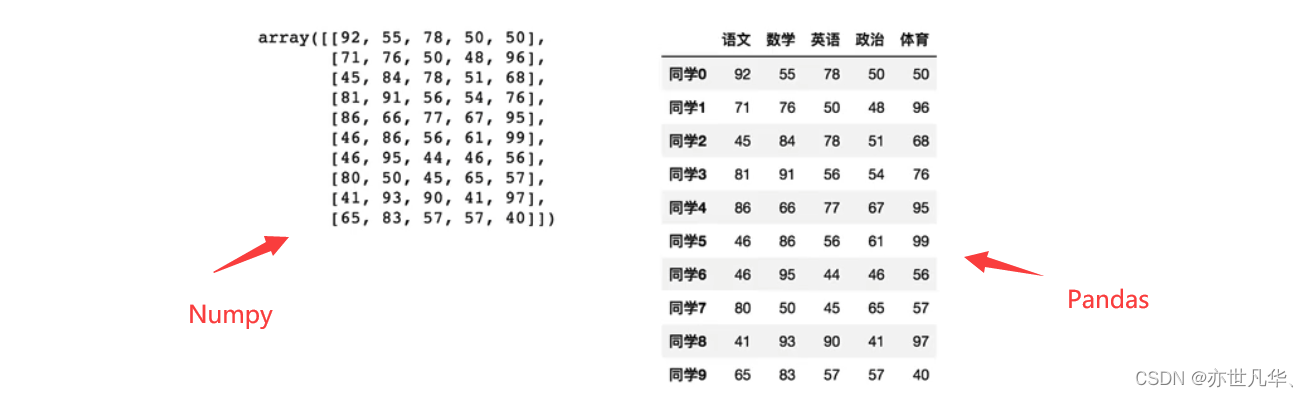
Pandas是2008年WesMcKinney开发出的库,专门用于数据挖掘的开源python库,以Numpy为基础,借力Numpy模块在计算方面性能高的优势,其基于matplotlib能够简便画图,具有独特的数据结构。
与Numpy相比,Pandas能够更好地理解数据和发现其关联性,增强图表的可读性:
具有丰富的数据清洗功能,可以处理缺失值、重复值、异常值等问题。
当然其还有如下的功能:
数据处理:可以轻松处理各种类型的数据,包括二维表格数据、时间序列数据等。
数据分析:可以轻松地计算均值、中位数、标准差等统计指标。
与其他工具的兼容性:可以使用Pandas读取和写入各种数据格式,如CSV、SQL数据库等。
总之,Pandas是一款功能强大且易于使用的数据分析工具,能够让你高效地处理和分析结构化数据。通过利用Pandas的各种功能,你可以更快地了解数据、发现洞察,并做出有意义的数据驱动决策。
Pandas数据结构
Pandas中一共有三种数据结构,分别为:Series、DataFrame和Multilndex(老版本中叫Panel),其中Series是一维数据结构,DataFrame是二维的表格型数据结构,Multilndex是三维的数据结构。如果电脑没有pandas这个包的话,我们首先终端执行如下命令进行安装:
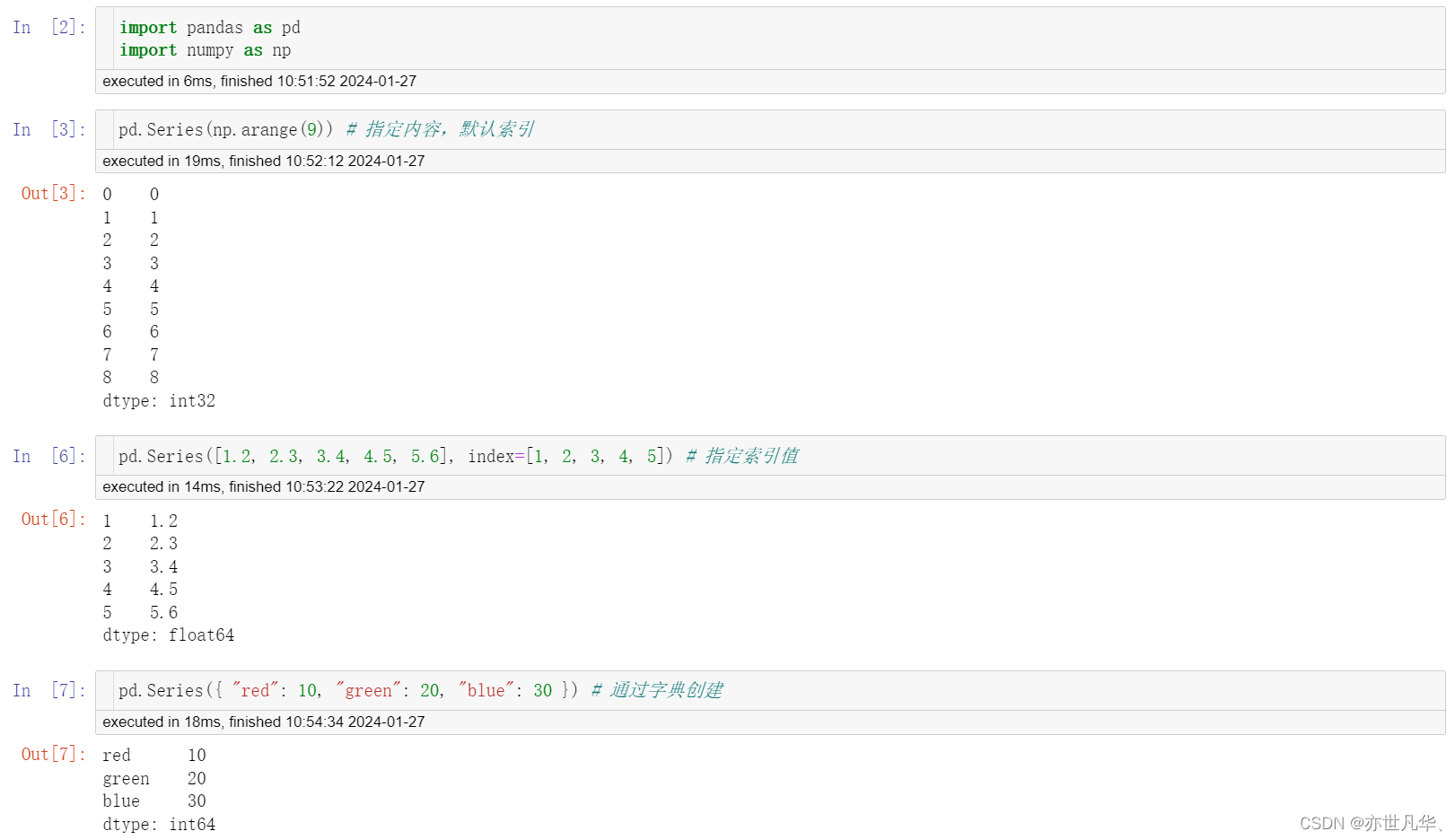
pip install pandas -i https://pypi.mirrors.ustc.edu.cn/simpleSeries:Series是一个类似于一维数组的数据结构,它能够保存任何类型的数据,比如整数、字符串、浮点数等,主要由一组数据和与之相关的索引两部分构成。其代码创建如下:
# 导入 pandas
import pandas as pd# data:传入的数据,可以是ndarray,list等
# index:索引,必须是唯一的,且与数据的长度相等。
# dtype:数据的类型
pd.Series(data=None, index=None, dtype=None)以下是通过Series创建的三种方式:
为了更方便地操作Series对象中的索引和数据,Series中提供了两个属性index和values
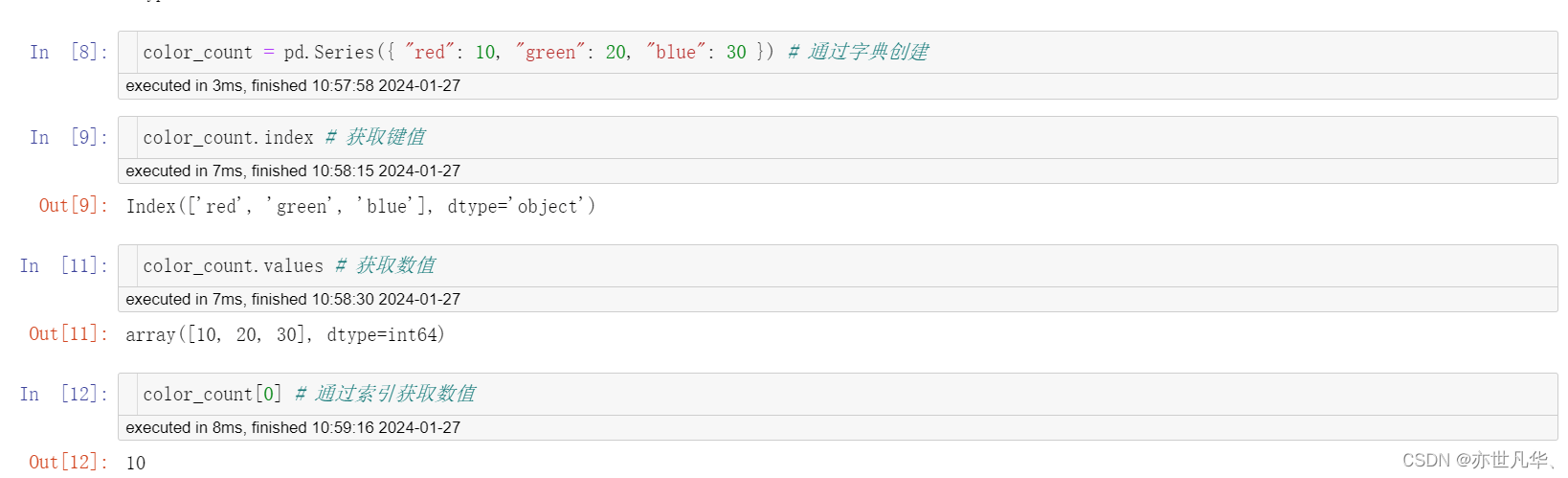
DataFrame:DataFrame是一个类似于二维数组或表格(如excel)的对象,既有行索引,又有列索引。行索引,表明不同行,横向索引,叫index,0轴,axis=0;列索引,表名不同列,纵向索引,叫columns,1轴,axis=1。其代码创建如下:
# 导入pandas
import pandas as pd# index:行标签。如果没有传入索引参数,则默认会自动创建一个从o-N的整数索引。
# columns:列标签。如果没有传入索引参数,则默认会自动创建一个从o-N的整数索引。
pd.DataFrame(data=None, index=None, columns=None)以下是通过DataFrame创建的方式:
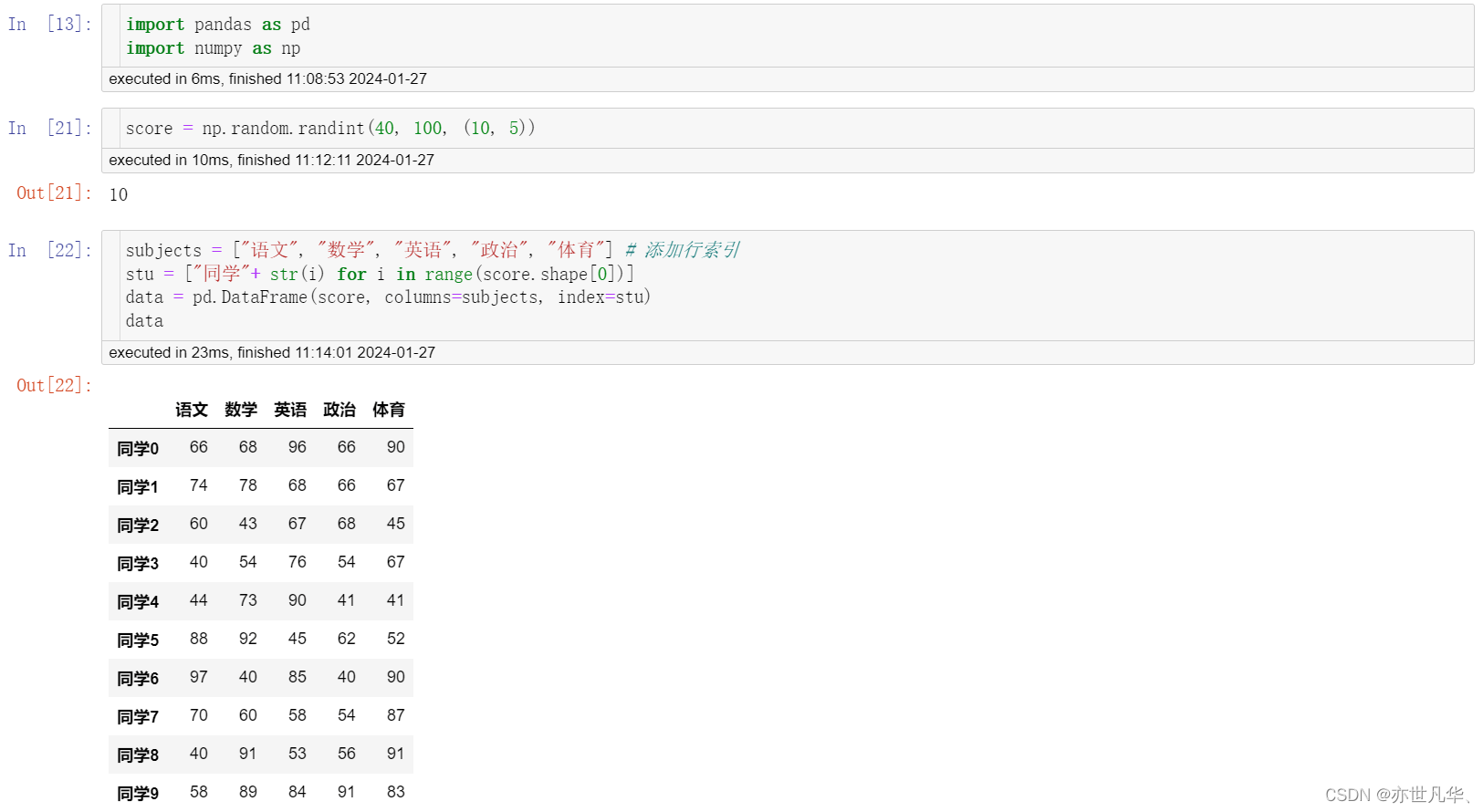
为了更方便地操作DataFrame对象中的数据,DataFrame中提供了如下属性进行操作:

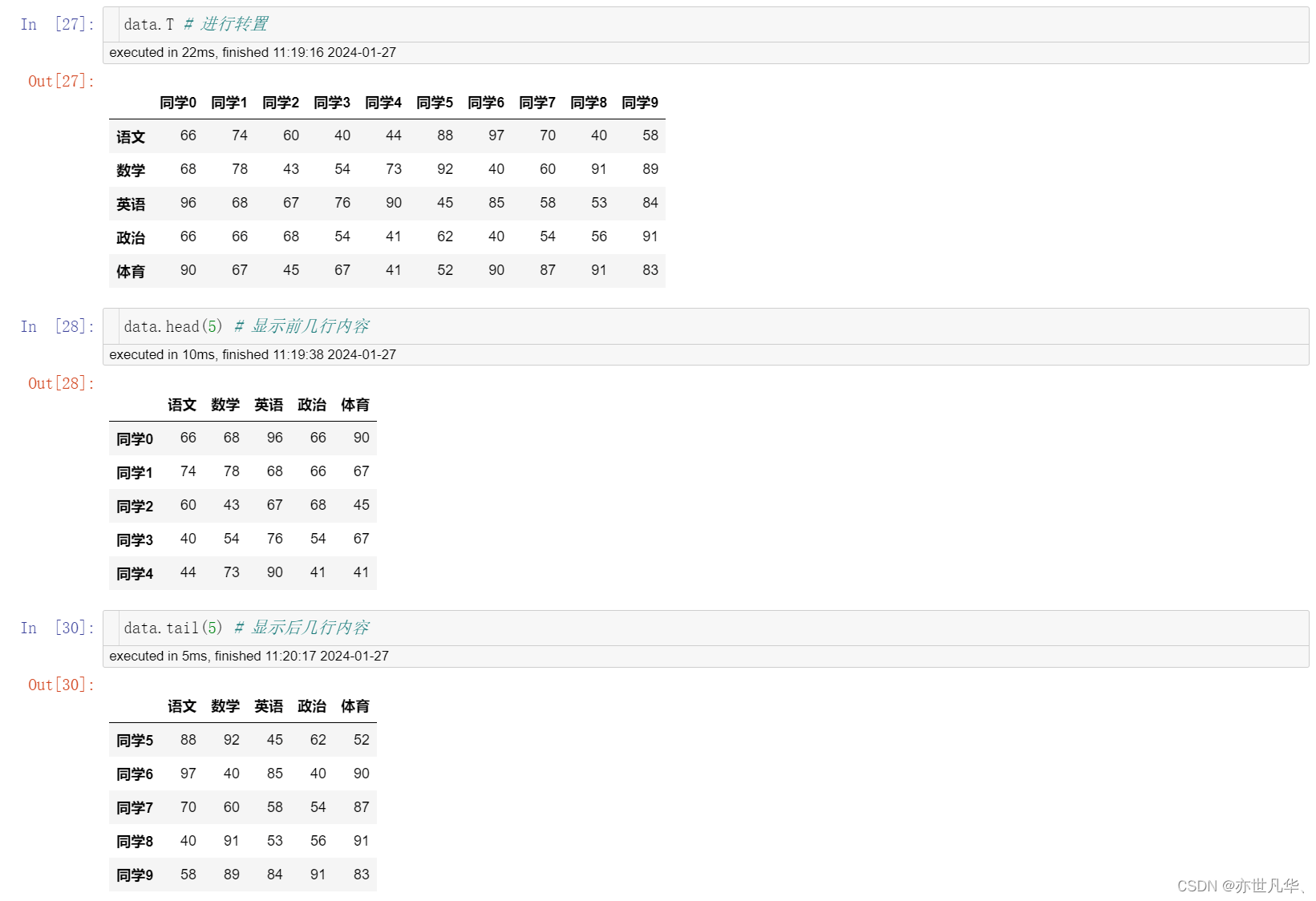
如果想对DataFrame索引的内容进行修改的话可以采用如下的方式进行设置(不能单个索引修改):

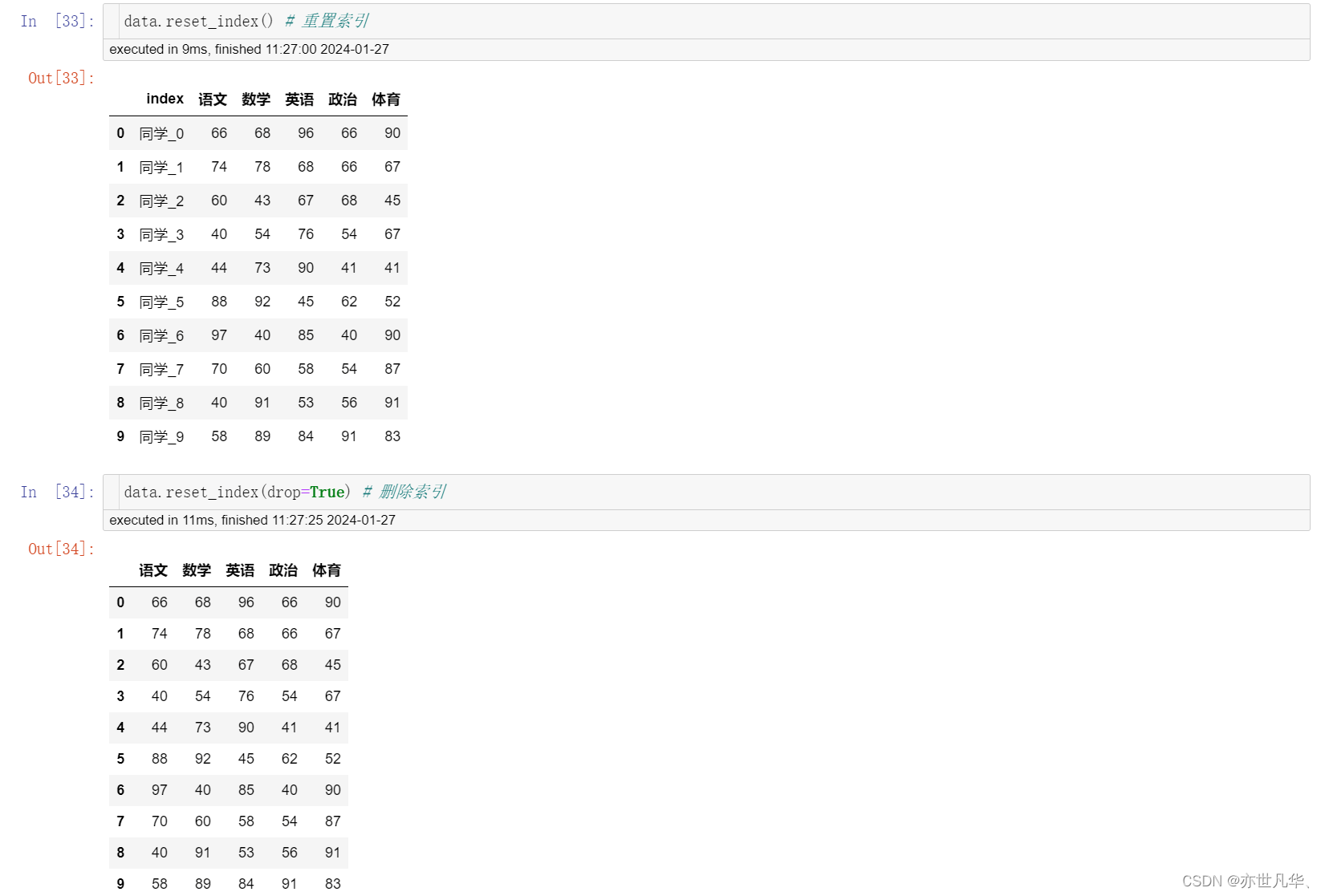
如果想重置或删除索引的话,可以采用如下的方式进行:
如果想以某列值设置为新的索引,可以采用如下的方式进行:

Multilndex:是三维的数据结构;多级索引(也称层次化索引)是pandas的重要功能,可以在Series、DataFrame对象上拥有2个以及2个以上的索引。
当我们打印上面的年月表格的行索引结果时,给出的结果如下:
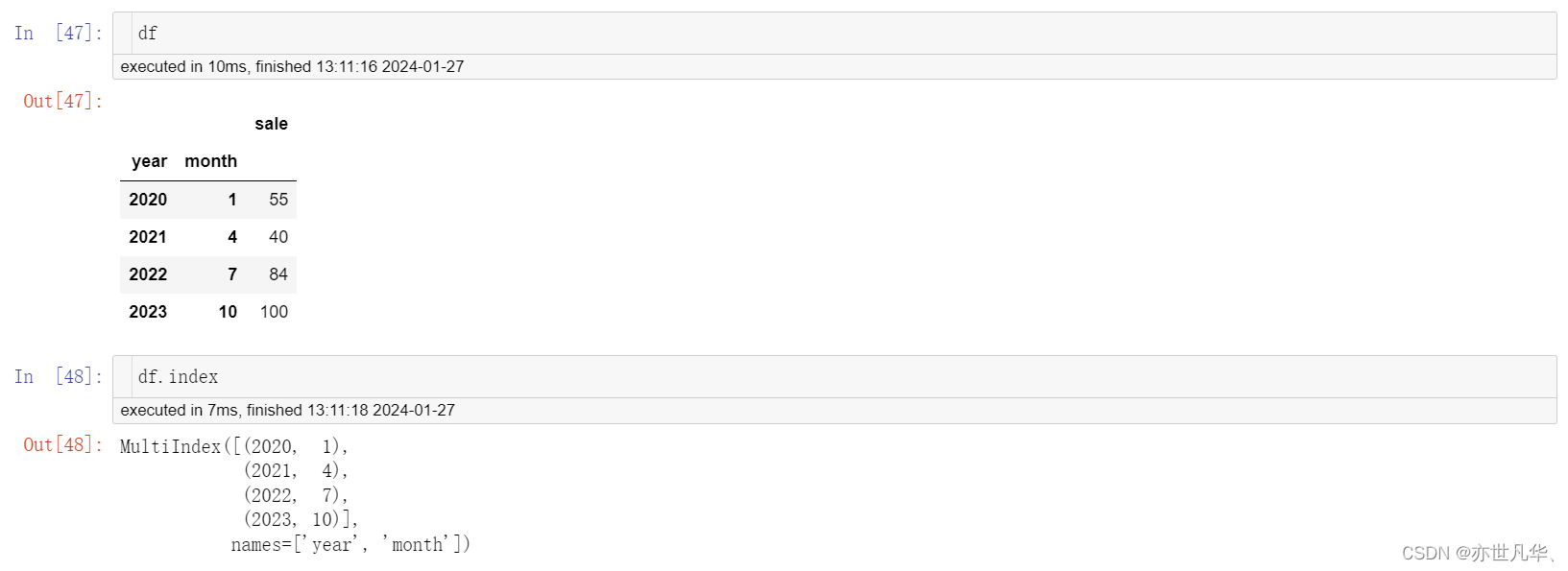
多级或分层索引对象中index的属性有names表示levels的名称,levels表示每个levels的元组值:

使用MultiIndex进行创建的方式如下:

基本数据操作
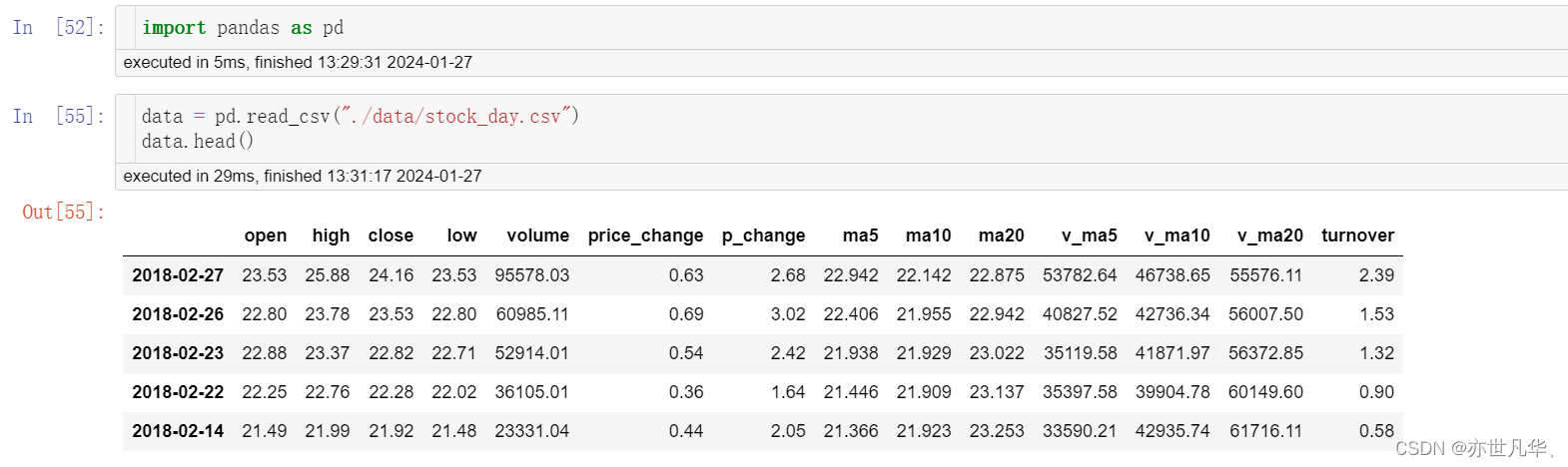
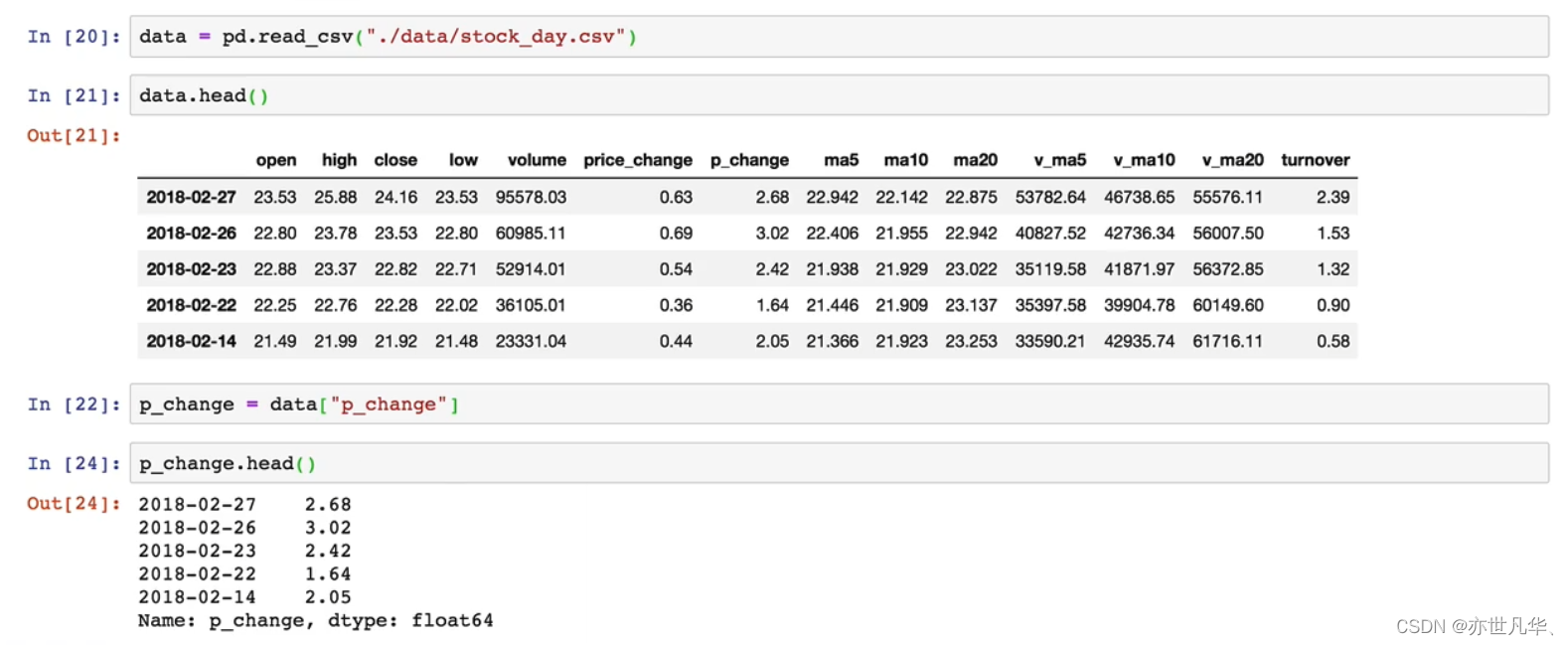
以下是使用pandas对数据进行基本的操作,我们首先通过pandas读取csv获取到数据,然后操作:
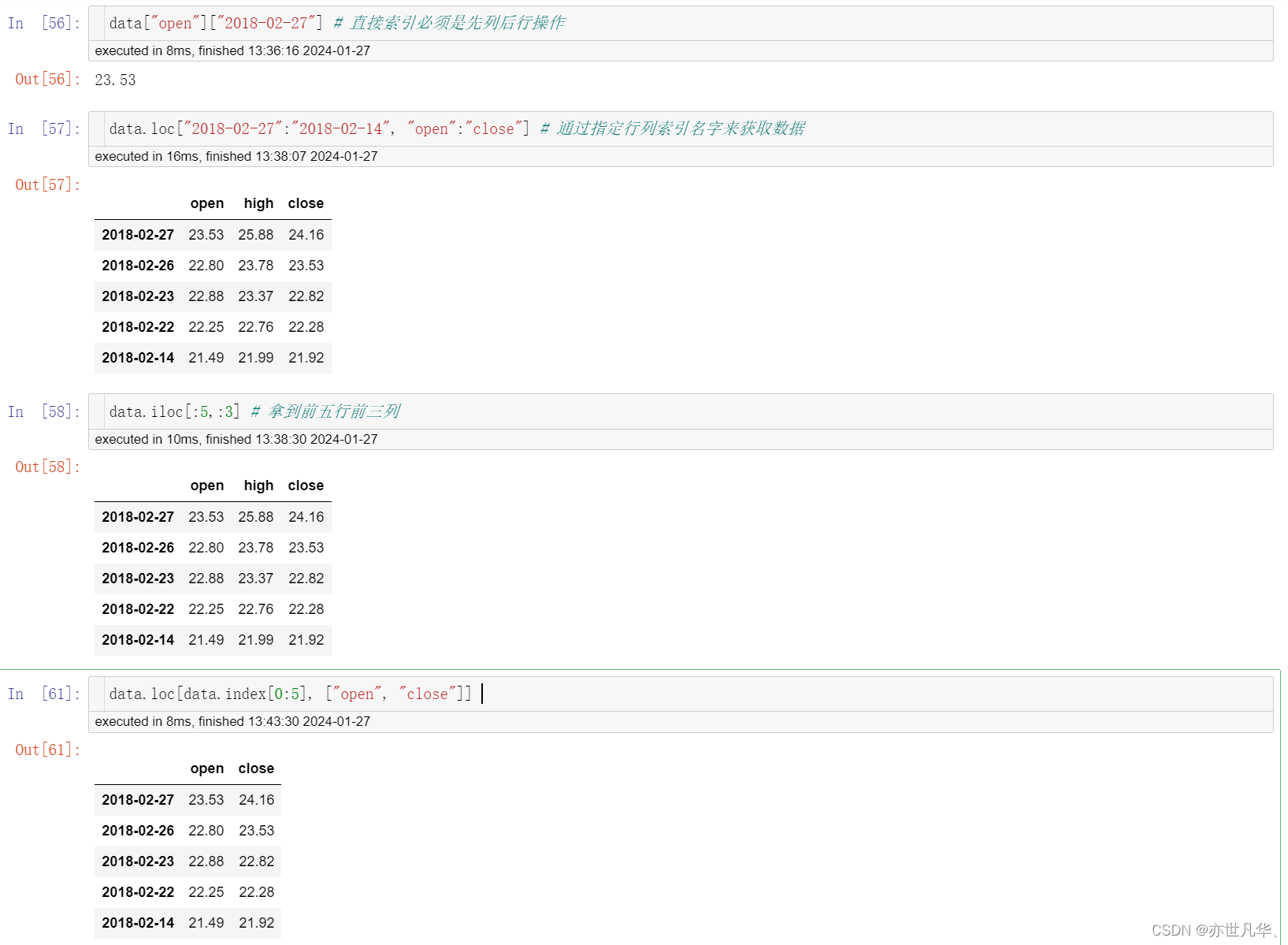
索引操作:pandas支持索引选取序列和切片操作,也可以直接使用列名和行名:
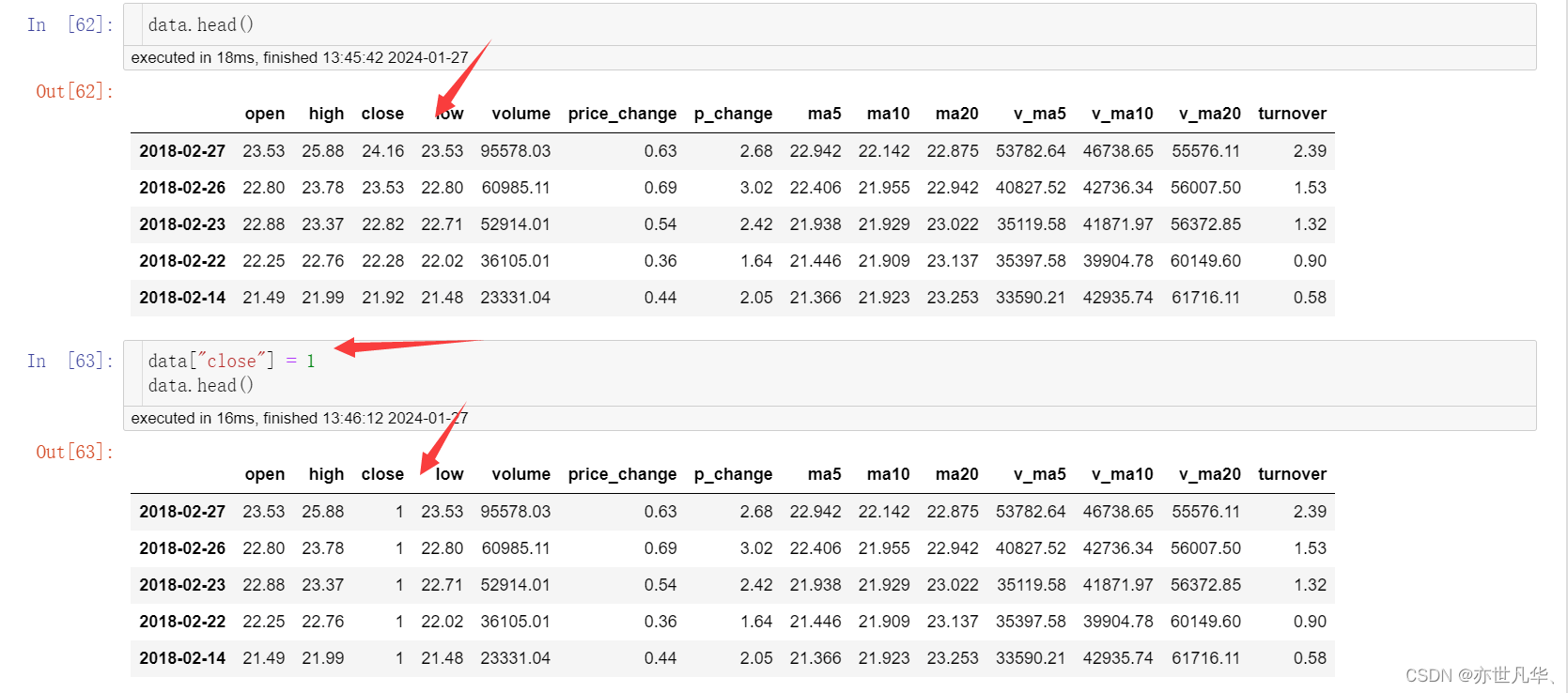
赋值操作:可以直接对某项数据进行赋值操作:
排序操作:使用排序操作可以采用如下的方式进行
当然还有更简单的Series排序,使用 Series 排序时,只有一列不需要参数:
DataFrame运算
算术运算:可以采用如下方式
逻辑运算:可以采用如下方式
当然我们也可以采用相应的函数进行操作:
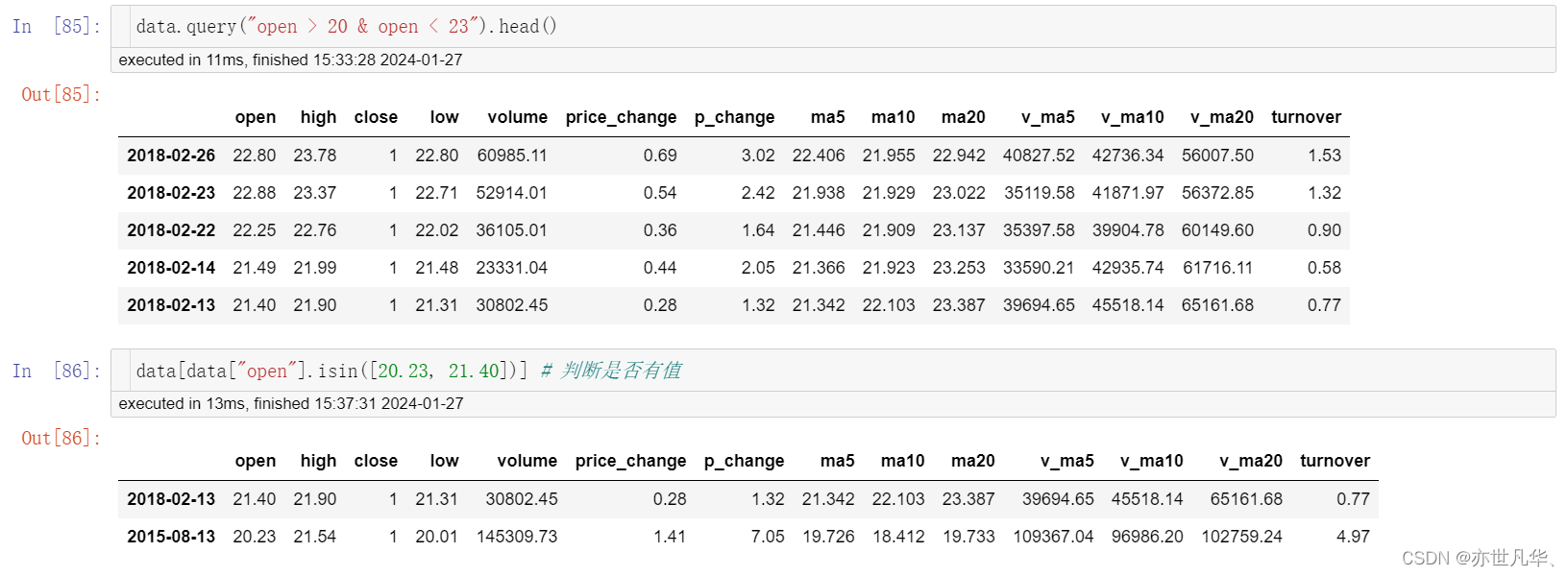
统计运算:可以采用如下方式
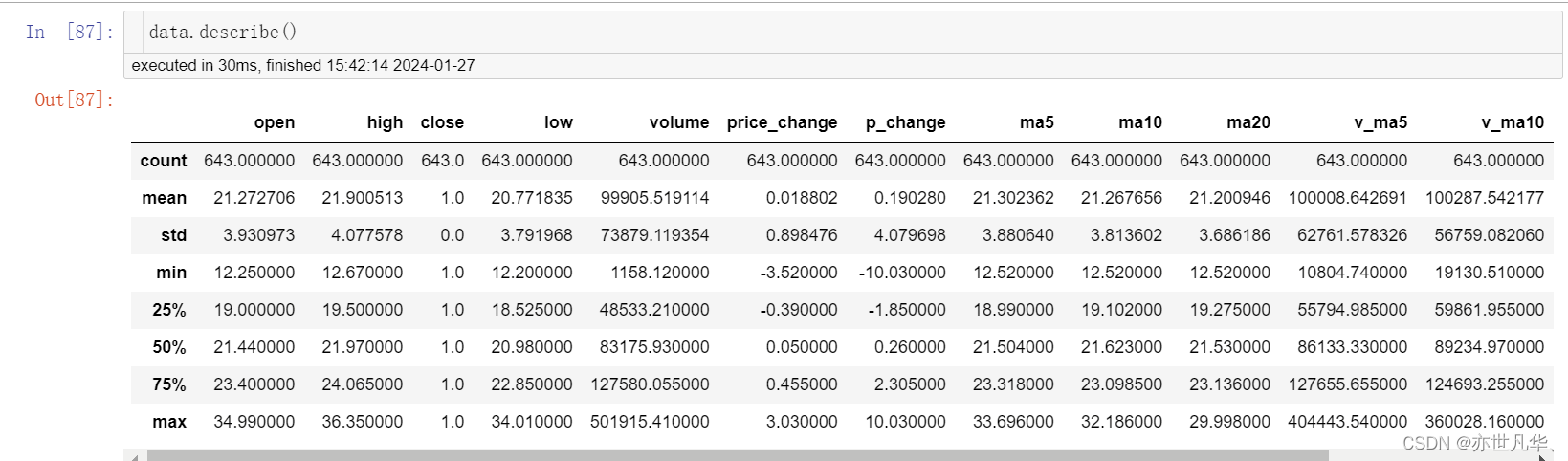
综合分析直接得出所有字段的统计结果:
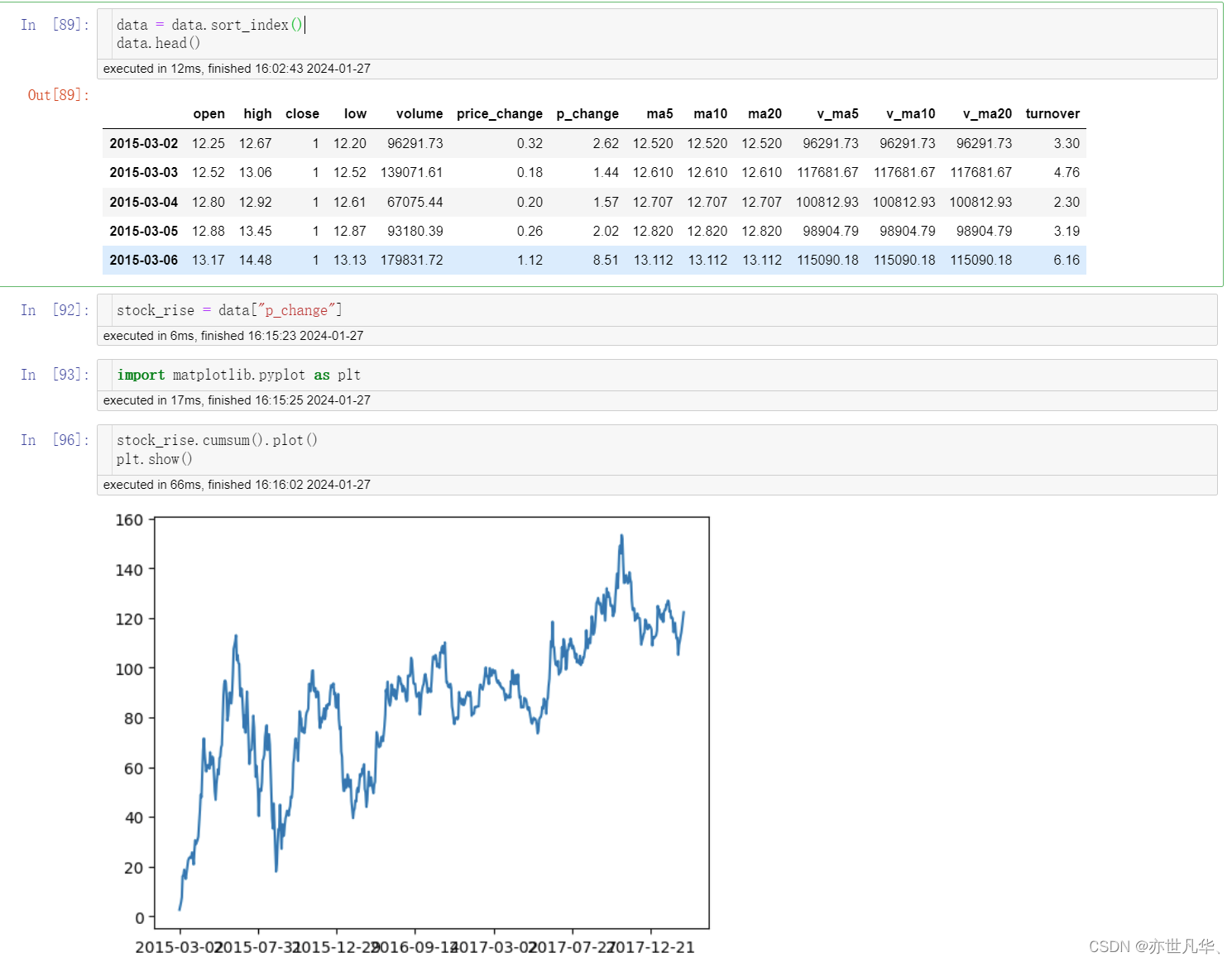
如果想求某一字段的累计求和的话,可以采用如下的方式进行:
如果想自定义运算的话,可以采用如下的方式进行:

文件读取与存储
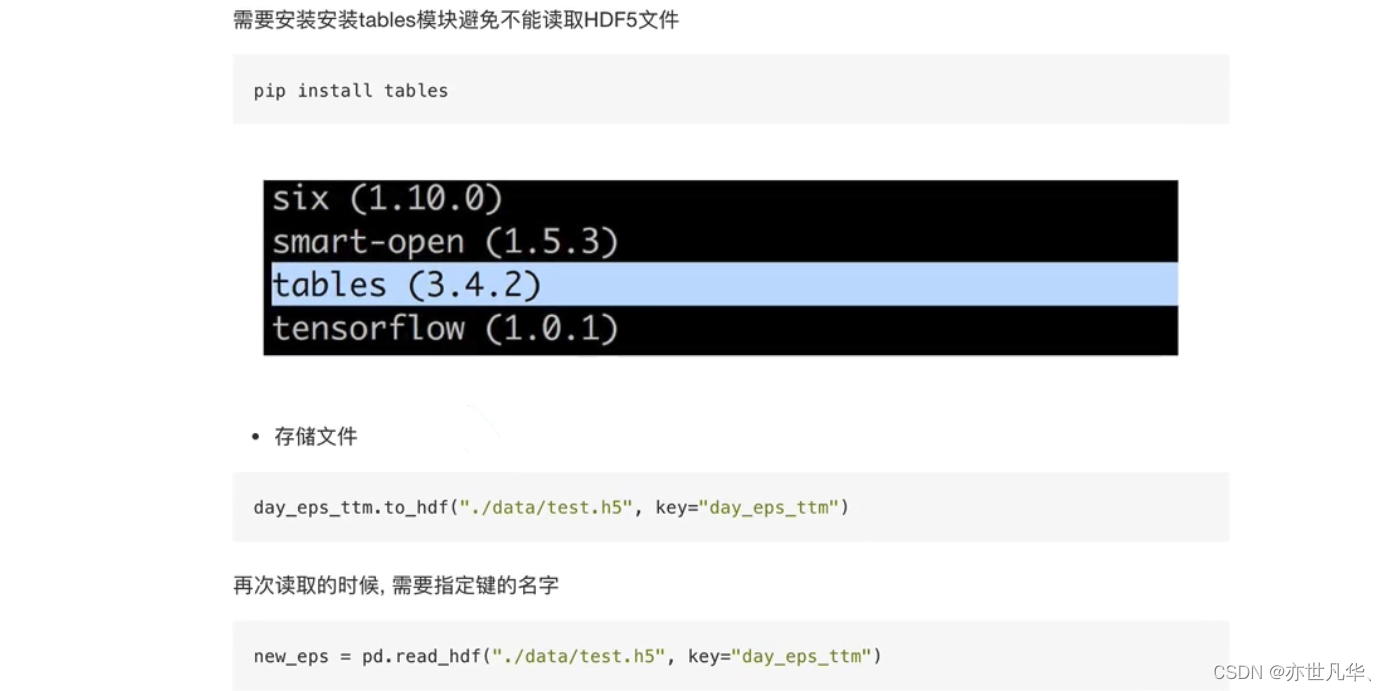
我们的数据大部分存在于文件当中,所以pandas会支持复杂的iO操作,pandas的API支持众多的文件格式如CSV、SQL、XLS、JSON、HDF5。最常用的就是HDF5和CSV文件:

如果要读取 CSV 可以采用如下的方式:



如果要读取 HDF5 可以采用如下的方式:

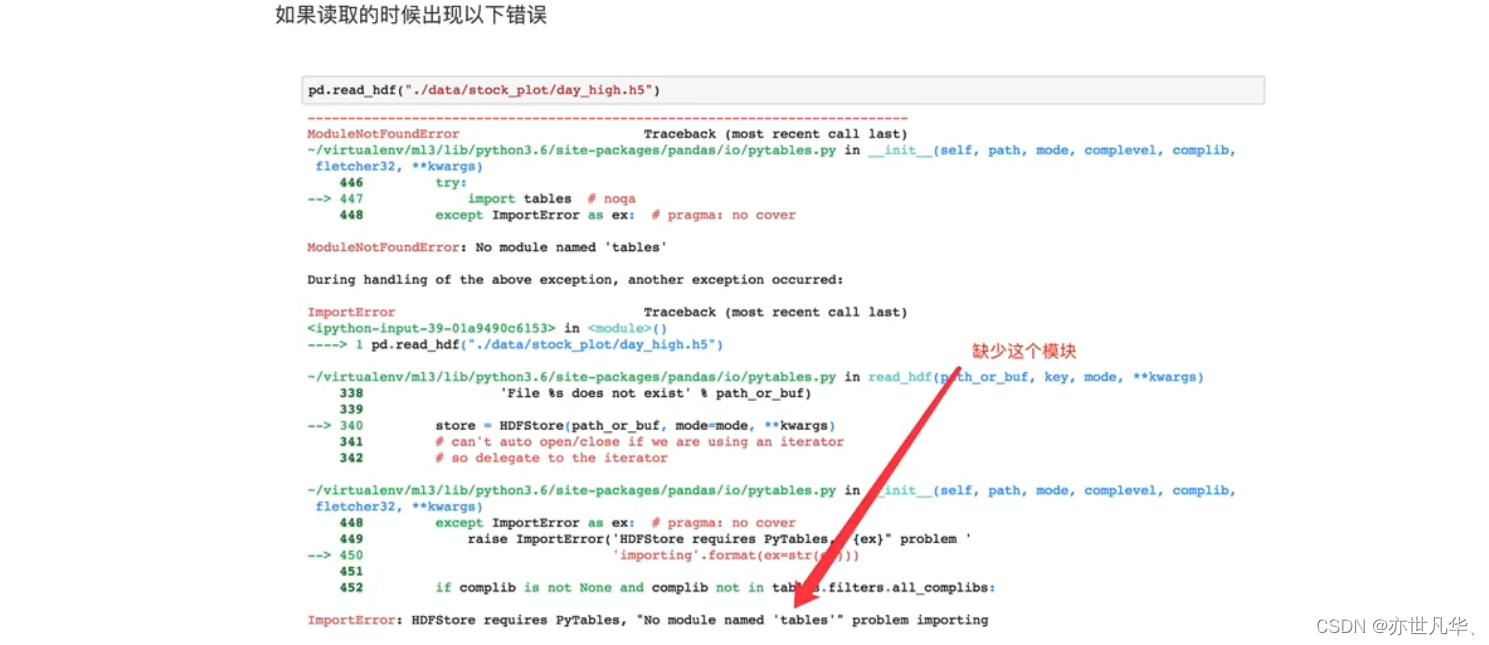
注意:
1)HDF5在存储的时候支持压缩,使用的方式是blosc,这个是速度最快的也是pandas默认支持的
2)用压缩可以提磁盘利用率,节省空间
3)HDF5还是跨平台的,可以轻松迁移到hadoop上面
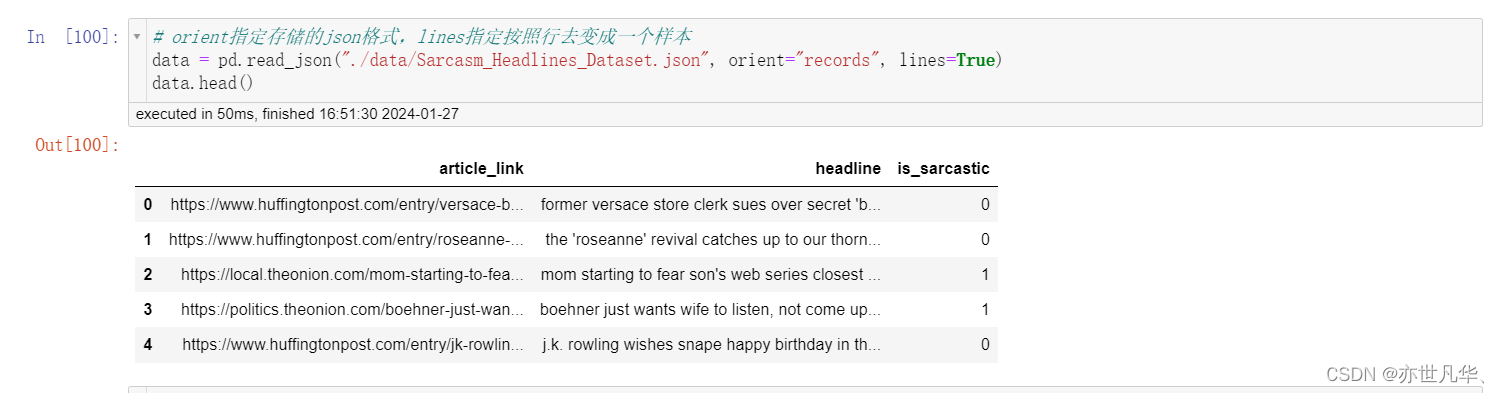
如果要读取 JSON 可以采用如下的方式:

高级数据处理
pandas还有需要高级数据处理的操作,就以下几个常用的高级数据操作进行讲解:
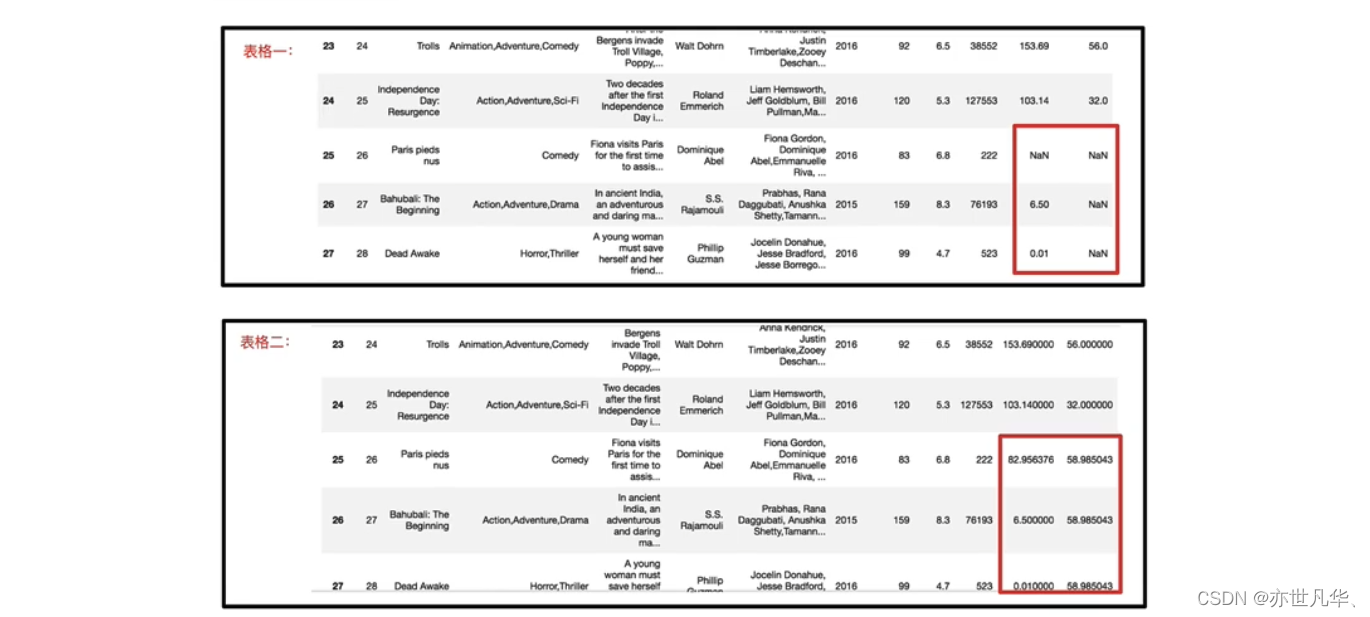
缺失值处理:在Pandas中,缺失值表示数据集中的空值或未知值。它们通常由NaN(Not a Number)或None表示,具体取决于数据类型。缺失值可能是由于多种原因造成的,比如数据采集过程中的错误、数据转换过程中的问题、用户未提供某些值等。在数据分析和处理过程中,了解和处理缺失值是非常重要的。如何处理缺失值呢?

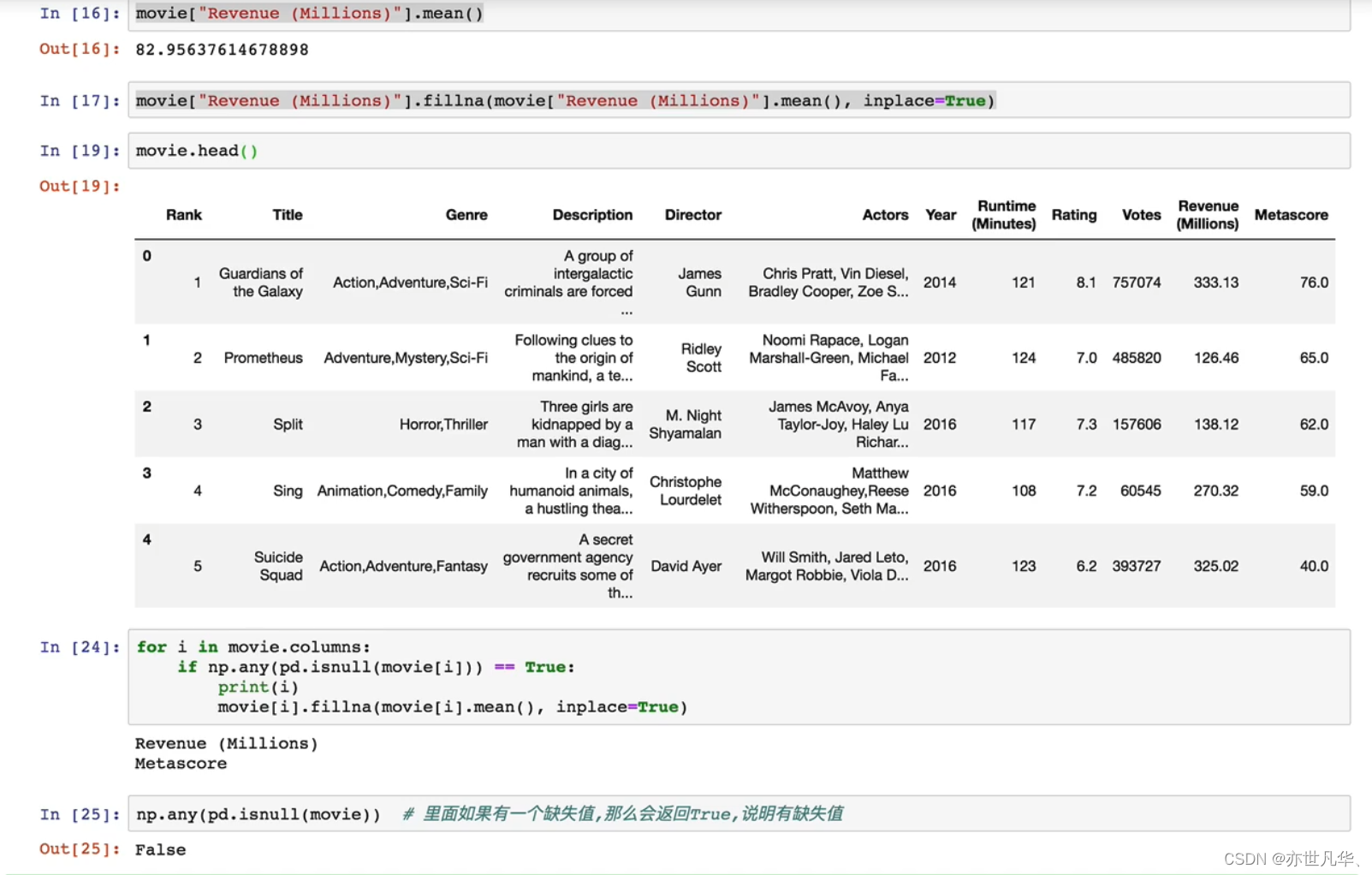
首先我们先导入一个电脑数据的分析的案例:

接下来我们对缺失值进行判断,如果存在缺失值进行删除:

接下来我们对缺失值进行判断,如果存在缺失值进行替换:
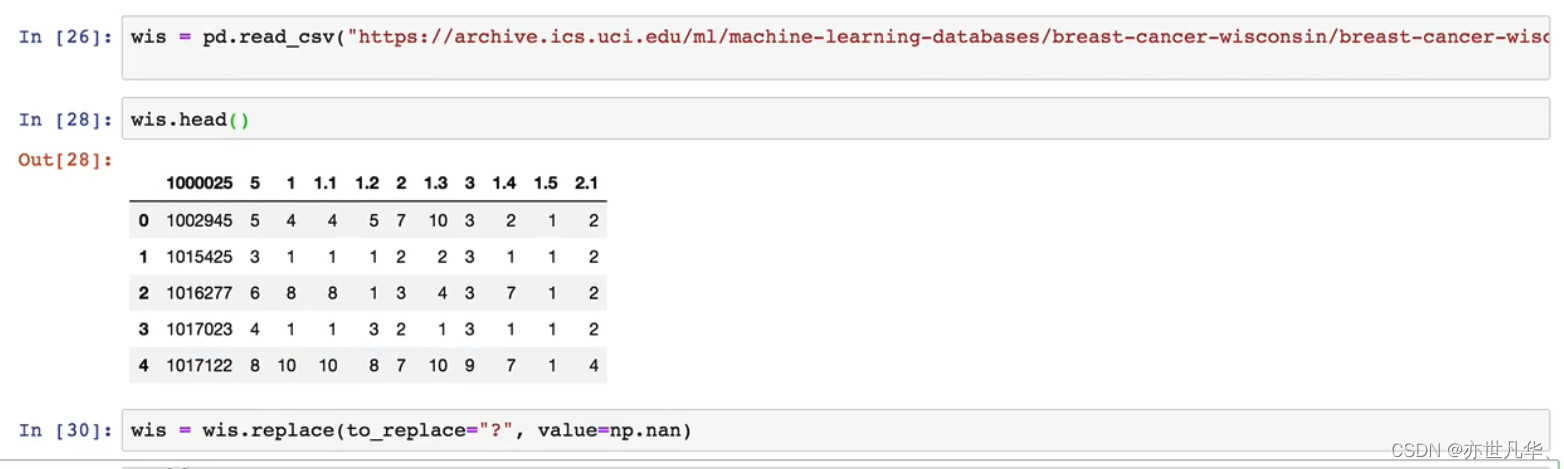
如果缺失值不是NaN而是?的话,我们可以进行如下操作:

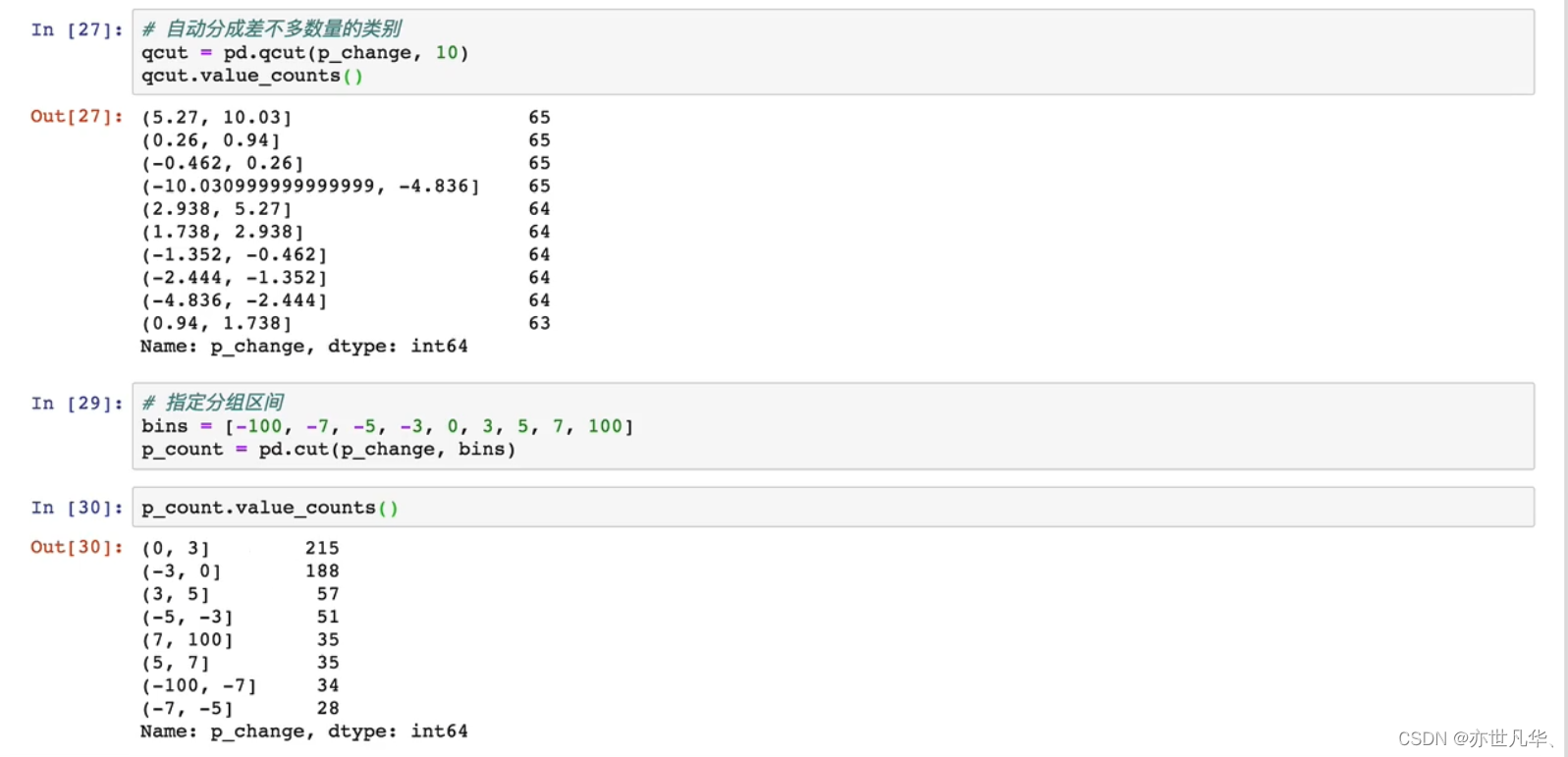
数据离散化:连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数值代表落在每个子区间中的属性值。离散化有很多种方法,这使用一种最简单的方式去操作:
原始人的身高数据:165,174,160,180,159,163,192,184
假设按照身高分几个区间段:150~165,165~180,180~195
这样我们将数据分到了三个区间段,我可以对应的标记为矮、中、高三个类别,最终要处理成一个"哑变量"矩阵
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具。首先我们先导入数据:
接下来对数据进行一个分组操作:
如果我们想把分组数据变成one-hot编码的话可以采用如下操作(把每个类别生成一个布尔列,这些列中只有一列可以为这个样本取值为1.其又被称为热编码):

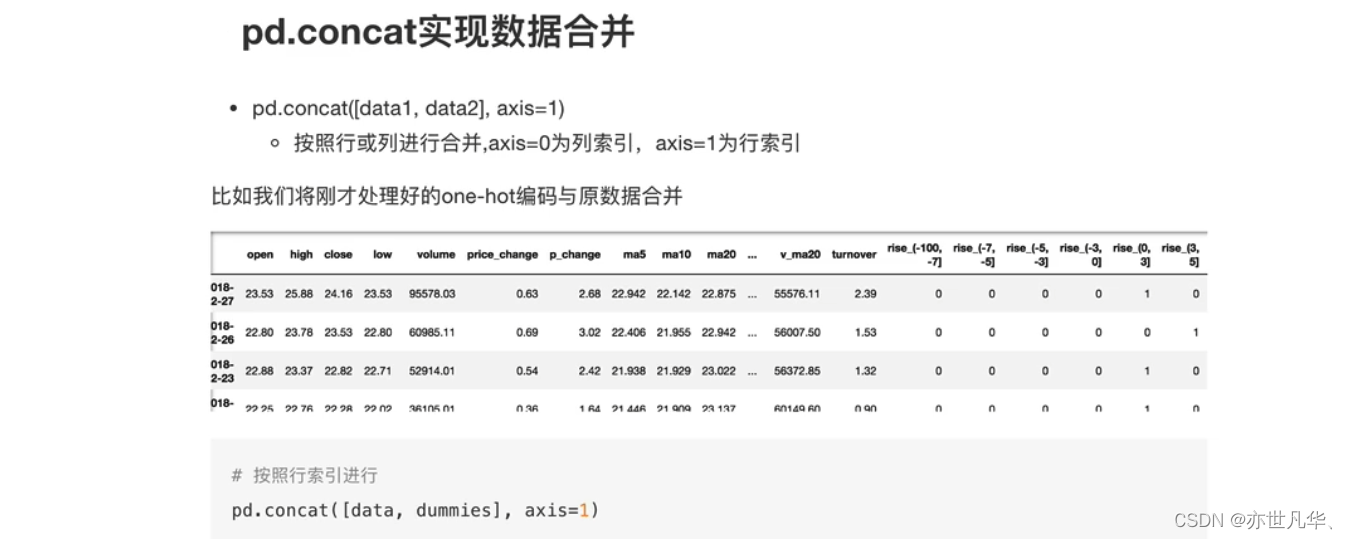
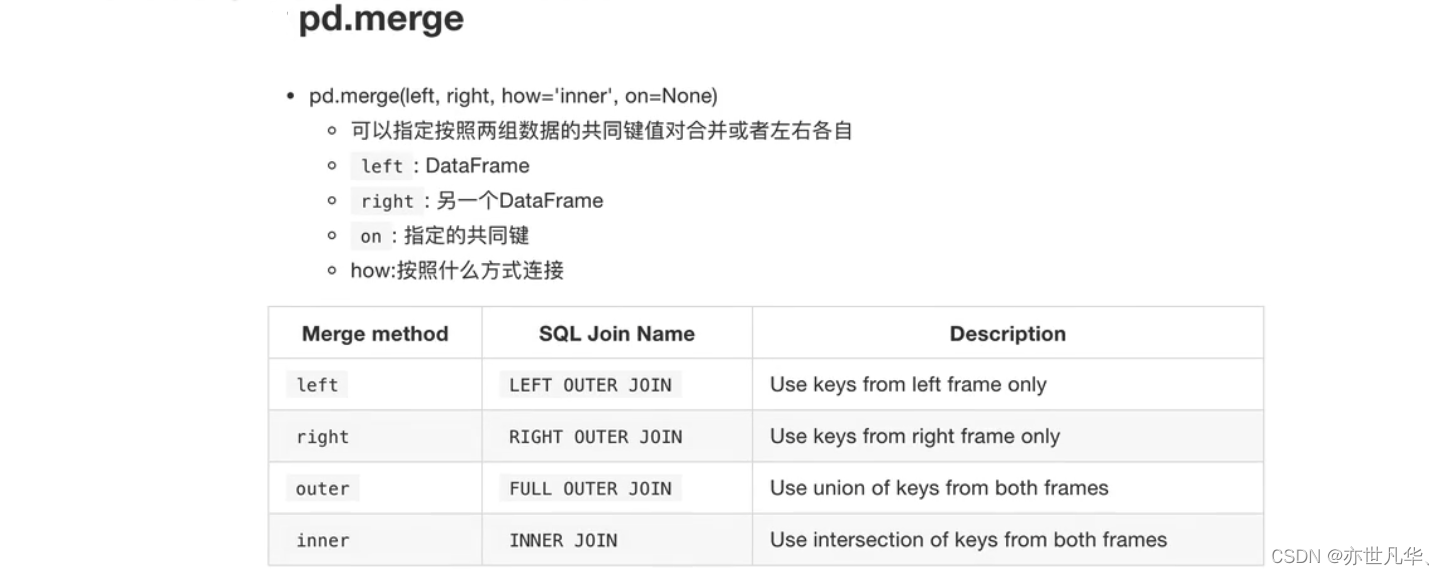
数据合并:如果你的数据由多张表组成,那么有时候需要将不同的内容合并在一起分析:
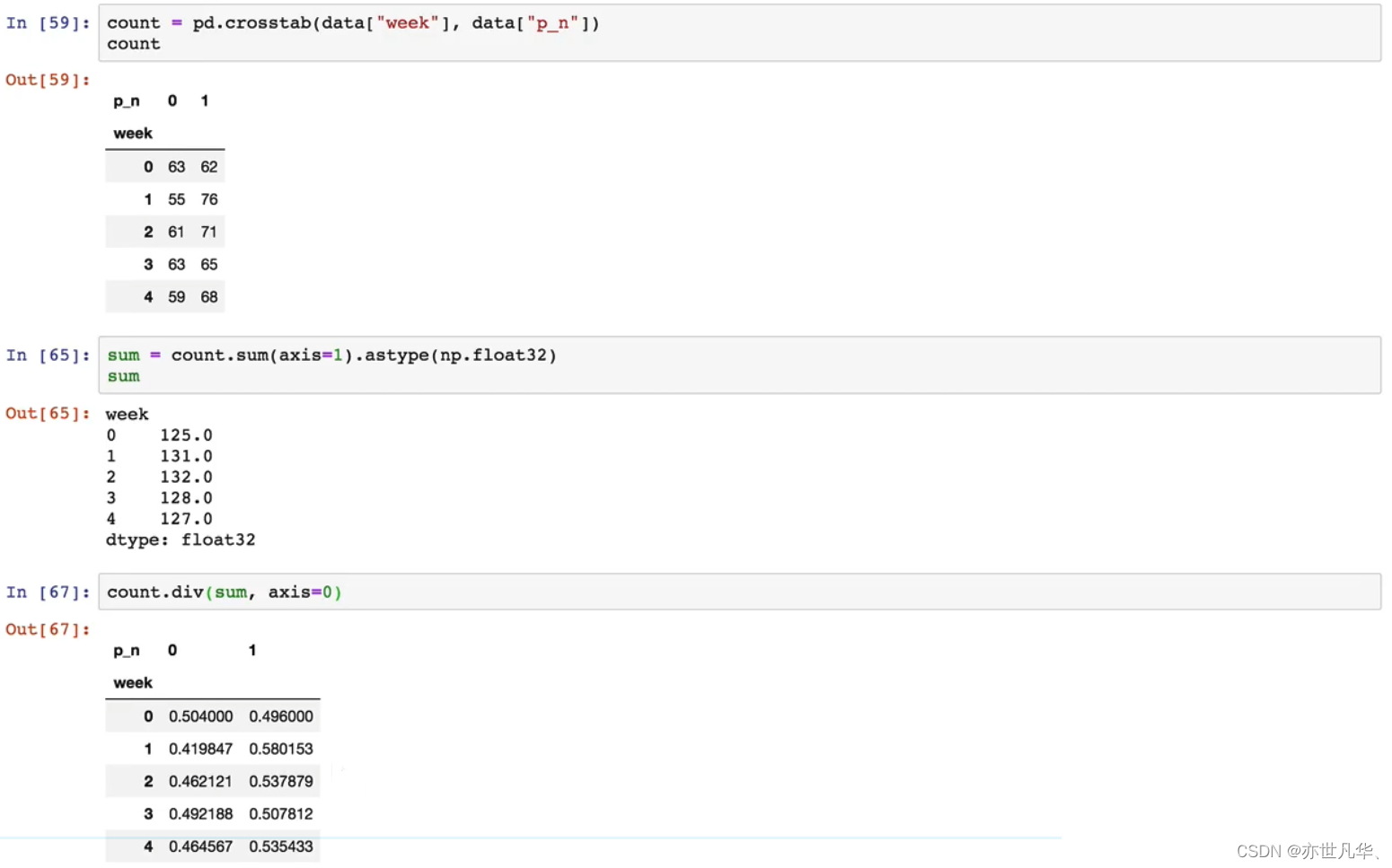
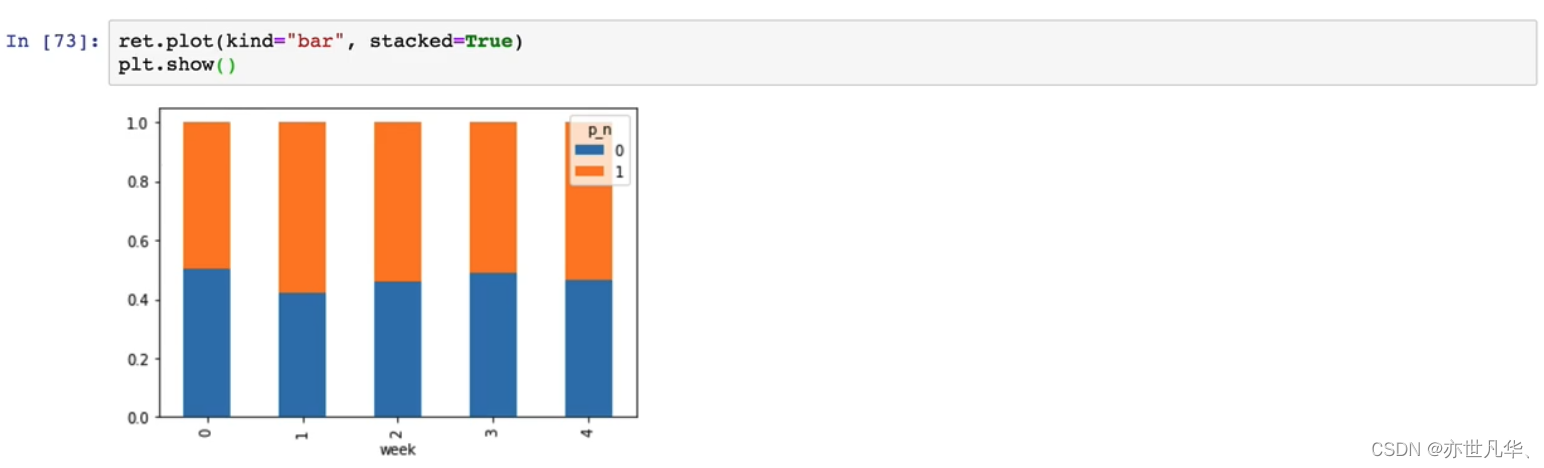
交叉表与透视表:两种用于数据分析和汇总的功能

其使用操作如下:


具体操作如下:
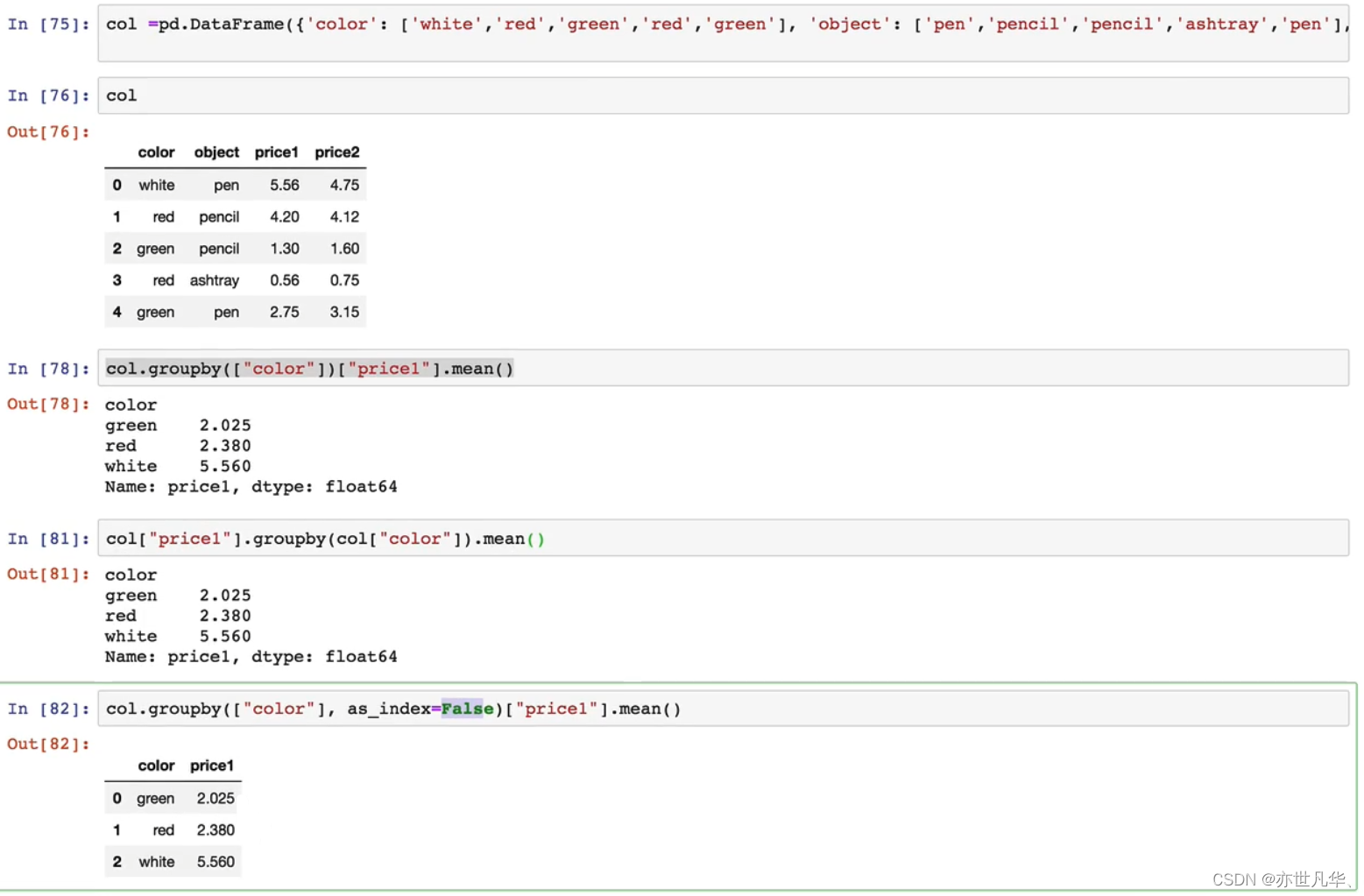
分组与聚合:分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况。其具体操作如下: